 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the mechanisms of the Hattrick football manager game using Bayesian network structure learning for optimal decision-making
Apr 13, 2025Hattrick is a free web-based probabilistic football manager game with over 200,000 users competing for titles at national and international levels. Launched in Sweden in 1997 as part of an MSc project, the game's slow-paced design has fostered a loyal community, with many users remaining active for decades. Hattrick's game-engine mechanics are partially hidden, and users have attempted to decode them with incremental success over the years. Rule-based, statistical and machine learning models have been developed to aid this effort and are widely used by the community. However, these models or tools have not been formally described or evaluated in the scientific literature. This study is the first to explore Hattrick using structure learning techniques and Bayesian networks, integrating both data and domain knowledge to develop models capable of explaining and simulating the game engine. We present a comprehensive analysis assessing the effectiveness of structure learning algorithms in relation to knowledge-based structures, and show that while structure learning may achieve a higher overall network fit, it does not result in more accurate predictions for selected variables of interest, when compared to knowledge-based networks that produce a lower overall network fit. Additionally, we introduce and publicly share a fully specified Bayesian network model that matches the performance of top models used by the Hattrick community. We further demonstrate how analysis extends beyond prediction by providing a visual representation of conditional dependencies, and using the best performing Bayesian network model for in-game decision-making. To support future research, we make all data, graphical structures, and models publicly available online.
Stable Structure Learning with HC-Stable and Tabu-Stable Algorithms
Apr 02, 2025Many Bayesian Network structure learning algorithms are unstable, with the learned graph sensitive to arbitrary dataset artifacts, such as the ordering of columns (i.e., variable order). PC-Stable attempts to address this issue for the widely-used PC algorithm, prompting researchers to use the "stable" version instead. However, this problem seems to have been overlooked for score-based algorithms. In this study, we show that some widely-used score-based algorithms, as well as hybrid and constraint-based algorithms, including PC-Stable, suffer from the same issue. We propose a novel solution for score-based greedy hill-climbing that eliminates instability by determining a stable node order, leading to consistent results regardless of variable ordering. Two implementations, HC-Stable and Tabu-Stable, are introduced. Tabu-Stable achieves the highest BIC scores across all networks, and the highest accuracy for categorical networks. These results highlight the importance of addressing instability in structure learning and provide a robust and practical approach for future applications. This extends the scope and impact of our previous work presented at Probabilistic Graphical Models 2024 by incorporating continuous variables. The implementation, along with usage instructions, is freely available on GitHub at https://github.com/causal-iq/discovery.
Using GPT-4 to guide causal machine learning
Jul 26, 2024Since its introduction to the public, ChatGPT has had an unprecedented impact. While some experts praised AI advancements and highlighted their potential risks, others have been critical about the accuracy and usefulness of Large Language Models (LLMs). In this paper, we are interested in the ability of LLMs to identify causal relationships. We focus on the well-established GPT-4 (Turbo) and evaluate its performance under the most restrictive conditions, by isolating its ability to infer causal relationships based solely on the variable labels without being given any context, demonstrating the minimum level of effectiveness one can expect when it is provided with label-only information. We show that questionnaire participants judge the GPT-4 graphs as the most accurate in the evaluated categories, closely followed by knowledge graphs constructed by domain experts, with causal Machine Learning (ML) far behind. We use these results to highlight the important limitation of causal ML, which often produces causal graphs that violate common sense, affecting trust in them. However, we show that pairing GPT-4 with causal ML overcomes this limitation, resulting in graphical structures learnt from real data that align more closely with those identified by domain experts, compared to structures learnt by causal ML alone. Overall, our findings suggest that despite GPT-4 not being explicitly designed to reason causally, it can still be a valuable tool for causal representation, as it improves the causal discovery process of causal ML algorithms that are designed to do just that.
Investigating potential causes of Sepsis with Bayesian network structure learning
Jun 13, 2024Sepsis is a life-threatening and serious global health issue. This study combines knowledge with available hospital data to investigate the potential causes of Sepsis that can be affected by policy decisions. We investigate the underlying causal structure of this problem by combining clinical expertise with score-based, constraint-based, and hybrid structure learning algorithms. A novel approach to model averaging and knowledge-based constraints was implemented to arrive at a consensus structure for causal inference. The structure learning process highlighted the importance of exploring data-driven approaches alongside clinical expertise. This includes discovering unexpected, although reasonable, relationships from a clinical perspective. Hypothetical interventions on Chronic Obstructive Pulmonary Disease, Alcohol dependence, and Diabetes suggest that the presence of any of these risk factors in patients increases the likelihood of Sepsis. This finding, alongside measuring the effect of these risk factors on Sepsis, has potential policy implications. Recognising the importance of prediction in improving Sepsis related health outcomes, the model built is also assessed in its ability to predict Sepsis. The predictions generated by the consensus model were assessed for their accuracy, sensitivity, and specificity. These three indicators all had results around 70%, and the AUC was 80%, which means the causal structure of the model is reasonably accurate given that the models were trained on data available for commissioning purposes only.
