 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Panels to Prose: Generating Literary Narratives from Comics
Mar 30, 2025Comics have long been a popular form of storytelling, offering visually engaging narratives that captivate audiences worldwide. However, the visual nature of comics presents a significant barrier for visually impaired readers, limiting their access to these engaging stories. In this work, we provide a pragmatic solution to this accessibility challenge by developing an automated system that generates text-based literary narratives from manga comics. Our approach aims to create an evocative and immersive prose that not only conveys the original narrative but also captures the depth and complexity of characters, their interactions, and the vivid settings in which they reside. To this end we make the following contributions: (1) We present a unified model, Magiv3, that excels at various functional tasks pertaining to comic understanding, such as localising panels, characters, texts, and speech-bubble tails, performing OCR, grounding characters etc. (2) We release human-annotated captions for over 3300 Japanese comic panels, along with character grounding annotations, and benchmark large vision-language models in their ability to understand comic images. (3) Finally, we demonstrate how integrating large vision-language models with Magiv3, can generate seamless literary narratives that allows visually impaired audiences to engage with the depth and richness of comic storytelling.
Tails Tell Tales: Chapter-Wide Manga Transcriptions with Character Names
Aug 01, 2024Enabling engagement of manga by visually impaired individuals presents a significant challenge due to its inherently visual nature. With the goal of fostering accessibility, this paper aims to generate a dialogue transcript of a complete manga chapter, entirely automatically, with a particular emphasis on ensuring narrative consistency. This entails identifying (i) what is being said, i.e., detecting the texts on each page and classifying them into essential vs non-essential, and (ii) who is saying it, i.e., attributing each dialogue to its speaker, while ensuring the same characters are named consistently throughout the chapter. To this end, we introduce: (i) Magiv2, a model that is capable of generating high-quality chapter-wide manga transcripts with named characters and significantly higher precision in speaker diarisation over prior works; (ii) an extension of the PopManga evaluation dataset, which now includes annotations for speech-bubble tail boxes, associations of text to corresponding tails, classifications of text as essential or non-essential, and the identity for each character box; and (iii) a new character bank dataset, which comprises over 11K characters from 76 manga series, featuring 11.5K exemplar character images in total, as well as a list of chapters in which they appear. The code, trained model, and both datasets can be found at: https://github.com/ragavsachdeva/magi
The Manga Whisperer: Automatically Generating Transcriptions for Comics
Jan 18, 2024In the past few decades, Japanese comics, commonly referred to as Manga, have transcended both cultural and linguistic boundaries to become a true worldwide sensation. Yet, the inherent reliance on visual cues and illustration within manga renders it largely inaccessible to individuals with visual impairments. In this work, we seek to address this substantial barrier, with the aim of ensuring that manga can be appreciated and actively engaged by everyone. Specifically, we tackle the problem of diarisation i.e. generating a transcription of who said what and when, in a fully automatic way. To this end, we make the following contributions: (1) we present a unified model, Magi, that is able to (a) detect panels, text boxes and character boxes, (b) cluster characters by identity (without knowing the number of clusters apriori), and (c) associate dialogues to their speakers; (2) we propose a novel approach that is able to sort the detected text boxes in their reading order and generate a dialogue transcript; (3) we annotate an evaluation benchmark for this task using publicly available [English] manga pages. The code, evaluation datasets and the pre-trained model can be found at: https://github.com/ragavsachdeva/magi.
