 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery on Higher-Order Interactions
Nov 18, 2025Causal discovery combines data with knowledge provided by experts to learn the DAG representing the causal relationships between a given set of variables. When data are scarce, bagging is used to measure our confidence in an average DAG obtained by aggregating bootstrapped DAGs. However, the aggregation step has received little attention from the specialized literature: the average DAG is constructed using only the confidence in the individual edges of the bootstrapped DAGs, thus disregarding complex higher-order edge structures. In this paper, we introduce a novel theoretical framework based on higher-order structures and describe a new DAG aggregation algorithm. We perform a simulation study, discussing the advantages and limitations of the proposed approach. Our proposal is both computationally efficient and effective, outperforming state-of-the-art solutions, especially in low sample size regimes and under high dimensionality settings.
Using GPT-4 to guide causal machine learning
Jul 26, 2024Since its introduction to the public, ChatGPT has had an unprecedented impact. While some experts praised AI advancements and highlighted their potential risks, others have been critical about the accuracy and usefulness of Large Language Models (LLMs). In this paper, we are interested in the ability of LLMs to identify causal relationships. We focus on the well-established GPT-4 (Turbo) and evaluate its performance under the most restrictive conditions, by isolating its ability to infer causal relationships based solely on the variable labels without being given any context, demonstrating the minimum level of effectiveness one can expect when it is provided with label-only information. We show that questionnaire participants judge the GPT-4 graphs as the most accurate in the evaluated categories, closely followed by knowledge graphs constructed by domain experts, with causal Machine Learning (ML) far behind. We use these results to highlight the important limitation of causal ML, which often produces causal graphs that violate common sense, affecting trust in them. However, we show that pairing GPT-4 with causal ML overcomes this limitation, resulting in graphical structures learnt from real data that align more closely with those identified by domain experts, compared to structures learnt by causal ML alone. Overall, our findings suggest that despite GPT-4 not being explicitly designed to reason causally, it can still be a valuable tool for causal representation, as it improves the causal discovery process of causal ML algorithms that are designed to do just that.
Towards a Transportable Causal Network Model Based on Observational Healthcare Data
Nov 20, 2023


Over the last decades, many prognostic models based on artificial intelligence techniques have been used to provide detailed predictions in healthcare. Unfortunately, the real-world observational data used to train and validate these models are almost always affected by biases that can strongly impact the outcomes validity: two examples are values missing not-at-random and selection bias. Addressing them is a key element in achieving transportability and in studying the causal relationships that are critical in clinical decision making, going beyond simpler statistical approaches based on probabilistic association. In this context, we propose a novel approach that combines selection diagrams, missingness graphs, causal discovery and prior knowledge into a single graphical model to estimate the cardiovascular risk of adolescent and young females who survived breast cancer. We learn this model from data comprising two different cohorts of patients. The resulting causal network model is validated by expert clinicians in terms of risk assessment, accuracy and explainability, and provides a prognostic model that outperforms competing machine learning methods.
Causal Discovery with Missing Data in a Multicentric Clinical Study
May 17, 2023

Causal inference for testing clinical hypotheses from observational data presents many difficulties because the underlying data-generating model and the associated causal graph are not usually available. Furthermore, observational data may contain missing values, which impact the recovery of the causal graph by causal discovery algorithms: a crucial issue often ignored in clinical studies. In this work, we use data from a multi-centric study on endometrial cancer to analyze the impact of different missingness mechanisms on the recovered causal graph. This is achieved by extending state-of-the-art causal discovery algorithms to exploit expert knowledge without sacrificing theoretical soundness. We validate the recovered graph with expert physicians, showing that our approach finds clinically-relevant solutions. Finally, we discuss the goodness of fit of our graph and its consistency from a clinical decision-making perspective using graphical separation to validate causal pathways.
A Survey on Causal Discovery: Theory and Practice
May 17, 2023Understanding the laws that govern a phenomenon is the core of scientific progress. This is especially true when the goal is to model the interplay between different aspects in a causal fashion. Indeed, causal inference itself is specifically designed to quantify the underlying relationships that connect a cause to its effect. Causal discovery is a branch of the broader field of causality in which causal graphs is recovered from data (whenever possible), enabling the identification and estimation of causal effects. In this paper, we explore recent advancements in a unified manner, provide a consistent overview of existing algorithms developed under different settings, report useful tools and data, present real-world applications to understand why and how these methods can be fruitfully exploited.
Risk Assessment of Lymph Node Metastases in Endometrial Cancer Patients: A Causal Approach
May 17, 2023



Assessing the pre-operative risk of lymph node metastases in endometrial cancer patients is a complex and challenging task. In principle, machine learning and deep learning models are flexible and expressive enough to capture the dynamics of clinical risk assessment. However, in this setting we are limited to observational data with quality issues, missing values, small sample size and high dimensionality: we cannot reliably learn such models from limited observational data with these sources of bias. Instead, we choose to learn a causal Bayesian network to mitigate the issues above and to leverage the prior knowledge on endometrial cancer available from clinicians and physicians. We introduce a causal discovery algorithm for causal Bayesian networks based on bootstrap resampling, as opposed to the single imputation used in related works. Moreover, we include a context variable to evaluate whether selection bias results in learning spurious associations. Finally, we discuss the strengths and limitations of our findings in light of the presence of missing data that may be missing-not-at-random, which is common in real-world clinical settings.
