 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAycromo: An Open-Source Platform for Automatic Chromosome Detection in Metaphase Images Based on Deep Learning
Apr 27, 2026Chromosome analysis is a fundamental step in the diagnosis of genetic diseases, but the manual karyotyping workflow is time-consuming and heavily dependent on expert specialists, often requiring several days per patient. Although Deep Learning models have achieved high performance in chromosome detection, most proposed solutions remain restricted to research prototypes or lack graphical interfaces suitable for clinical use. In this work, we present Aycromo, an open-source desktop platform for AI-assisted cytogenetic analysis. Built on Electron and ONNX Runtime, the tool allows cytogeneticists to load pre-trained models, compare architectures through an integrated benchmarking module, and manually correct detections via an interactive annotation interface, all without command-line interaction. Preliminary experiments on metaphase images from the CRCN-NE dataset demonstrate that YOLOv11 achieves 99.40% mAP@50, while the platform reduces per-slide analysis to seconds
Does Machine Unlearning Preserve Clinical Safety? A Risk Analysis for Medical Image Classification
Apr 26, 2026The application of Deep Learning in medical diagnosis must balance patient safety with compliance with data protection regulations. Machine Unlearning enables the selective removal of training data from deployed models. However, most methods are validated primarily through efficiency and privacy-oriented metrics, with limited attention to clinically asymmetric error costs. In this work, we investigate how unlearning affects clinical risk in binary medical image classification. We show that standard unlearning strategies (Fine-Tuning, Random Labeling, and SalUn) may reduce test utility while increasing false-negative rates, thereby amplifying clinical risk. To mitigate this, we propose SalUn-CRA (Clinical Risk-Aware), a variant of SalUn that replaces random relabeling with entropy-based forgetting for malignant samples in the forget set, preventing the model from learning harmful benign associations. We evaluate on DermaMNIST and PathMNIST medical image datasets under 20% and 50% data removal. Using Global Risk metrics with asymmetric costs, SalUn-CRA achieves lower or comparable clinical risk to full retraining while preserving unlearning effectiveness. These results suggest that clinical risk should be an integral component of unlearning validation in medical systems.
Risk-Aware Robust Learning: Reducing Clinical Risk under Label Noise in Medical Image Classification
Apr 26, 2026Noisy labels are a pervasive challenge in medical image classification, where annotation errors arise from inter-observer variability and diagnostic ambiguity. Although several noise-robust learning methods have been proposed, their evaluation predominantly relies on accuracy-oriented metrics, overlooking the clinical implications of asymmetric error costs. In medical diagnosis, a false negative (missed disease) carries substantially higher consequences than a false positive (false alarm), as delayed treatment can directly impact patient outcomes. In this work, we investigate whether noise-robust training methods preserve clinical safety under label noise. We conduct a systematic risk-aware evaluation of the state-of-the-art noise-robust methods Coteaching, DivideMix, UNICON, and a GMM-based filtering approach on binarized DermaMNIST and PathMNIST datasets under clean and label noise rates of 20%, and 40%. Beyond balanced accuracy, we adopt a cost-sensitive Global Risk formulation that explicitly penalizes false negatives. Our analysis reveals that the robustness of state-of-the-art methods does not guarantee clinical safety. Furthermore, we demonstrate that integrating cost-sensitive optimization into noise-robust training significantly reduces clinical risk, while mantaining model utility. These findings demonstrate that noise-robust learning must be evaluated through a clinical risk lens, and that combining robust training with cost-sensitive optimization can meaningfully reduce risk in noisy-label medical imaging scenarios.
