 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Performance of Network Parallel Training in Artificial Neural Networks
Paper and Code
Jan 18, 2017
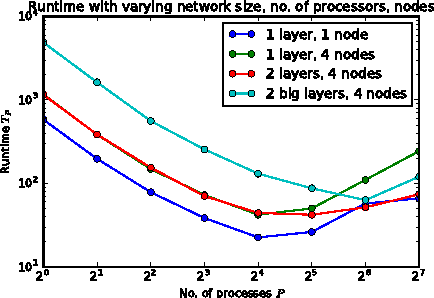

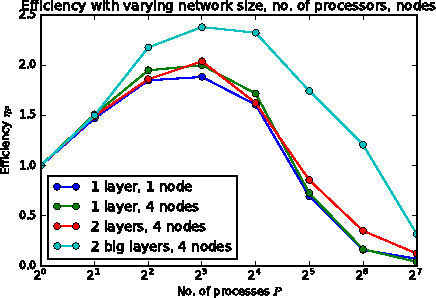
Artificial Neural Networks (ANNs) have received increasing attention in recent years with applications that span a wide range of disciplines including vital domains such as medicine, network security and autonomous transportation. However, neural network architectures are becoming increasingly complex and with an increasing need to obtain real-time results from such models, it has become pivotal to use parallelization as a mechanism for speeding up network training and deployment. In this work we propose an implementation of Network Parallel Training through Cannon's Algorithm for matrix multiplication. We show that increasing the number of processes speeds up training until the point where process communication costs become prohibitive; this point varies by network complexity. We also show through empirical efficiency calculations that the speedup obtained is superlinear.