The Change You Want to See (Now in 3D)
Sep 11, 2023



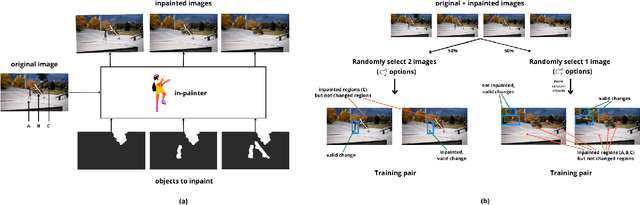
The goal of this paper is to detect what has changed, if anything, between two "in the wild" images of the same 3D scene acquired from different camera positions and at different temporal instances. The open-set nature of this problem, occlusions/dis-occlusions due to the shift in viewpoint, and the lack of suitable training datasets, presents substantial challenges in devising a solution. To address this problem, we contribute a change detection model that is trained entirely on synthetic data and is class-agnostic, yet it is performant out-of-the-box on real world images without requiring fine-tuning. Our solution entails a "register and difference" approach that leverages self-supervised frozen embeddings and feature differences, which allows the model to generalise to a wide variety of scenes and domains. The model is able to operate directly on two RGB images, without requiring access to ground truth camera intrinsics, extrinsics, depth maps, point clouds, or additional before-after images. Finally, we collect and release a new evaluation dataset consisting of real-world image pairs with human-annotated differences and demonstrate the efficacy of our method. The code, datasets and pre-trained model can be found at: https://github.com/ragavsachdeva/CYWS-3D
The Change You Want to See
Sep 28, 2022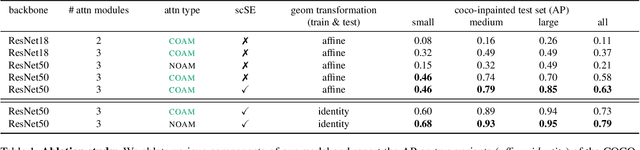
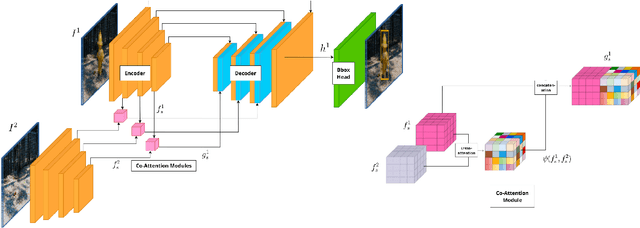

We live in a dynamic world where things change all the time. Given two images of the same scene, being able to automatically detect the changes in them has practical applications in a variety of domains. In this paper, we tackle the change detection problem with the goal of detecting "object-level" changes in an image pair despite differences in their viewpoint and illumination. To this end, we make the following four contributions: (i) we propose a scalable methodology for obtaining a large-scale change detection training dataset by leveraging existing object segmentation benchmarks; (ii) we introduce a co-attention based novel architecture that is able to implicitly determine correspondences between an image pair and find changes in the form of bounding box predictions; (iii) we contribute four evaluation datasets that cover a variety of domains and transformations, including synthetic image changes, real surveillance images of a 3D scene, and synthetic 3D scenes with camera motion; (iv) we evaluate our model on these four datasets and demonstrate zero-shot and beyond training transformation generalization.
Robotic Vision for Space Mining
Sep 30, 2021

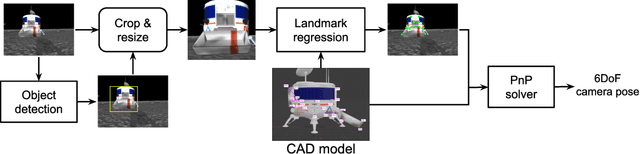

Future Moon bases will likely be constructed using resources mined from the surface of the Moon. The difficulty of maintaining a human workforce on the Moon and communications lag with Earth means that mining will need to be conducted using collaborative robots with a high degree of autonomy. In this paper, we explore the utility of robotic vision towards addressing several major challenges in autonomous mining in the lunar environment: lack of satellite positioning systems, navigation in hazardous terrain, and delicate robot interactions. Specifically, we describe and report the results of robotic vision algorithms that we developed for Phase 2 of the NASA Space Robotics Challenge, which was framed in the context of autonomous collaborative robots for mining on the Moon. The competition provided a simulated lunar environment that exhibits the complexities alluded to above. We show how machine learning-enabled vision could help alleviate the challenges posed by the lunar environment. A robust multi-robot coordinator was also developed to achieve long-term operation and effective collaboration between robots.