ANNE: Adaptive Nearest Neighbors and Eigenvector-based Sample Selection for Robust Learning with Noisy Labels
Nov 03, 2024An important stage of most state-of-the-art (SOTA) noisy-label learning methods consists of a sample selection procedure that classifies samples from the noisy-label training set into noisy-label or clean-label subsets. The process of sample selection typically consists of one of the two approaches: loss-based sampling, where high-loss samples are considered to have noisy labels, or feature-based sampling, where samples from the same class tend to cluster together in the feature space and noisy-label samples are identified as anomalies within those clusters. Empirically, loss-based sampling is robust to a wide range of noise rates, while feature-based sampling tends to work effectively in particular scenarios, e.g., the filtering of noisy instances via their eigenvectors (FINE) sampling exhibits greater robustness in scenarios with low noise rates, and the K nearest neighbor (KNN) sampling mitigates better high noise-rate problems. This paper introduces the Adaptive Nearest Neighbors and Eigenvector-based (ANNE) sample selection methodology, a novel approach that integrates loss-based sampling with the feature-based sampling methods FINE and Adaptive KNN to optimize performance across a wide range of noise rate scenarios. ANNE achieves this integration by first partitioning the training set into high-loss and low-loss sub-groups using loss-based sampling. Subsequently, within the low-loss subset, sample selection is performed using FINE, while the high-loss subset employs Adaptive KNN for effective sample selection. We integrate ANNE into the noisy-label learning state of the art (SOTA) method SSR+, and test it on CIFAR-10/-100 (with symmetric, asymmetric and instance-dependent noise), Webvision and ANIMAL-10, where our method shows better accuracy than the SOTA in most experiments, with a competitive training time.
Recognizing Handwritten Mathematical Expressions of Vertical Addition and Subtraction
Aug 10, 2023



Handwritten Mathematical Expression Recognition (HMER) is a challenging task with many educational applications. Recent methods for HMER have been developed for complex mathematical expressions in standard horizontal format. However, solutions for elementary mathematical expression, such as vertical addition and subtraction, have not been explored in the literature. This work proposes a new handwritten elementary mathematical expression dataset composed of addition and subtraction expressions in a vertical format. We also extended the MNIST dataset to generate artificial images with this structure. Furthermore, we proposed a solution for offline HMER, able to recognize vertical addition and subtraction expressions. Our analysis evaluated the object detection algorithms YOLO v7, YOLO v8, YOLO-NAS, NanoDet and FCOS for identifying the mathematical symbols. We also proposed a transcription method to map the bounding boxes from the object detection stage to a mathematical expression in the LATEX markup sequence. Results show that our approach is efficient, achieving a high expression recognition rate. The code and dataset are available at https://github.com/Danielgol/HME-VAS
Improving Mass Detection in Mammography Images: A Study of Weakly Supervised Learning and Class Activation Map Methods
Aug 07, 2023

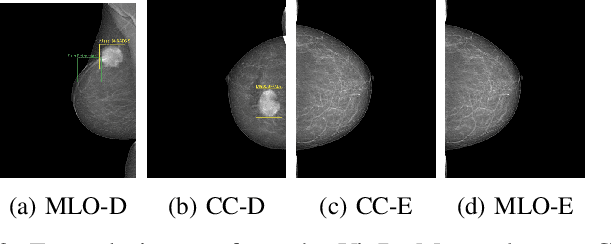

In recent years, weakly supervised models have aided in mass detection using mammography images, decreasing the need for pixel-level annotations. However, most existing models in the literature rely on Class Activation Maps (CAM) as the activation method, overlooking the potential benefits of exploring other activation techniques. This work presents a study that explores and compares different activation maps in conjunction with state-of-the-art methods for weakly supervised training in mammography images. Specifically, we investigate CAM, GradCAM, GradCAM++, XGradCAM, and LayerCAM methods within the framework of the GMIC model for mass detection in mammography images. The evaluation is conducted on the VinDr-Mammo dataset, utilizing the metrics Accuracy, True Positive Rate (TPR), False Negative Rate (FNR), and False Positive Per Image (FPPI). Results show that using different strategies of activation maps during training and test stages leads to an improvement of the model. With this strategy, we improve the results of the GMIC method, decreasing the FPPI value and increasing TPR.
