 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen problems in causal structure learning: A case study of COVID-19 in the UK
May 05, 2023Causal machine learning (ML) algorithms recover graphical structures that tell us something about cause-and-effect relationships. The causal representation provided by these algorithms enables transparency and explainability, which is necessary in critical real-world problems. Yet, causal ML has had limited impact in practice compared to associational ML. This paper investigates the challenges of causal ML with application to COVID-19 UK pandemic data. We collate data from various public sources and investigate what the various structure learning algorithms learn from these data. We explore the impact of different data formats on algorithms spanning different classes of learning, and assess the results produced by each algorithm, and groups of algorithms, in terms of graphical structure, model dimensionality, sensitivity analysis, confounding variables, predictive and interventional inference. We use these results to highlight open problems in causal structure learning and directions for future research. To facilitate future work, we make all graphs, models and data sets publicly available online.
MphayaNER: Named Entity Recognition for Tshivenda
Apr 08, 2023
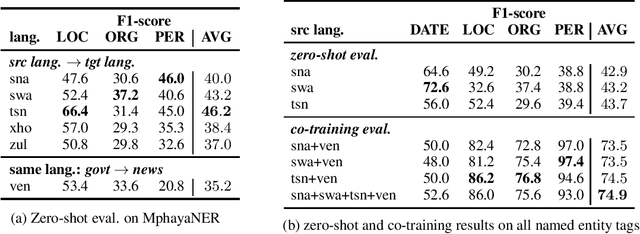
Named Entity Recognition (NER) plays a vital role in various Natural Language Processing tasks such as information retrieval, text classification, and question answering. However, NER can be challenging, especially in low-resource languages with limited annotated datasets and tools. This paper adds to the effort of addressing these challenges by introducing MphayaNER, the first Tshivenda NER corpus in the news domain. We establish NER baselines by \textit{fine-tuning} state-of-the-art models on MphayaNER. The study also explores zero-shot transfer between Tshivenda and other related Bantu languages, with chiShona and Kiswahili showing the best results. Augmenting MphayaNER with chiShona data was also found to improve model performance significantly. Both MphayaNER and the baseline models are made publicly available.
Imputation of Missing Streamflow Data at Multiple Gauging Stations in Benin Republic
Nov 17, 2022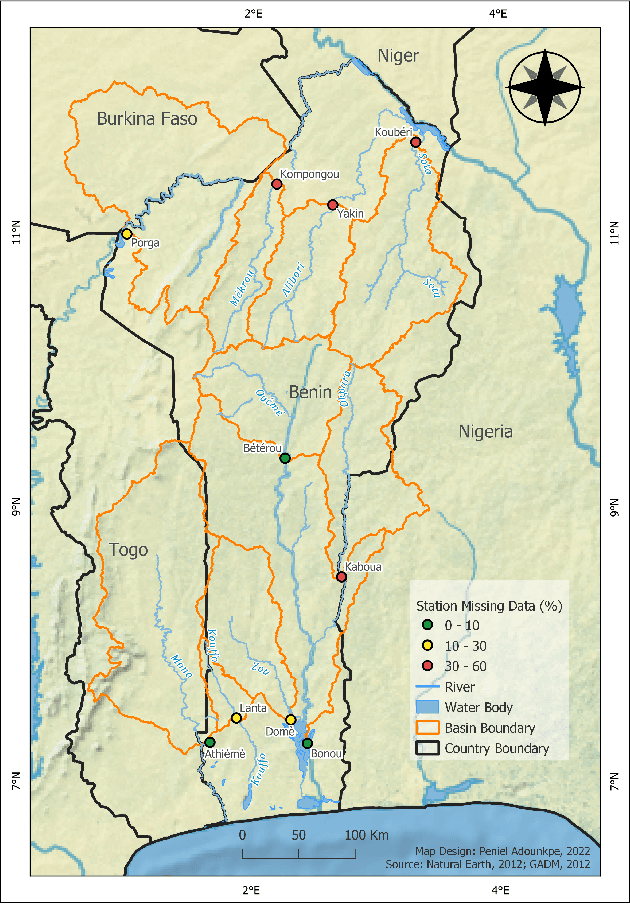
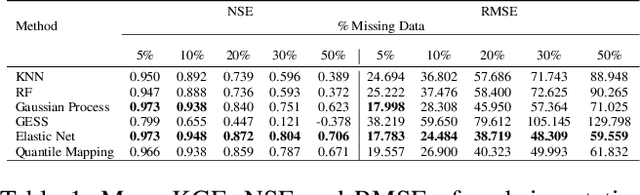
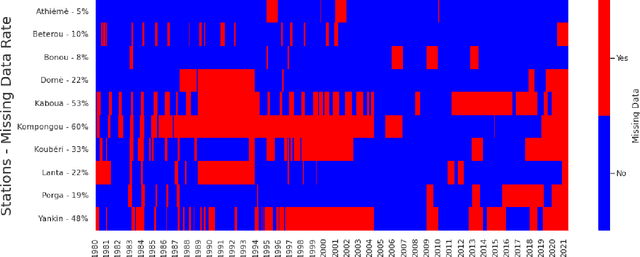
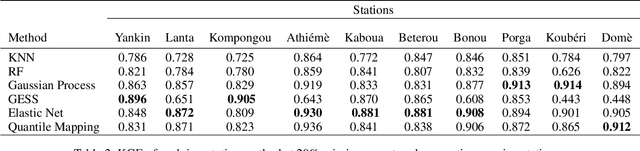
