 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship between Bayesian Networks and Probabilistic Structural Causal Models
Mar 28, 2026In this paper, the relationship between probabilistic graphical models, in particular Bayesian networks, and causal diagrams, also called structural causal models, is studied. Structural causal models are deterministic models, based on structural equations or functions, that can be provided with uncertainty by adding independent, unobserved random variables to the models, equipped with probability distributions. One question that arises is whether a Bayesian network that has obtained from expert knowledge or learnt from data can be mapped to a probabilistic structural causal model, and whether or not this has consequences for the network structure and probability distribution. We show that linear algebra and linear programming offer key methods for the transformation, and examine properties for the existence and uniqueness of solutions based on dimensions of the probabilistic structural model. Finally, we examine in what way the semantics of the models is affected by this transformation. Keywords: Causality, probabilistic structural causal models, Bayesian networks, linear algebra, experimental software.
FederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
Mar 17, 2026Federated Learning (FL) enables distributed optimization without compromising data sovereignty. Yet, where local label distributions are mutually exclusive, standard weight aggregation fails due to conflicting optimization trajectories. Often, FL methods rely on pretrained foundation models, introducing unrealistic assumptions. We introduce FederatedFactory, a zero-dependency framework that inverts the unit of federation from discriminative parameters to generative priors. By exchanging generative modules in a single communication round, our architecture supports ex nihilo synthesis of universally class balanced datasets, eliminating gradient conflict and external prior bias entirely. Evaluations across diverse medical imagery benchmarks, including MedMNIST and ISIC2019, demonstrate that our approach recovers centralized upper-bound performance. Under pathological heterogeneity, it lifts baseline accuracy from a collapsed 11.36% to 90.57% on CIFAR-10 and restores ISIC2019 AUROC to 90.57%. Additionally, this framework facilitates exact modular unlearning through the deterministic deletion of specific generative modules.
Expert-Guided POMDP Learning for Data-Efficient Modeling in Healthcare
Nov 18, 2025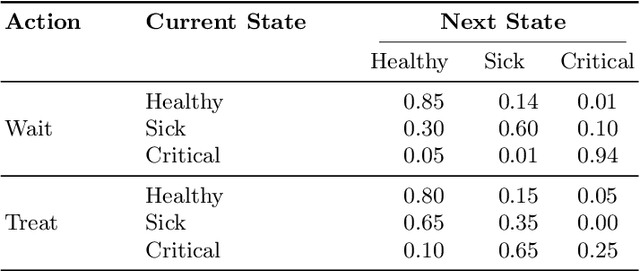
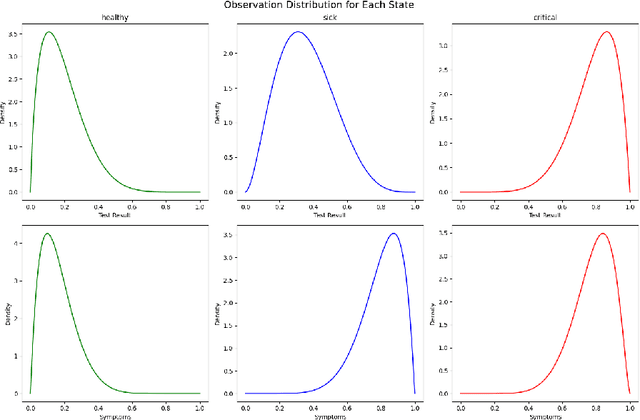
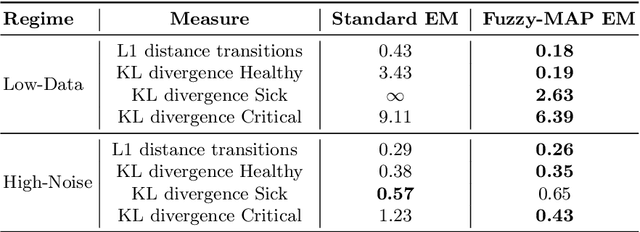
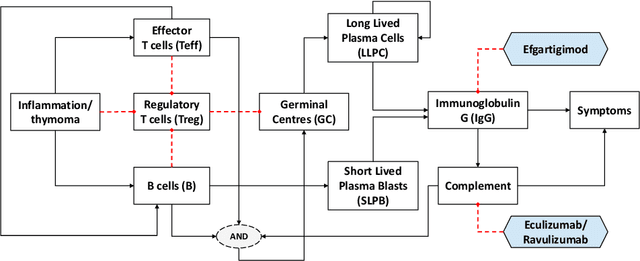
Learning the parameters of Partially Observable Markov Decision Processes (POMDPs) from limited data is a significant challenge. We introduce the Fuzzy MAP EM algorithm, a novel approach that incorporates expert knowledge into the parameter estimation process by enriching the Expectation Maximization (EM) framework with fuzzy pseudo-counts derived from an expert-defined fuzzy model. This integration naturally reformulates the problem as a Maximum A Posteriori (MAP) estimation, effectively guiding learning in environments with limited data. In synthetic medical simulations, our method consistently outperforms the standard EM algorithm under both low-data and high-noise conditions. Furthermore, a case study on Myasthenia Gravis illustrates the ability of the Fuzzy MAP EM algorithm to recover a clinically coherent POMDP, demonstrating its potential as a practical tool for data-efficient modeling in healthcare.