ScanMix: Learning from Severe Label Noise via Semantic Clustering and Semi-Supervised Learning
Mar 21, 2021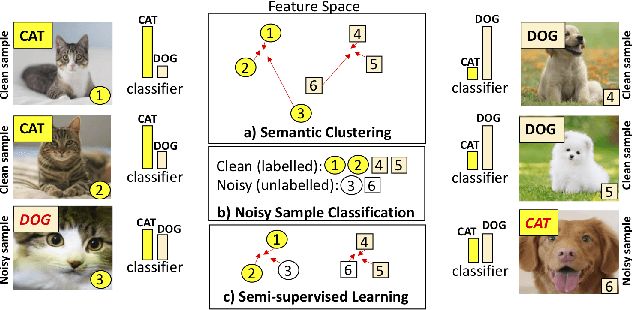
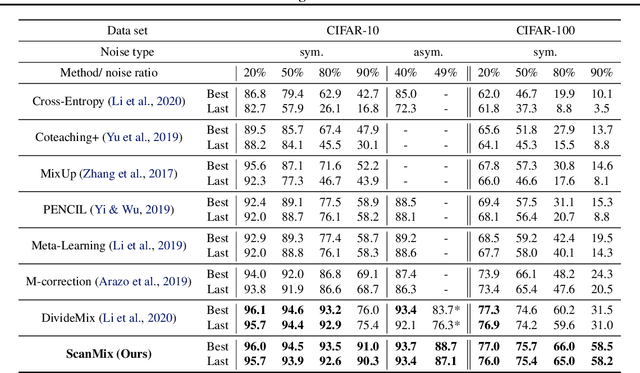
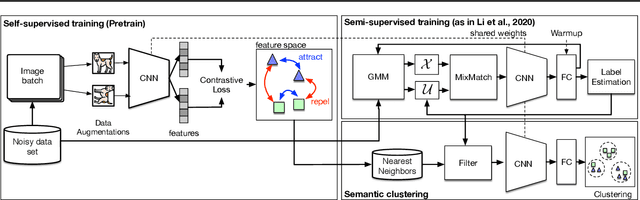
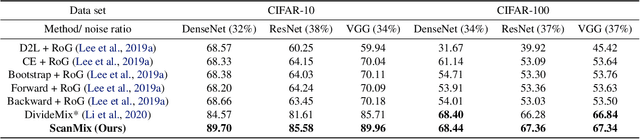
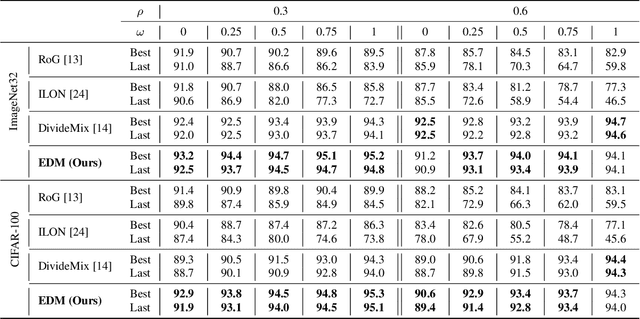
In this paper, we address the problem of training deep neural networks in the presence of severe label noise. Our proposed training algorithm ScanMix, combines semantic clustering with semi-supervised learning (SSL) to improve the feature representations and enable an accurate identification of noisy samples, even in severe label noise scenarios. To be specific, ScanMix is designed based on the expectation maximisation (EM) framework, where the E-step estimates the value of a latent variable to cluster the training images based on their appearance representations and classification results, and the M-step optimises the SSL classification and learns effective feature representations via semantic clustering. In our evaluations, we show state-of-the-art results on standard benchmarks for symmetric, asymmetric and semantic label noise on CIFAR-10 and CIFAR-100, as well as large scale real label noise on WebVision. Most notably, for the benchmarks contaminated with large noise rates (80% and above), our results are up to 27% better than the related work. The code is available at https://github.com/ragavsachdeva/ScanMix.
