 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixed User-Centered Approach to Enable Augmented Intelligence in Intelligent Tutoring Systems: The Case of MathAIde app
Jul 31, 2025Integrating Artificial Intelligence in Education (AIED) aims to enhance learning experiences through technologies like Intelligent Tutoring Systems (ITS), offering personalized learning, increased engagement, and improved retention rates. However, AIED faces three main challenges: the critical role of teachers in the design process, the limitations and reliability of AI tools, and the accessibility of technological resources. Augmented Intelligence (AuI) addresses these challenges by enhancing human capabilities rather than replacing them, allowing systems to suggest solutions. In contrast, humans provide final assessments, thus improving AI over time. In this sense, this study focuses on designing, developing, and evaluating MathAIde, an ITS that corrects mathematics exercises using computer vision and AI and provides feedback based on photos of student work. The methodology included brainstorming sessions with potential users, high-fidelity prototyping, A/B testing, and a case study involving real-world classroom environments for teachers and students. Our research identified several design possibilities for implementing AuI in ITSs, emphasizing a balance between user needs and technological feasibility. Prioritization and validation through prototyping and testing highlighted the importance of efficiency metrics, ultimately leading to a solution that offers pre-defined remediation alternatives for teachers. Real-world deployment demonstrated the usefulness of the proposed solution. Our research contributes to the literature by providing a usable, teacher-centered design approach that involves teachers in all design phases. As a practical implication, we highlight that the user-centered design approach increases the usefulness and adoption potential of AIED systems, especially in resource-limited environments.
A new visual quality metric for Evaluating the performance of multidimensional projections
Jul 23, 2024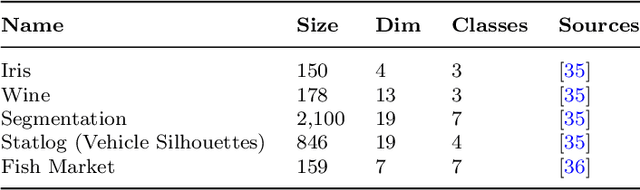
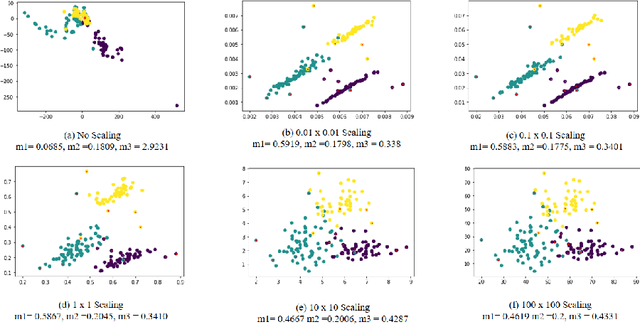
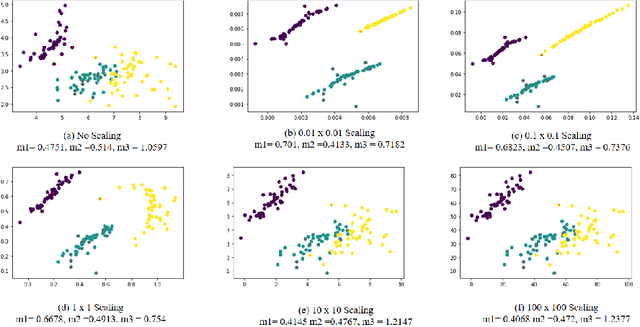
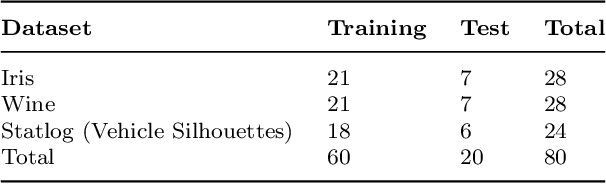
Multidimensional projections (MP) are among the most essential approaches in the visual analysis of multidimensional data. It transforms multidimensional data into two-dimensional representations that may be shown as scatter plots while preserving their similarity with the original data. Human visual perception is frequently used to evaluate the quality of MP. In this work, we propose to study and improve on a well-known map called Local Affine Multidimensional Projection (LAMP), which takes a multidimensional instance and embeds it in Cartesian space via moving least squares deformation. We propose a new visual quality metric based on human perception. The new metric combines three previously used metrics: silhouette coefficient, neighborhood preservation, and silhouette ratio. We show that the proposed metric produces more precise results in analyzing the quality of MP than other previously used metrics. Finally, we describe an algorithm that attempts to overcome a limitation of the LAMP method which requires a similar scale for control points and their counterparts in the Cartesian space.