A Study on the Impact of Data Augmentation for Training Convolutional Neural Networks in the Presence of Noisy Labels
Aug 23, 2022



Label noise is common in large real-world datasets, and its presence harms the training process of deep neural networks. Although several works have focused on the training strategies to address this problem, there are few studies that evaluate the impact of data augmentation as a design choice for training deep neural networks. In this work, we analyse the model robustness when using different data augmentations and their improvement on the training with the presence of noisy labels. We evaluate state-of-the-art and classical data augmentation strategies with different levels of synthetic noise for the datasets MNist, CIFAR-10, CIFAR-100, and the real-world dataset Clothing1M. We evaluate the methods using the accuracy metric. Results show that the appropriate selection of data augmentation can drastically improve the model robustness to label noise, increasing up to 177.84% of relative best test accuracy compared to the baseline with no augmentation, and an increase of up to 6% in absolute value with the state-of-the-art DivideMix training strategy.
PropMix: Hard Sample Filtering and Proportional MixUp for Learning with Noisy Labels
Oct 22, 2021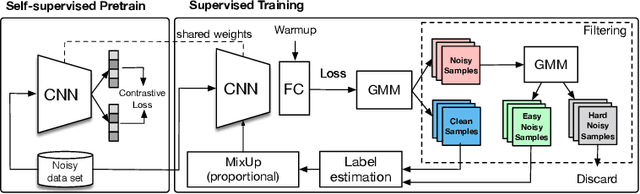



The most competitive noisy label learning methods rely on an unsupervised classification of clean and noisy samples, where samples classified as noisy are re-labelled and "MixMatched" with the clean samples. These methods have two issues in large noise rate problems: 1) the noisy set is more likely to contain hard samples that are in-correctly re-labelled, and 2) the number of samples produced by MixMatch tends to be reduced because it is constrained by the small clean set size. In this paper, we introduce the learning algorithm PropMix to handle the issues above. PropMix filters out hard noisy samples, with the goal of increasing the likelihood of correctly re-labelling the easy noisy samples. Also, PropMix places clean and re-labelled easy noisy samples in a training set that is augmented with MixUp, removing the clean set size constraint and including a large proportion of correctly re-labelled easy noisy samples. We also include self-supervised pre-training to improve robustness to high noisy label scenarios. Our experiments show that PropMix has state-of-the-art (SOTA) results on CIFAR-10/-100(with symmetric, asymmetric and semantic label noise), Red Mini-ImageNet (from the Controlled Noisy Web Labels), Clothing1M and WebVision. In severe label noise bench-marks, our results are substantially better than other methods. The code is available athttps://github.com/filipe-research/PropMix.
LongReMix: Robust Learning with High Confidence Samples in a Noisy Label Environment