ACTA: A Mobile-Health Solution for Integrated Nudge-Neurofeedback Training for Senior Citizens
Feb 17, 2021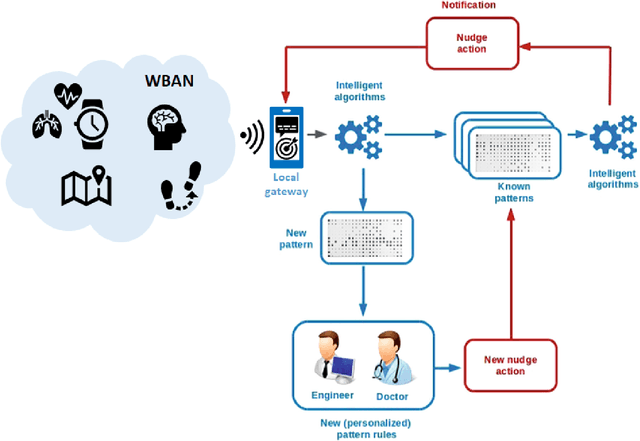
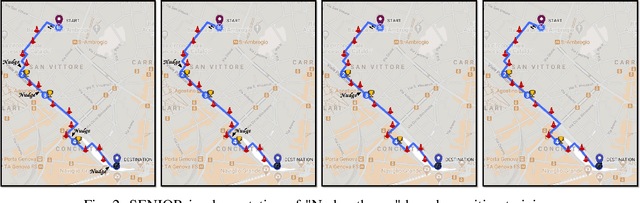
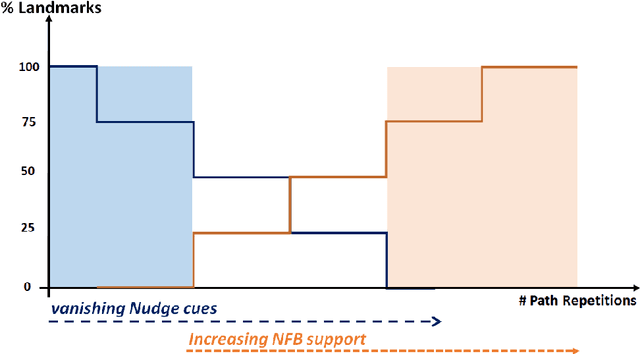
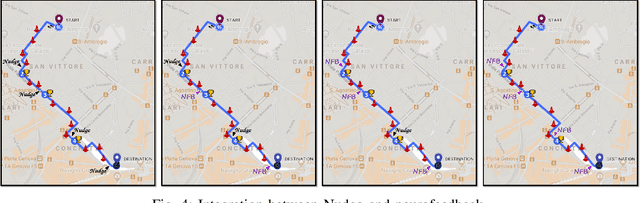
As the worldwide population gets increasingly aged, in-home telemedicine and mobile-health solutions represent promising services to promote active and independent aging and to contribute to a paradigm shift towards patient-centric healthcare. In this work, we present ACTA (Advanced Cognitive Training for Aging), a prototype mobile-health solution to provide advanced cognitive training for senior citizens with mild cognitive impairments. We disclose here the conceptualization of ACTA as the integration of two promising rehabilitation strategies: the "Nudge theory", from the cognitive domain, and the neurofeedback, from the neuroscience domain. Moreover, in ACTA we exploit the most advanced machine learning techniques to deliver customized and fully adaptive support to the elderly, while training in an ecological environment. ACTA represents the next-step beyond SENIOR, an earlier mobile-health project for cognitive training based on Nudge theory, currently ongoing in Lombardy Region. Beyond SENIOR, ACTA represents a highly-usable, accessible, low-cost, new-generation mobile-health solution to promote independent aging and effective motor-cognitive training support, while empowering the elderly in their own aging.