LongReMix: Robust Learning with High Confidence Samples in a Noisy Label Environment
Mar 06, 2021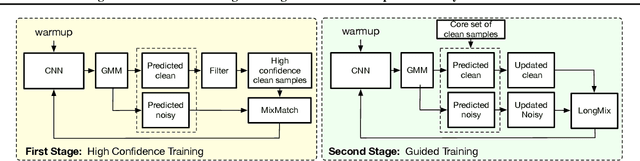
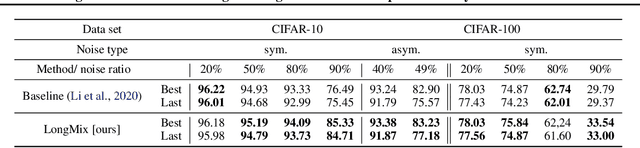
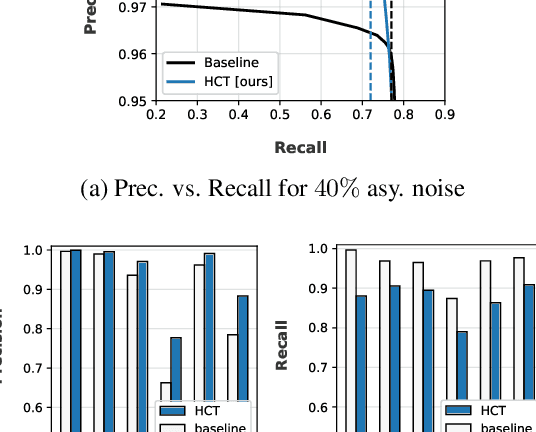
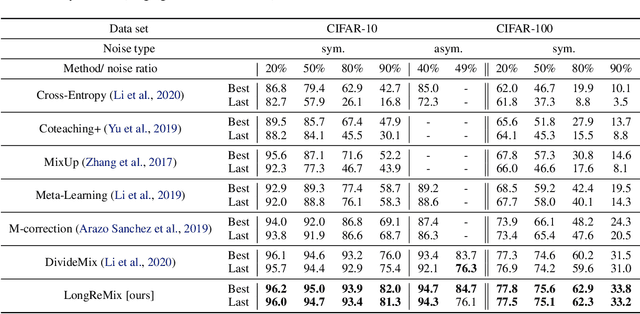
Deep neural network models are robust to a limited amount of label noise, but their ability to memorise noisy labels in high noise rate problems is still an open issue. The most competitive noisy-label learning algorithms rely on a 2-stage process comprising an unsupervised learning to classify training samples as clean or noisy, followed by a semi-supervised learning that minimises the empirical vicinal risk (EVR) using a labelled set formed by samples classified as clean, and an unlabelled set with samples classified as noisy. In this paper, we hypothesise that the generalisation of such 2-stage noisy-label learning methods depends on the precision of the unsupervised classifier and the size of the training set to minimise the EVR. We empirically validate these two hypotheses and propose the new 2-stage noisy-label training algorithm LongReMix. We test LongReMix on the noisy-label benchmarks CIFAR-10, CIFAR-100, WebVision, Clothing1M, and Food101-N. The results show that our LongReMix generalises better than competing approaches, particularly in high label noise problems. Furthermore, our approach achieves state-of-the-art performance in most datasets. The code will be available upon paper acceptance.
EvidentialMix: Learning with Combined Open-set and Closed-set Noisy Labels
Nov 11, 2020

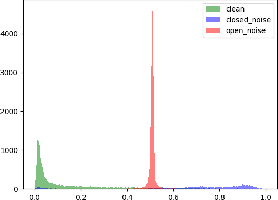
The efficacy of deep learning depends on large-scale data sets that have been carefully curated with reliable data acquisition and annotation processes. However, acquiring such large-scale data sets with precise annotations is very expensive and time-consuming, and the cheap alternatives often yield data sets that have noisy labels. The field has addressed this problem by focusing on training models under two types of label noise: 1) closed-set noise, where some training samples are incorrectly annotated to a training label other than their known true class; and 2) open-set noise, where the training set includes samples that possess a true class that is (strictly) not contained in the set of known training labels. In this work, we study a new variant of the noisy label problem that combines the open-set and closed-set noisy labels, and introduce a benchmark evaluation to assess the performance of training algorithms under this setup. We argue that such problem is more general and better reflects the noisy label scenarios in practice. Furthermore, we propose a novel algorithm, called EvidentialMix, that addresses this problem and compare its performance with the state-of-the-art methods for both closed-set and open-set noise on the proposed benchmark. Our results show that our method produces superior classification results and better feature representations than previous state-of-the-art methods. The code is available at https://github.com/ragavsachdeva/EvidentialMix.