Mar 06, 2021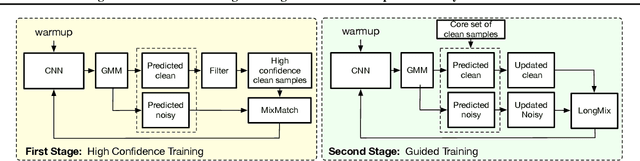
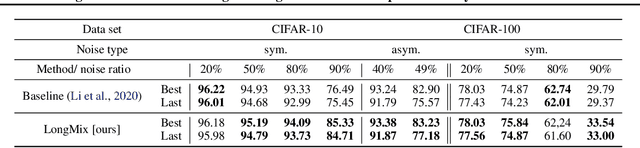
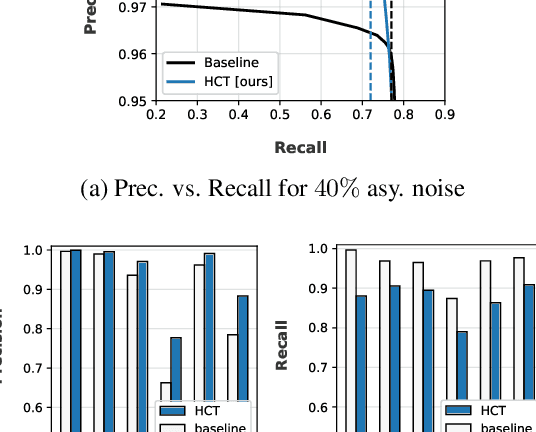
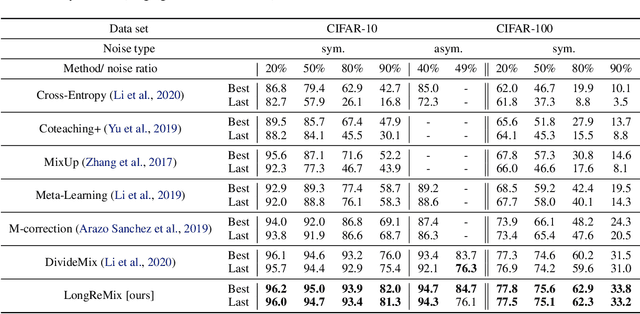
Deep neural network models are robust to a limited amount of label noise, but their ability to memorise noisy labels in high noise rate problems is still an open issue. The most competitive noisy-label learning algorithms rely on a 2-stage process comprising an unsupervised learning to classify training samples as clean or noisy, followed by a semi-supervised learning that minimises the empirical vicinal risk (EVR) using a labelled set formed by samples classified as clean, and an unlabelled set with samples classified as noisy. In this paper, we hypothesise that the generalisation of such 2-stage noisy-label learning methods depends on the precision of the unsupervised classifier and the size of the training set to minimise the EVR. We empirically validate these two hypotheses and propose the new 2-stage noisy-label training algorithm LongReMix. We test LongReMix on the noisy-label benchmarks CIFAR-10, CIFAR-100, WebVision, Clothing1M, and Food101-N. The results show that our LongReMix generalises better than competing approaches, particularly in high label noise problems. Furthermore, our approach achieves state-of-the-art performance in most datasets. The code will be available upon paper acceptance.
Noisy Label Learning for Large-scale Medical Image Classification
Mar 06, 2021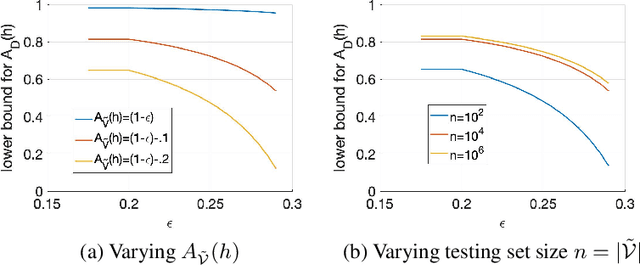
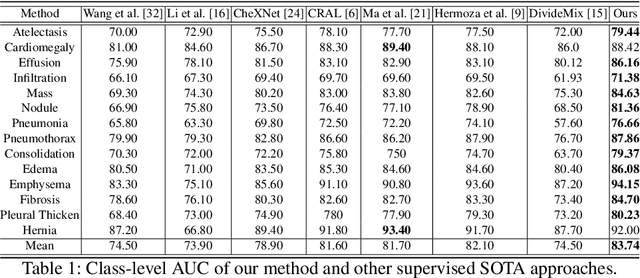
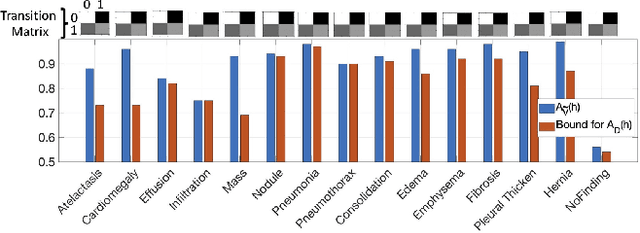

The classification accuracy of deep learning models depends not only on the size of their training sets, but also on the quality of their labels. In medical image classification, large-scale datasets are becoming abundant, but their labels will be noisy when they are automatically extracted from radiology reports using natural language processing tools. Given that deep learning models can easily overfit these noisy-label samples, it is important to study training approaches that can handle label noise. In this paper, we adapt a state-of-the-art (SOTA) noisy-label multi-class training approach to learn a multi-label classifier for the dataset Chest X-ray14, which is a large scale dataset known to contain label noise in the training set. Given that this dataset also has label noise in the testing set, we propose a new theoretically sound method to estimate the performance of the model on a hidden clean testing data, given the result on the noisy testing data. Using our clean data performance estimation, we notice that the majority of label noise on Chest X-ray14 is present in the class 'No Finding', which is intuitively correct because this is the most likely class to contain one or more of the 14 diseases due to labelling mistakes.