Causal Discovery on Higher-Order Interactions
Nov 18, 2025Causal discovery combines data with knowledge provided by experts to learn the DAG representing the causal relationships between a given set of variables. When data are scarce, bagging is used to measure our confidence in an average DAG obtained by aggregating bootstrapped DAGs. However, the aggregation step has received little attention from the specialized literature: the average DAG is constructed using only the confidence in the individual edges of the bootstrapped DAGs, thus disregarding complex higher-order edge structures. In this paper, we introduce a novel theoretical framework based on higher-order structures and describe a new DAG aggregation algorithm. We perform a simulation study, discussing the advantages and limitations of the proposed approach. Our proposal is both computationally efficient and effective, outperforming state-of-the-art solutions, especially in low sample size regimes and under high dimensionality settings.
LUME-DBN: Full Bayesian Learning of DBNs from Incomplete data in Intensive Care
Nov 06, 2025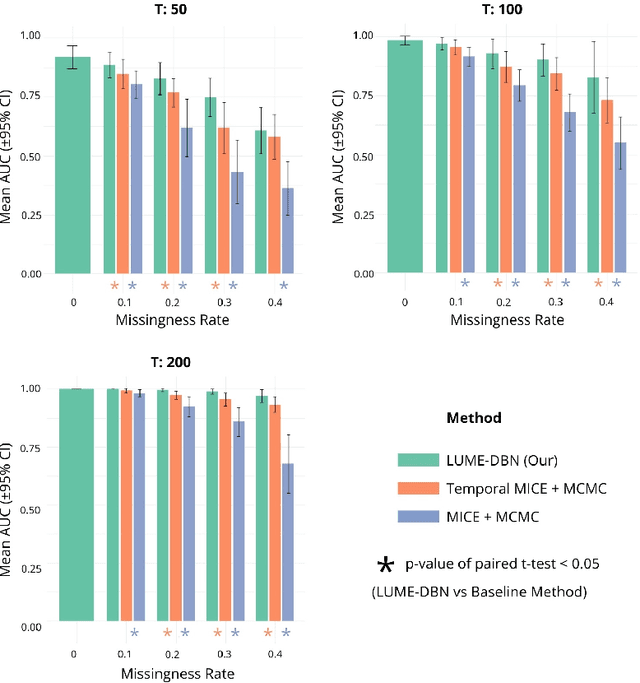
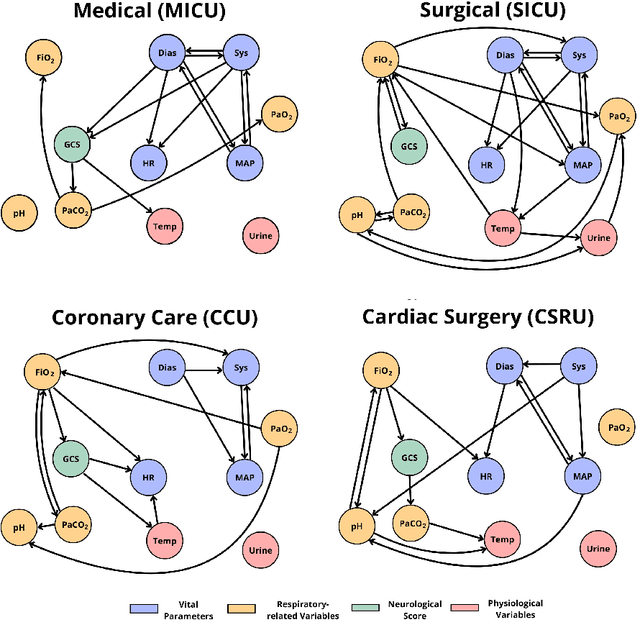
Dynamic Bayesian networks (DBNs) are increasingly used in healthcare due to their ability to model complex temporal relationships in patient data while maintaining interpretability, an essential feature for clinical decision-making. However, existing approaches to handling missing data in longitudinal clinical datasets are largely derived from static Bayesian networks literature, failing to properly account for the temporal nature of the data. This gap limits the ability to quantify uncertainty over time, which is particularly critical in settings such as intensive care, where understanding the temporal dynamics is fundamental for model trustworthiness and applicability across diverse patient groups. Despite the potential of DBNs, a full Bayesian framework that integrates missing data handling remains underdeveloped. In this work, we propose a novel Gibbs sampling-based method for learning DBNs from incomplete data. Our method treats each missing value as an unknown parameter following a Gaussian distribution. At each iteration, the unobserved values are sampled from their full conditional distributions, allowing for principled imputation and uncertainty estimation. We evaluate our method on both simulated datasets and real-world intensive care data from critically ill patients. Compared to standard model-agnostic techniques such as MICE, our Bayesian approach demonstrates superior reconstruction accuracy and convergence properties. These results highlight the clinical relevance of incorporating full Bayesian inference in temporal models, providing more reliable imputations and offering deeper insight into model behavior. Our approach supports safer and more informed clinical decision-making, particularly in settings where missing data are frequent and potentially impactful.