Streamflow observation data is vital for flood monitoring, agricultural, and settlement planning. However, such streamflow data are commonly plagued with missing observations due to various causes such as harsh environmental conditions and constrained operational resources. This problem is often more pervasive in under-resourced areas such as Sub-Saharan Africa. In this work, we reconstruct streamflow time series data through bias correction of the GEOGloWS ECMWF streamflow service (GESS) forecasts at ten river gauging stations in Benin Republic. We perform bias correction by fitting Quantile Mapping, Gaussian Process, and Elastic Net regression in a constrained training period. We show by simulating missingness in a testing period that GESS forecasts have a significant bias that results in low predictive skill over the ten Beninese stations. Our findings suggest that overall bias correction by Elastic Net and Gaussian Process regression achieves superior skill relative to traditional imputation by Random Forest, k-Nearest Neighbour, and GESS lookup. The findings of this work provide a basis for integrating global GESS streamflow data into operational early-warning decision-making systems (e.g., flood alert) in countries vulnerable to drought and flooding due to extreme weather events.
Antithetic Riemannian Manifold And Quantum-Inspired Hamiltonian Monte Carlo
Jul 05, 2021
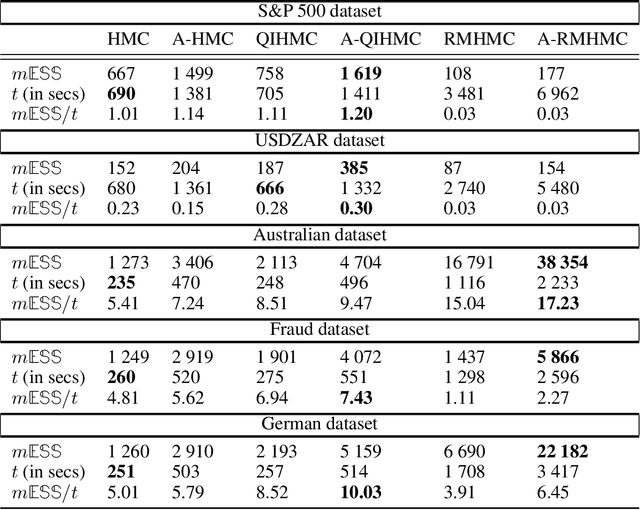
Markov Chain Monte Carlo inference of target posterior distributions in machine learning is predominately conducted via Hamiltonian Monte Carlo and its variants. This is due to Hamiltonian Monte Carlo based samplers ability to suppress random-walk behaviour. As with other Markov Chain Monte Carlo methods, Hamiltonian Monte Carlo produces auto-correlated samples which results in high variance in the estimators, and low effective sample size rates in the generated samples. Adding antithetic sampling to Hamiltonian Monte Carlo has been previously shown to produce higher effective sample rates compared to vanilla Hamiltonian Monte Carlo. In this paper, we present new algorithms which are antithetic versions of Riemannian Manifold Hamiltonian Monte Carlo and Quantum-Inspired Hamiltonian Monte Carlo. The Riemannian Manifold Hamiltonian Monte Carlo algorithm improves on Hamiltonian Monte Carlo by taking into account the local geometry of the target, which is beneficial for target densities that may exhibit strong correlations in the parameters. Quantum-Inspired Hamiltonian Monte Carlo is based on quantum particles that can have random mass. Quantum-Inspired Hamiltonian Monte Carlo uses a random mass matrix which results in better sampling than Hamiltonian Monte Carlo on spiky and multi-modal distributions such as jump diffusion processes. The analysis is performed on jump diffusion process using real world financial market data, as well as on real world benchmark classification tasks using Bayesian logistic regression.
