 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale empirical validation of Bayesian Network structure learning algorithms with noisy data
Paper and Code
May 18, 2020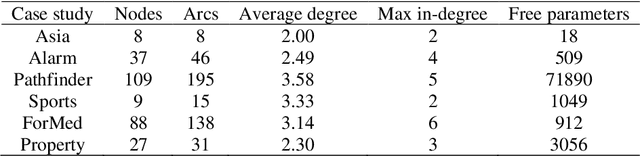
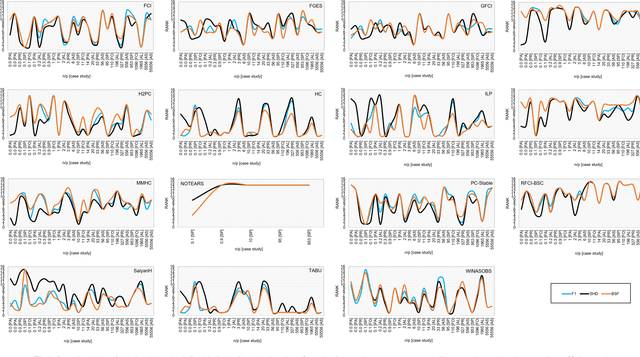
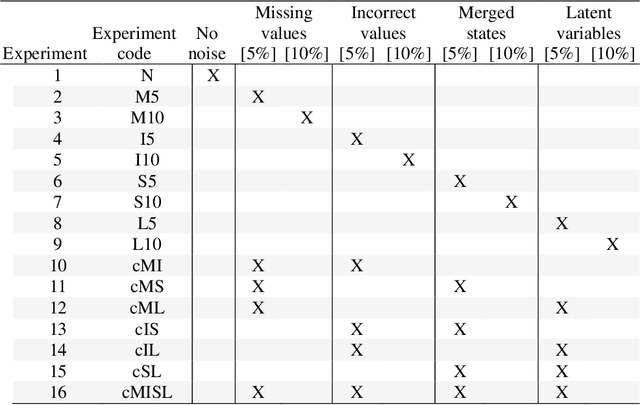
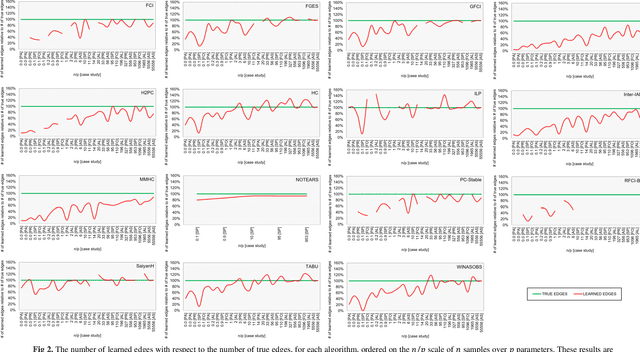
Numerous Bayesian Network (BN) structure learning algorithms have been proposed in the literature over the past few decades. Each publication makes an empirical or theoretical case for the algorithm proposed in that publication and results across studies are often inconsistent in their claims about which algorithm is 'best'. This is partly because there is no agreed evaluation approach to determine their effectiveness. Moreover, each algorithm is based on a set of assumptions, such as complete data and causal sufficiency, and tend to be evaluated with data that conforms to these assumptions, however unrealistic these assumptions may be in the real world. As a result, it is widely accepted that synthetic performance overestimates real performance, although to what degree this may happen remains unknown. This paper investigates the performance of 15 structure learning algorithms. We propose a methodology that applies the algorithms to data that incorporates synthetic noise, in an effort to better understand the performance of structure learning algorithms when applied to real data. Each algorithm is tested over multiple case studies, sample sizes, types of noise, and assessed with multiple evaluation criteria. This work involved learning more than 10,000 graphs with a total structure learning runtime of seven months. It provides the first large-scale empirical validation of BN structure learning algorithms under different assumptions of data noise. The results suggest that traditional synthetic performance may overestimate real-world performance by anywhere between 10% and more than 50%. They also show that while score-based learning is generally superior to constraint-based learning, a higher fitting score does not necessarily imply a more accurate causal graph. To facilitate comparisons with future studies, we have made all data, graphs and BN models freely available online.