Open problems in causal structure learning: A case study of COVID-19 in the UK
May 05, 2023



Causal machine learning (ML) algorithms recover graphical structures that tell us something about cause-and-effect relationships. The causal representation provided by these algorithms enables transparency and explainability, which is necessary in critical real-world problems. Yet, causal ML has had limited impact in practice compared to associational ML. This paper investigates the challenges of causal ML with application to COVID-19 UK pandemic data. We collate data from various public sources and investigate what the various structure learning algorithms learn from these data. We explore the impact of different data formats on algorithms spanning different classes of learning, and assess the results produced by each algorithm, and groups of algorithms, in terms of graphical structure, model dimensionality, sensitivity analysis, confounding variables, predictive and interventional inference. We use these results to highlight open problems in causal structure learning and directions for future research. To facilitate future work, we make all graphs, models and data sets publicly available online.
Hybrid Bayesian network discovery with latent variables by scoring multiple interventions
Dec 20, 2021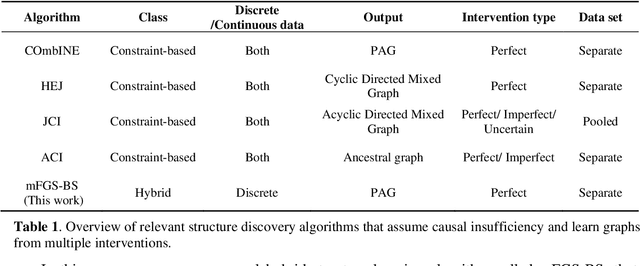
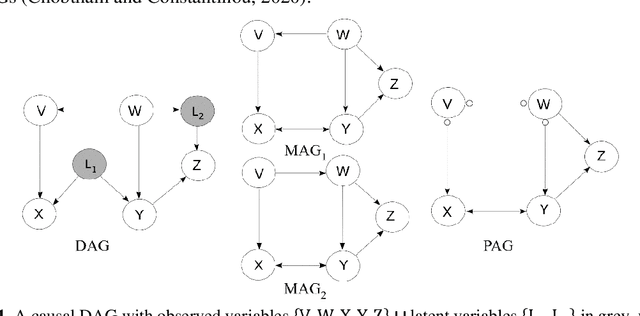
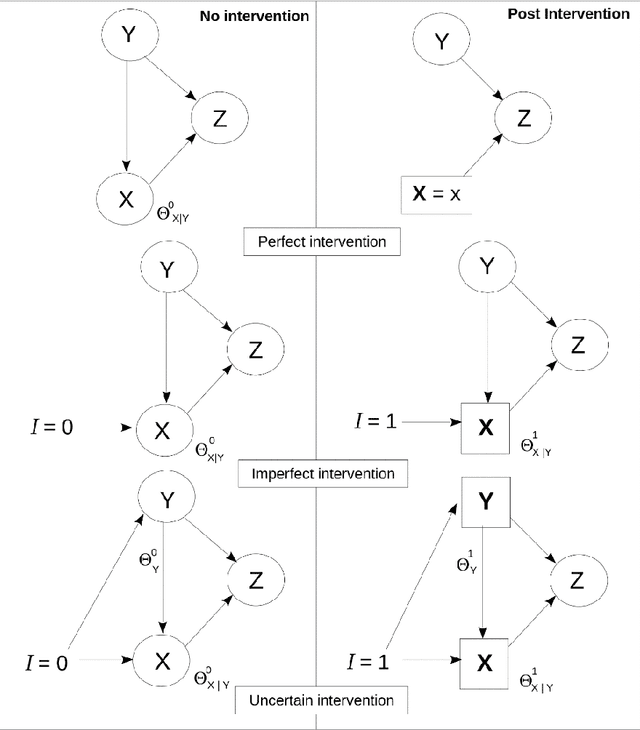

In Bayesian Networks (BNs), the direction of edges is crucial for causal reasoning and inference. However, Markov equivalence class considerations mean it is not always possible to establish edge orientations, which is why many BN structure learning algorithms cannot orientate all edges from purely observational data. Moreover, latent confounders can lead to false positive edges. Relatively few methods have been proposed to address these issues. In this work, we present the hybrid mFGS-BS (majority rule and Fast Greedy equivalence Search with Bayesian Scoring) algorithm for structure learning from discrete data that involves an observational data set and one or more interventional data sets. The algorithm assumes causal insufficiency in the presence of latent variables and produces a Partial Ancestral Graph (PAG). Structure learning relies on a hybrid approach and a novel Bayesian scoring paradigm that calculates the posterior probability of each directed edge being added to the learnt graph. Experimental results based on well-known networks of up to 109 variables and 10k sample size show that mFGS-BS improves structure learning accuracy relative to the state-of-the-art and it is computationally efficient.