Predicting Higher Education Throughput in South Africa Using a Tree-Based Ensemble Technique
Jun 12, 2021
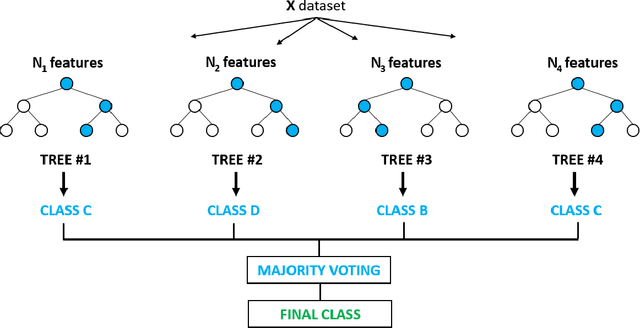

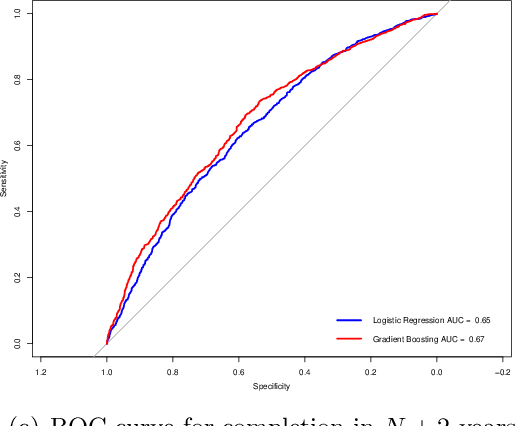
We use gradient boosting machines and logistic regression to predict academic throughput at a South African university. The results highlight the significant influence of socio-economic factors and field of study as predictors of throughput. We further find that socio-economic factors become less of a predictor relative to the field of study as the time to completion increases. We provide recommendations on interventions to counteract the identified effects, which include academic, psychosocial and financial support.
Forecasting The JSE Top 40 Using Long Short-Term Memory Networks
Apr 20, 2021

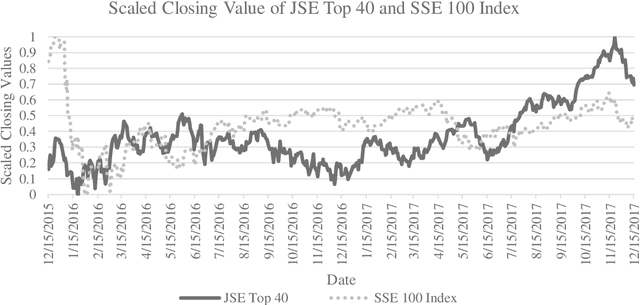
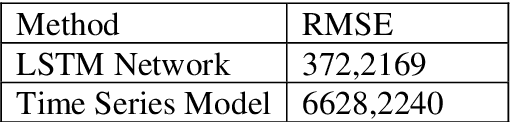
As a result of the greater availability of big data, as well as the decreasing costs and increasing power of modern computing, the use of artificial neural networks for financial time series forecasting is once again a major topic of discussion and research in the financial world. Despite this academic focus, there are still contrasting opinions and bodies of literature on which artificial neural networks perform the best and whether or not they outperform the forecasting capabilities of conventional time series models. This paper uses a long-short term memory network to perform financial time series forecasting on the return data of the JSE Top 40 index. Furthermore, the forecasting performance of the long-short term memory network is compared to the forecasting performance of a seasonal autoregressive integrated moving average model. This paper evaluates the varying approaches presented in the existing literature and ultimately, compares the results to that existing literature. The paper concludes that the long short-term memory network outperforms the seasonal autoregressive integrated moving average model when forecasting intraday directional movements as well as when forecasting the index close price.
Healing Products of Gaussian Processes
Feb 14, 2021

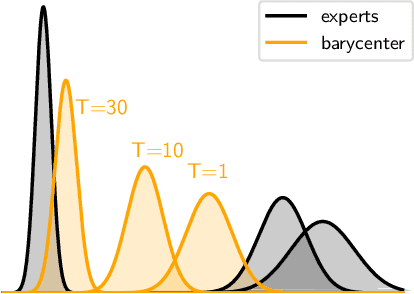
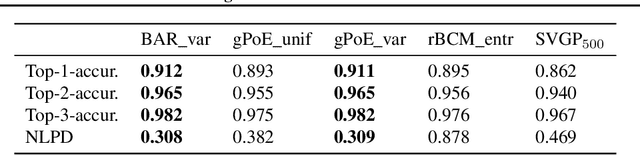
Gaussian processes (GPs) are nonparametric Bayesian models that have been applied to regression and classification problems. One of the approaches to alleviate their cubic training cost is the use of local GP experts trained on subsets of the data. In particular, product-of-expert models combine the predictive distributions of local experts through a tractable product operation. While these expert models allow for massively distributed computation, their predictions typically suffer from erratic behaviour of the mean or uncalibrated uncertainty quantification. By calibrating predictions via a tempered softmax weighting, we provide a solution to these problems for multiple product-of-expert models, including the generalised product of experts and the robust Bayesian committee machine. Furthermore, we leverage the optimal transport literature and propose a new product-of-expert model that combines predictions of local experts by computing their Wasserstein barycenter, which can be applied to both regression and classification.