Comparison of Attention-based Deep Learning Models for EEG Classification
Dec 02, 2020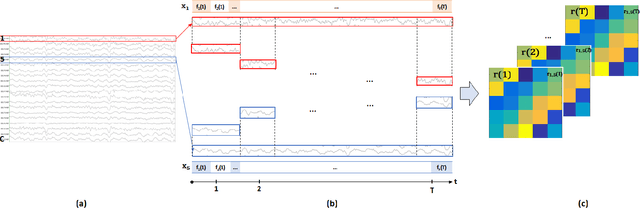
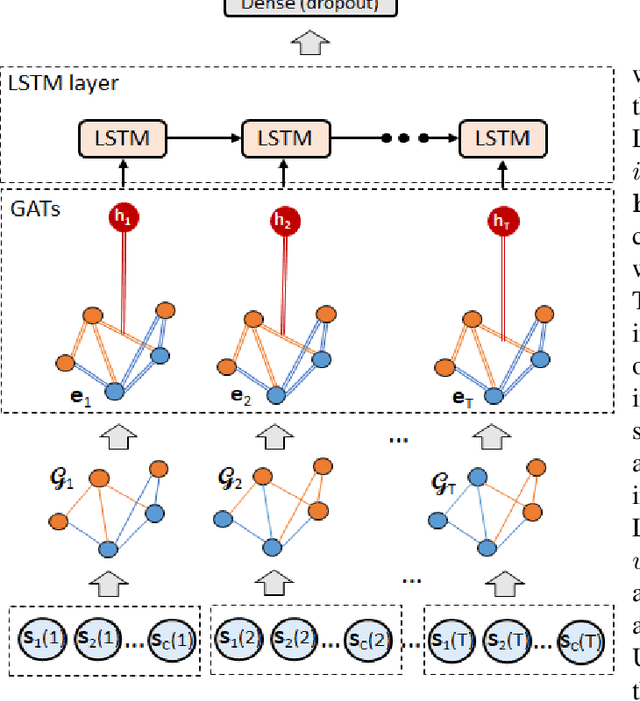
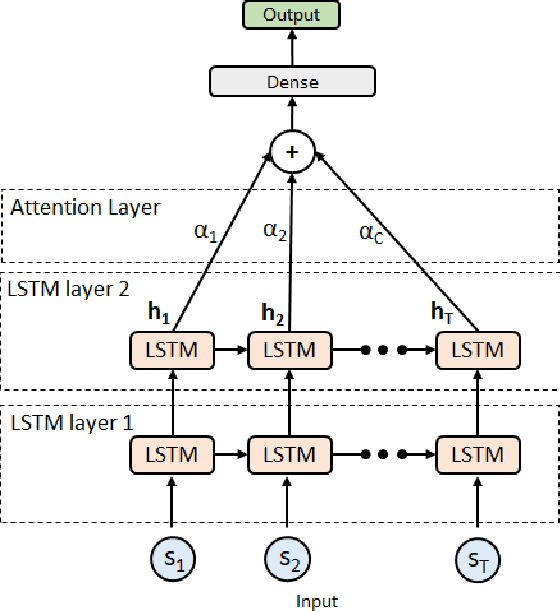
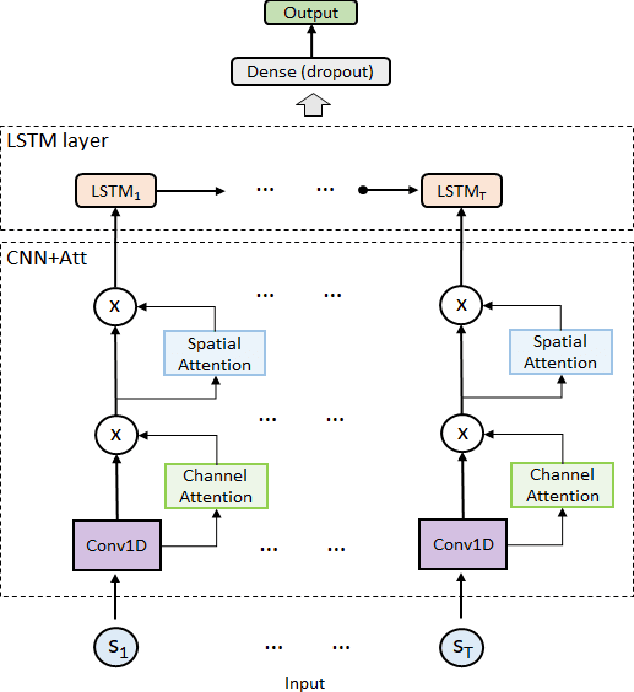
Objective: To evaluate the impact on Electroencephalography (EEG) classification of different kinds of attention mechanisms in Deep Learning (DL) models. Methods: We compared three attention-enhanced DL models, the brand-new InstaGATs, an LSTM with attention and a CNN with attention. We used these models to classify normal and abnormal (i.e., artifactual or pathological) EEG patterns. Results: We achieved the state of the art in all classification problems, regardless the large variability of the datasets and the simple architecture of the attention-enhanced models. We could also prove that, depending on how the attention mechanism is applied and where the attention layer is located in the model, we can alternatively leverage the information contained in the time, frequency or space domain of the dataset. Conclusions: with this work, we shed light over the role of different attention mechanisms in the classification of normal and abnormal EEG patterns. Moreover, we discussed how they can exploit the intrinsic relationships in the temporal, frequency and spatial domains of our brain activity. Significance: Attention represents a promising strategy to evaluate the quality of the EEG information, and its relevance, in different real-world scenarios. Moreover, it can make it easier to parallelize the computation and, thus, to speed up the analysis of big electrophysiological (e.g., EEG) datasets.