Effective and efficient structure learning with pruning and model averaging strategies
Dec 01, 2021
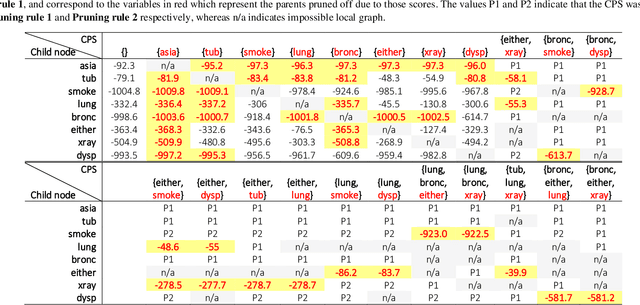
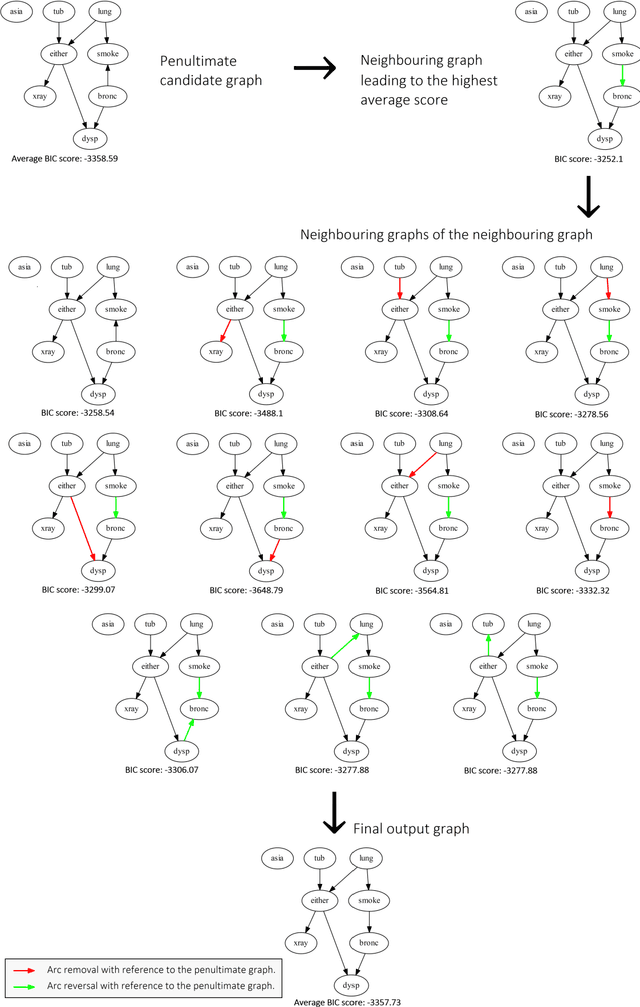
Learning the structure of a Bayesian Network (BN) with score-based solutions involves exploring the search space of possible graphs and moving towards the graph that maximises a given objective function. Some algorithms offer exact solutions that guarantee to return the graph with the highest objective score, while others offer approximate solutions in exchange for reduced computational complexity. This paper describes an approximate BN structure learning algorithm, which we call Model Averaging Hill-Climbing (MAHC), that combines two novel strategies with hill-climbing search. The algorithm starts by pruning the search space of graphs, where the pruning strategy can be viewed as an aggressive version of the pruning strategies that are typically applied to combinatorial optimisation structure learning problems. It then performs model averaging in the hill-climbing search process and moves to the neighbouring graph that maximises the objective function, on average, for that neighbouring graph and over all its valid neighbouring graphs. Comparisons with other algorithms spanning different classes of learning suggest that the combination of aggressive pruning with model averaging is both effective and efficient, particularly in the presence of data noise.