An Automatic Relevance Determination Prior Bayesian Neural Network for Controlled Variable Selection
Jan 06, 2020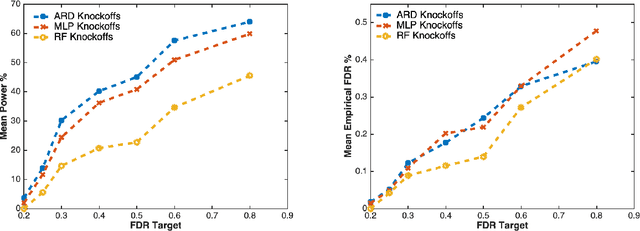

We present an Automatic Relevance Determination prior Bayesian Neural Network(BNN-ARD) weight l2-norm measure as a feature importance statistic for the model-x knockoff filter. We show on both simulated data and the Norwegian wind farm dataset that the proposed feature importance statistic yields statistically significant improvements relative to similar feature importance measures in both variable selection power and predictive performance on a real world dataset.
Automatic Relevance Determination Bayesian Neural Networks for Credit Card Default Modelling
Jun 14, 2019


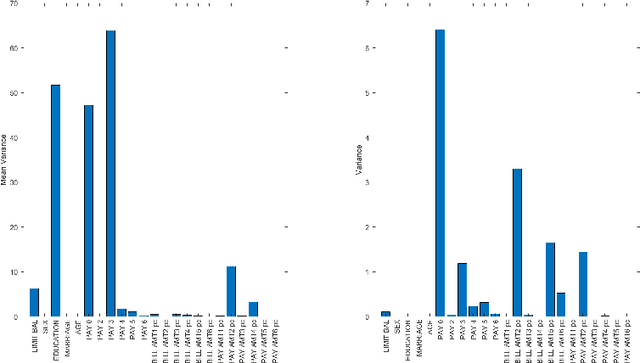
Credit risk modelling is an integral part of the global financial system. While there has been great attention paid to neural network models for credit default prediction, such models often lack the required interpretation mechanisms and measures of the uncertainty around their predictions. This work develops and compares Bayesian Neural Networks(BNNs) for credit card default modelling. This includes a BNNs trained by Gaussian approximation and the first implementation of BNNs trained by Hybrid Monte Carlo(HMC) in credit risk modelling. The results on the Taiwan Credit Dataset show that BNNs with Automatic Relevance Determination(ARD) outperform normal BNNs without ARD. The results also show that BNNs trained by Gaussian approximation display similar predictive performance to those trained by the HMC. The results further show that BNN with ARD can be used to draw inferences about the relative importance of different features thus critically aiding decision makers in explaining model output to consumers. The robustness of this result is reinforced by high levels of congruence between the features identified as important using the two different approaches for training BNNs.
On the Performance of Network Parallel Training in Artificial Neural Networks
Jan 18, 2017
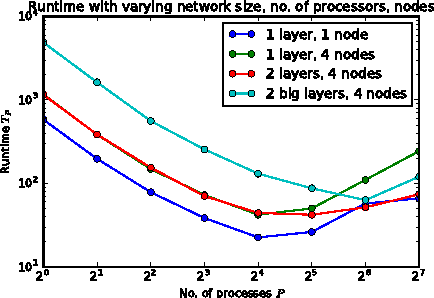

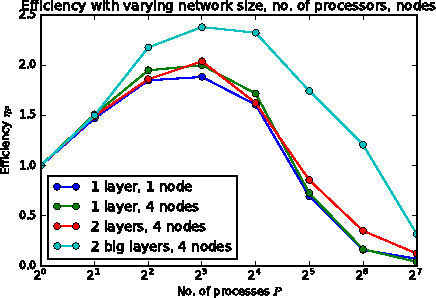
Artificial Neural Networks (ANNs) have received increasing attention in recent years with applications that span a wide range of disciplines including vital domains such as medicine, network security and autonomous transportation. However, neural network architectures are becoming increasingly complex and with an increasing need to obtain real-time results from such models, it has become pivotal to use parallelization as a mechanism for speeding up network training and deployment. In this work we propose an implementation of Network Parallel Training through Cannon's Algorithm for matrix multiplication. We show that increasing the number of processes speeds up training until the point where process communication costs become prohibitive; this point varies by network complexity. We also show through empirical efficiency calculations that the speedup obtained is superlinear.