The Dynamic Travelling Thief Problem: Benchmarks and Performance of Evolutionary Algorithms
May 10, 2020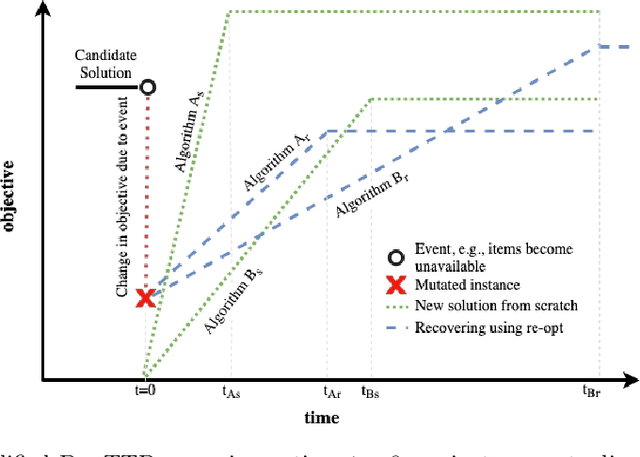
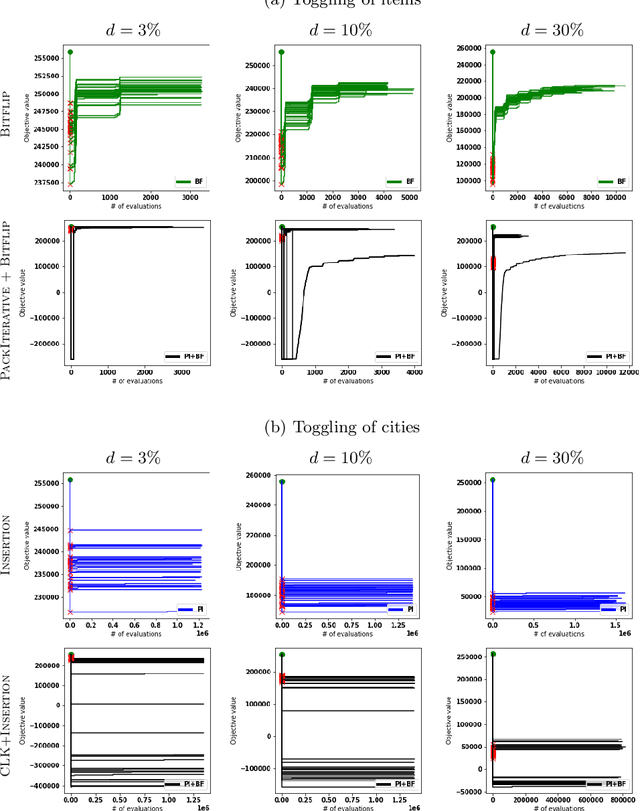
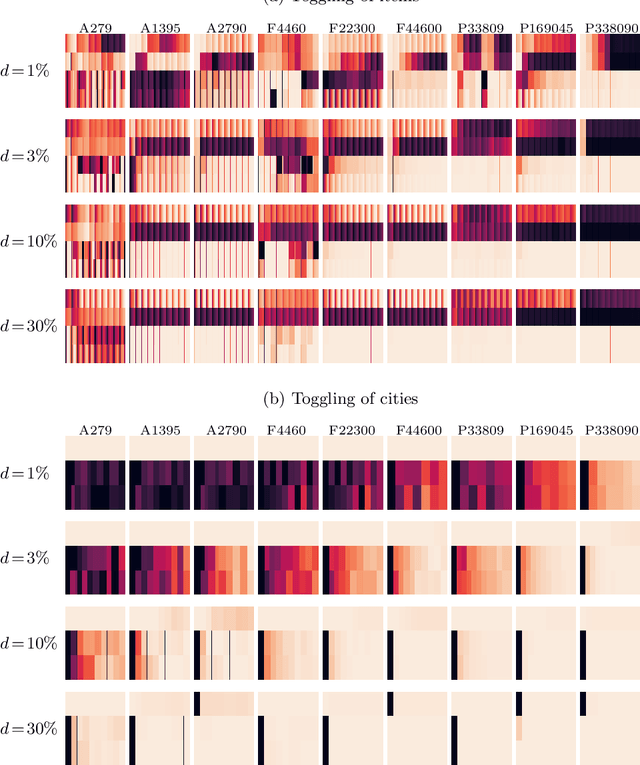
Many real-world optimisation problems involve dynamic and stochastic components. While problems with multiple interacting components are omnipresent in inherently dynamic domains like supply-chain optimisation and logistics, most research on dynamic problems focuses on single-component problems. With this article, we define a number of scenarios based on the Travelling Thief Problem to enable research on the effect of dynamic changes to sub-components. Our investigations of 72 scenarios and seven algorithms show that -- depending on the instance, the magnitude of the change, and the algorithms in the portfolio -- it is preferable to either restart the optimisation from scratch or to continue with the previously valid solutions.