A survey of Bayesian Network structure learning
Sep 23, 2021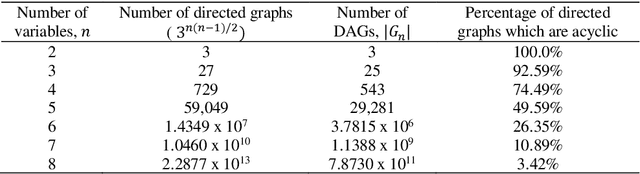

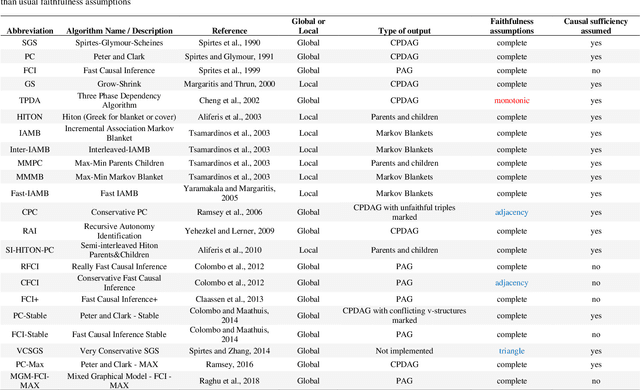
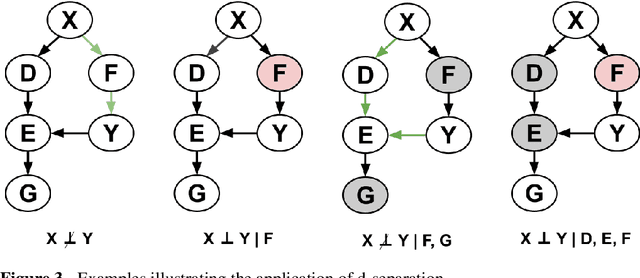
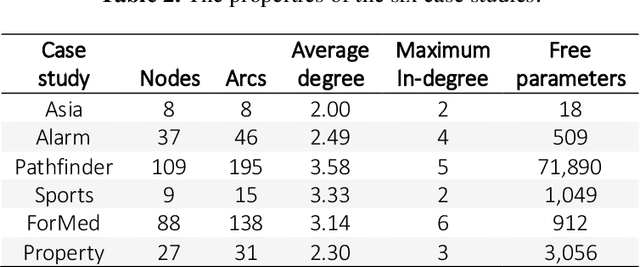
Bayesian Networks (BNs) have become increasingly popular over the last few decades as a tool for reasoning under uncertainty in fields as diverse as medicine, biology, epidemiology, economics and the social sciences. This is especially true in real-world areas where we seek to answer complex questions based on hypothetical evidence to determine actions for intervention. However, determining the graphical structure of a BN remains a major challenge, especially when modelling a problem under causal assumptions. Solutions to this problem include the automated discovery of BN graphs from data, constructing them based on expert knowledge, or a combination of the two. This paper provides a comprehensive review of combinatoric algorithms proposed for learning BN structure from data, describing 61 algorithms including prototypical, well-established and state-of-the-art approaches. The basic approach of each algorithm is described in consistent terms, and the similarities and differences between them highlighted. Methods of evaluating algorithms and their comparative performance are discussed including the consistency of claims made in the literature. Approaches for dealing with data noise in real-world datasets and incorporating expert knowledge into the learning process are also covered.
Information fusion between knowledge and data in Bayesian network structure learning
Jan 31, 2021



Bayesian Networks (BNs) have become a powerful technology for reasoning under uncertainty, particularly in areas that require causal assumptions that enable us to simulate the effect of intervention. The graphical structure of these models can be determined by causal knowledge, learnt from data, or a combination of both. While it seems plausible that the best approach in constructing a causal graph involves combining knowledge with machine learning, this approach remains underused in practice. This paper describes and evaluates a set of information fusion methods that have been implemented in the open-source Bayesys structure learning system. The methods enable users to specify pre-existing knowledge and rule-based information that can be obtained from heterogeneous sources, to constrain or guide structure learning. Each method is assessed in terms of structure learning impact, including graphical accuracy, model fitting, complexity and runtime. The results are illustrated both with limited and big data, with application to three BN structure learning algorithms available in Bayesys, and reveal interesting inconsistencies about their effectiveness where the results obtained from graphical measures often contradict those obtained from model fitting measures. While the overall results show that information fusion methods become less effective with big data due to higher learning accuracy rendering knowledge less important, some information fusion methods do perform better with big data. Lastly, amongst the main conclusions is the observation that reduced search space obtained from knowledge constraints does not imply reduced computational complexity, which can happen when the constraints set up a tension between what the data indicate and what the constraints are trying to enforce.
