 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassical and Deep Reinforcement Learning Inventory Control Policies for Pharmaceutical Supply Chains with Perishability and Non-Stationarity
Jan 18, 2025We study inventory control policies for pharmaceutical supply chains, addressing challenges such as perishability, yield uncertainty, and non-stationary demand, combined with batching constraints, lead times, and lost sales. Collaborating with Bristol-Myers Squibb (BMS), we develop a realistic case study incorporating these factors and benchmark three policies--order-up-to (OUT), projected inventory level (PIL), and deep reinforcement learning (DRL) using the proximal policy optimization (PPO) algorithm--against a BMS baseline based on human expertise. We derive and validate bounds-based procedures for optimizing OUT and PIL policy parameters and propose a methodology for estimating projected inventory levels, which are also integrated into the DRL policy with demand forecasts to improve decision-making under non-stationarity. Compared to a human-driven policy, which avoids lost sales through higher holding costs, all three implemented policies achieve lower average costs but exhibit greater cost variability. While PIL demonstrates robust and consistent performance, OUT struggles under high lost sales costs, and PPO excels in complex and variable scenarios but requires significant computational effort. The findings suggest that while DRL shows potential, it does not outperform classical policies in all numerical experiments, highlighting 1) the need to integrate diverse policies to manage pharmaceutical challenges effectively, based on the current state-of-the-art, and 2) that practical problems in this domain seem to lack a single policy class that yields universally acceptable performance.
Deep Reinforcement Learning for a Two-Echelon Supply Chain with Seasonal Demand
Apr 20, 2022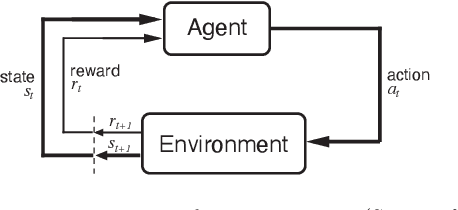

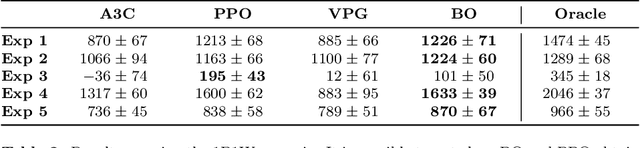
This paper leverages recent developments in reinforcement learning and deep learning to solve the supply chain inventory management problem, a complex sequential decision-making problem consisting of determining the optimal quantity of products to produce and ship to different warehouses over a given time horizon. A mathematical formulation of the stochastic two-echelon supply chain environment is given, which allows an arbitrary number of warehouses and product types to be managed. Additionally, an open-source library that interfaces with deep reinforcement learning algorithms is developed and made publicly available for solving the inventory management problem. Performances achieved by state-of-the-art deep reinforcement learning algorithms are compared through a rich set of numerical experiments on synthetically generated data. The experimental plan is designed and performed, including different structures, topologies, demands, capacities, and costs of the supply chain. Results show that the PPO algorithm adapts very well to different characteristics of the environment. The VPG algorithm almost always converges to a local maximum, even if it typically achieves an acceptable performance level. Finally, A3C is the fastest algorithm, but just like the VPG, it never achieves the best performance when compared to PPO. In conclusion, numerical experiments show that deep reinforcement learning performs consistently better than standard inventory management strategies, such as the static (s, Q)-policy. Thus, it can be considered a practical and effective option for solving real-world instances of the stochastic two-echelon supply chain problem.
Hard and Soft EM in Bayesian Network Learning from Incomplete Data
Dec 09, 2020
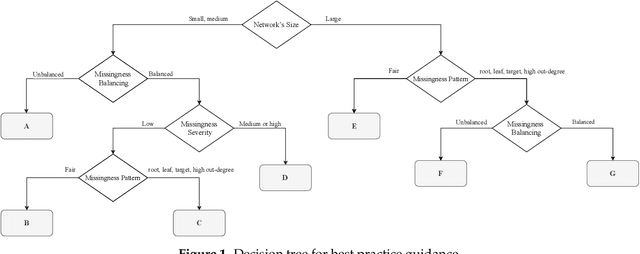
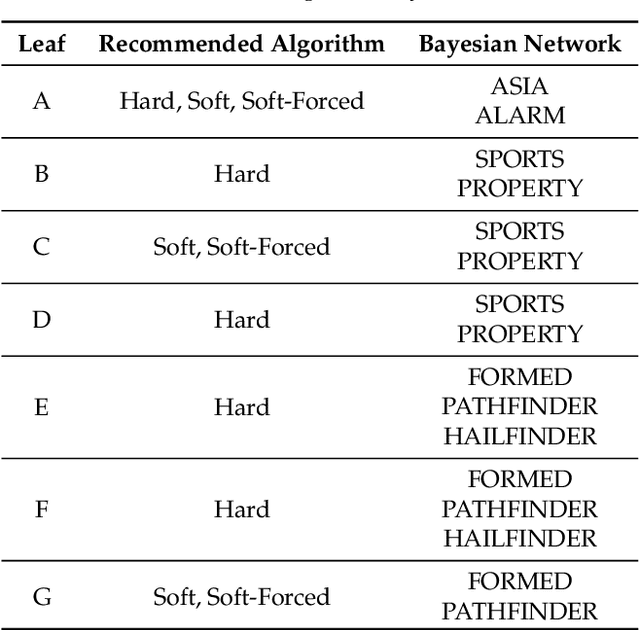
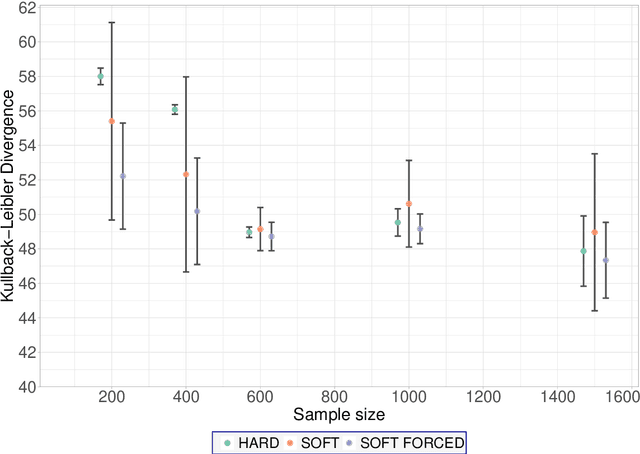
Incomplete data are a common feature in many domains, from clinical trials to industrial applications. Bayesian networks (BNs) are often used in these domains because of their graphical and causal interpretations. BN parameter learning from incomplete data is usually implemented with the Expectation-Maximisation algorithm (EM), which computes the relevant sufficient statistics ("soft EM") using belief propagation. Similarly, the Structural Expectation-Maximisation algorithm (Structural EM) learns the network structure of the BN from those sufficient statistics using algorithms designed for complete data. However, practical implementations of parameter and structure learning often impute missing data ("hard EM") to compute sufficient statistics instead of using belief propagation, for both ease of implementation and computational speed. In this paper, we investigate the question: what is the impact of using imputation instead of belief propagation on the quality of the resulting BNs? From a simulation study using synthetic data and reference BNs, we find that it is possible to recommend one approach over the other in several scenarios based on the characteristics of the data. We then use this information to build a simple decision tree to guide practitioners in choosing the EM algorithm best suited to their problem.
* 16 pages, 5 figures