Tackling Federated Unlearning as a Parameter Estimation Problem
Aug 26, 2025Privacy regulations require the erasure of data from deep learning models. This is a significant challenge that is amplified in Federated Learning, where data remains on clients, making full retraining or coordinated updates often infeasible. This work introduces an efficient Federated Unlearning framework based on information theory, modeling leakage as a parameter estimation problem. Our method uses second-order Hessian information to identify and selectively reset only the parameters most sensitive to the data being forgotten, followed by minimal federated retraining. This model-agnostic approach supports categorical and client unlearning without requiring server access to raw client data after initial information aggregation. Evaluations on benchmark datasets demonstrate strong privacy (MIA success near random, categorical knowledge erased) and high performance (Normalized Accuracy against re-trained benchmarks of $\approx$ 0.9), while aiming for increased efficiency over complete retraining. Furthermore, in a targeted backdoor attack scenario, our framework effectively neutralizes the malicious trigger, restoring model integrity. This offers a practical solution for data forgetting in FL.
Classical and Deep Reinforcement Learning Inventory Control Policies for Pharmaceutical Supply Chains with Perishability and Non-Stationarity
Jan 18, 2025We study inventory control policies for pharmaceutical supply chains, addressing challenges such as perishability, yield uncertainty, and non-stationary demand, combined with batching constraints, lead times, and lost sales. Collaborating with Bristol-Myers Squibb (BMS), we develop a realistic case study incorporating these factors and benchmark three policies--order-up-to (OUT), projected inventory level (PIL), and deep reinforcement learning (DRL) using the proximal policy optimization (PPO) algorithm--against a BMS baseline based on human expertise. We derive and validate bounds-based procedures for optimizing OUT and PIL policy parameters and propose a methodology for estimating projected inventory levels, which are also integrated into the DRL policy with demand forecasts to improve decision-making under non-stationarity. Compared to a human-driven policy, which avoids lost sales through higher holding costs, all three implemented policies achieve lower average costs but exhibit greater cost variability. While PIL demonstrates robust and consistent performance, OUT struggles under high lost sales costs, and PPO excels in complex and variable scenarios but requires significant computational effort. The findings suggest that while DRL shows potential, it does not outperform classical policies in all numerical experiments, highlighting 1) the need to integrate diverse policies to manage pharmaceutical challenges effectively, based on the current state-of-the-art, and 2) that practical problems in this domain seem to lack a single policy class that yields universally acceptable performance.
Causal Discovery in Recommender Systems: Example and Discussion
Sep 16, 2024Causality is receiving increasing attention by the artificial intelligence and machine learning communities. This paper gives an example of modelling a recommender system problem using causal graphs. Specifically, we approached the causal discovery task to learn a causal graph by combining observational data from an open-source dataset with prior knowledge. The resulting causal graph shows that only a few variables effectively influence the analysed feedback signals. This contrasts with the recent trend in the machine learning community to include more and more variables in massive models, such as neural networks.
Towards a Transportable Causal Network Model Based on Observational Healthcare Data
Nov 20, 2023


Over the last decades, many prognostic models based on artificial intelligence techniques have been used to provide detailed predictions in healthcare. Unfortunately, the real-world observational data used to train and validate these models are almost always affected by biases that can strongly impact the outcomes validity: two examples are values missing not-at-random and selection bias. Addressing them is a key element in achieving transportability and in studying the causal relationships that are critical in clinical decision making, going beyond simpler statistical approaches based on probabilistic association. In this context, we propose a novel approach that combines selection diagrams, missingness graphs, causal discovery and prior knowledge into a single graphical model to estimate the cardiovascular risk of adolescent and young females who survived breast cancer. We learn this model from data comprising two different cohorts of patients. The resulting causal network model is validated by expert clinicians in terms of risk assessment, accuracy and explainability, and provides a prognostic model that outperforms competing machine learning methods.
Analyzing Complex Systems with Cascades Using Continuous-Time Bayesian Networks
Aug 21, 2023



Interacting systems of events may exhibit cascading behavior where events tend to be temporally clustered. While the cascades themselves may be obvious from the data, it is important to understand which states of the system trigger them. For this purpose, we propose a modeling framework based on continuous-time Bayesian networks (CTBNs) to analyze cascading behavior in complex systems. This framework allows us to describe how events propagate through the system and to identify likely sentry states, that is, system states that may lead to imminent cascading behavior. Moreover, CTBNs have a simple graphical representation and provide interpretable outputs, both of which are important when communicating with domain experts. We also develop new methods for knowledge extraction from CTBNs and we apply the proposed methodology to a data set of alarms in a large industrial system.