Large-scale empirical validation of Bayesian Network structure learning algorithms with noisy data
May 18, 2020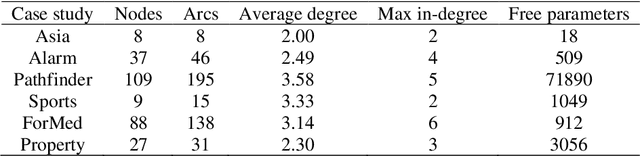
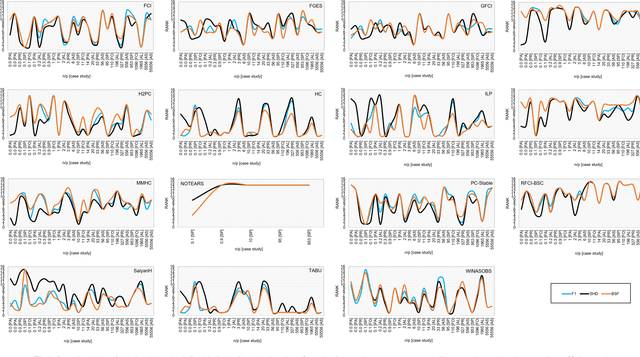
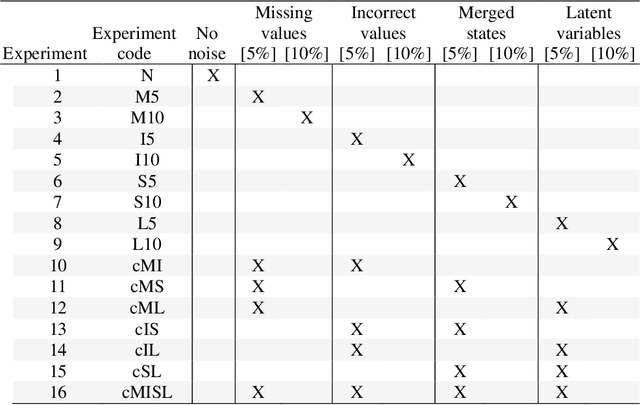
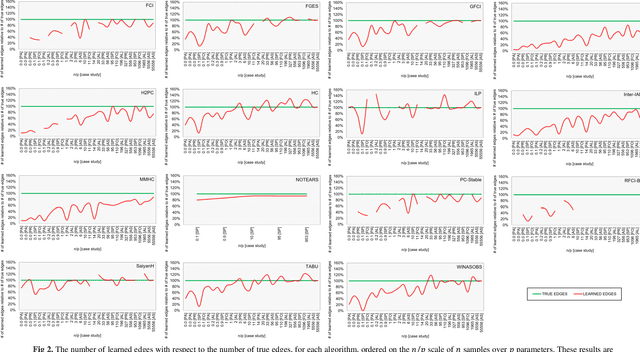
Numerous Bayesian Network (BN) structure learning algorithms have been proposed in the literature over the past few decades. Each publication makes an empirical or theoretical case for the algorithm proposed in that publication and results across studies are often inconsistent in their claims about which algorithm is 'best'. This is partly because there is no agreed evaluation approach to determine their effectiveness. Moreover, each algorithm is based on a set of assumptions, such as complete data and causal sufficiency, and tend to be evaluated with data that conforms to these assumptions, however unrealistic these assumptions may be in the real world. As a result, it is widely accepted that synthetic performance overestimates real performance, although to what degree this may happen remains unknown. This paper investigates the performance of 15 structure learning algorithms. We propose a methodology that applies the algorithms to data that incorporates synthetic noise, in an effort to better understand the performance of structure learning algorithms when applied to real data. Each algorithm is tested over multiple case studies, sample sizes, types of noise, and assessed with multiple evaluation criteria. This work involved learning more than 10,000 graphs with a total structure learning runtime of seven months. It provides the first large-scale empirical validation of BN structure learning algorithms under different assumptions of data noise. The results suggest that traditional synthetic performance may overestimate real-world performance by anywhere between 10% and more than 50%. They also show that while score-based learning is generally superior to constraint-based learning, a higher fitting score does not necessarily imply a more accurate causal graph. To facilitate comparisons with future studies, we have made all data, graphs and BN models freely available online.