Recognizing Handwritten Mathematical Expressions of Vertical Addition and Subtraction
Aug 10, 2023



Handwritten Mathematical Expression Recognition (HMER) is a challenging task with many educational applications. Recent methods for HMER have been developed for complex mathematical expressions in standard horizontal format. However, solutions for elementary mathematical expression, such as vertical addition and subtraction, have not been explored in the literature. This work proposes a new handwritten elementary mathematical expression dataset composed of addition and subtraction expressions in a vertical format. We also extended the MNIST dataset to generate artificial images with this structure. Furthermore, we proposed a solution for offline HMER, able to recognize vertical addition and subtraction expressions. Our analysis evaluated the object detection algorithms YOLO v7, YOLO v8, YOLO-NAS, NanoDet and FCOS for identifying the mathematical symbols. We also proposed a transcription method to map the bounding boxes from the object detection stage to a mathematical expression in the LATEX markup sequence. Results show that our approach is efficient, achieving a high expression recognition rate. The code and dataset are available at https://github.com/Danielgol/HME-VAS
User-oriented Natural Human-Robot Control with Thin-Plate Splines and LRCN
May 24, 2021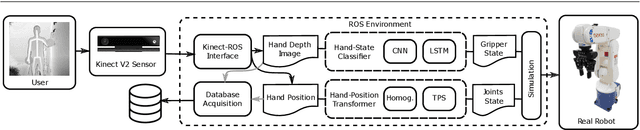
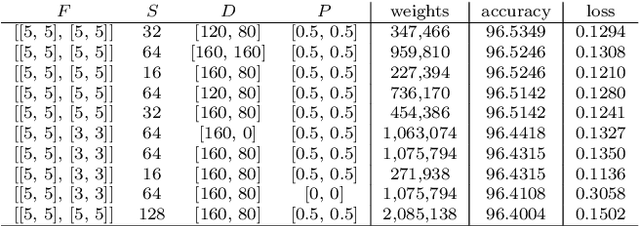
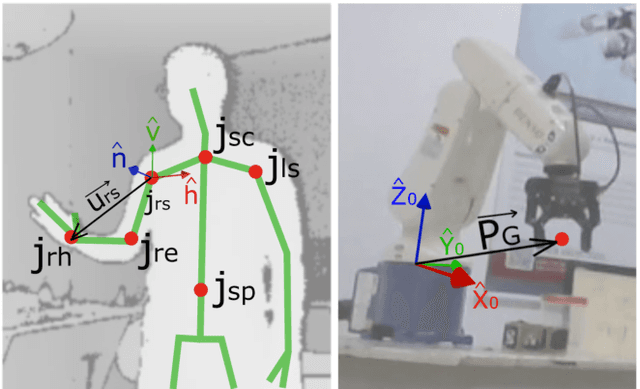
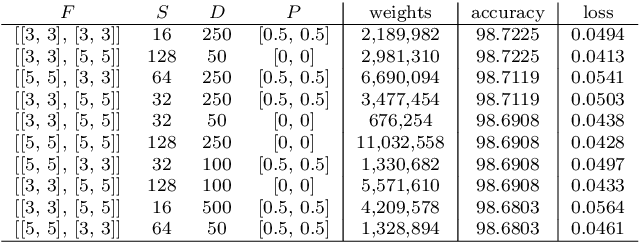
We propose a real-time vision-based teleoperation approach for robotic arms that employs a single depth-based camera, exempting the user from the need for any wearable devices. By employing a natural user interface, this novel approach leverages the conventional fine-tuning control, turning it into a direct body pose capture process. The proposed approach is comprised of two main parts. The first is a nonlinear customizable pose mapping based on Thin-Plate Splines (TPS), to directly transfer human body motion to robotic arm motion in a nonlinear fashion, thus allowing matching dissimilar bodies with different workspace shapes and kinematic constraints. The second is a Deep Neural Network hand-state classifier based on Long-term Recurrent Convolutional Networks (LRCN) that exploits the temporal coherence of the acquired depth data. We validate, evaluate and compare our approach through both classical cross-validation experiments of the proposed hand state classifier; and user studies over a set of practical experiments involving variants of pick-and-place and manufacturing tasks. Results revealed that LRCN networks outperform single image Convolutional Neural Networks; and that users' learning curves were steep, thus allowing the successful completion of the proposed tasks. When compared to a previous approach, the TPS approach revealed no increase in task complexity and similar times of completion, while providing more precise operation in regions closer to workspace boundaries.
LRCN-RetailNet: A recurrent neural network architecture for accurate people counting
May 12, 2020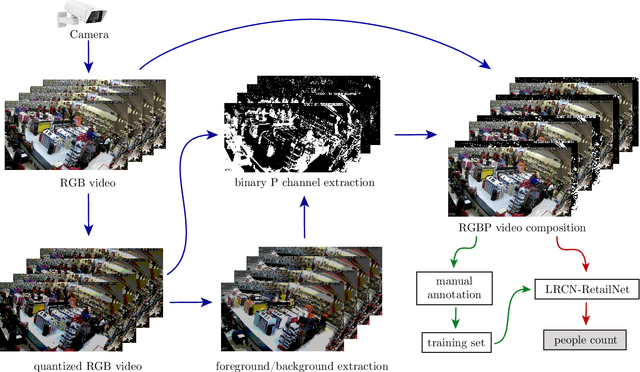
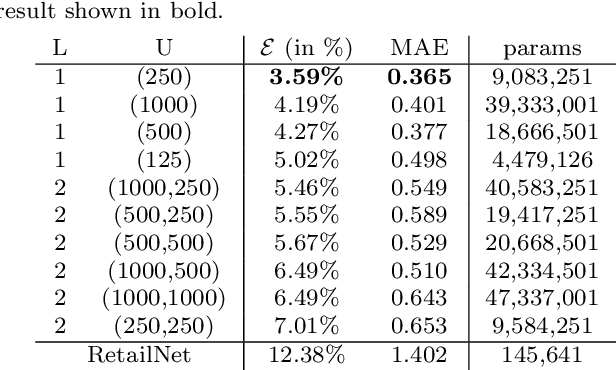
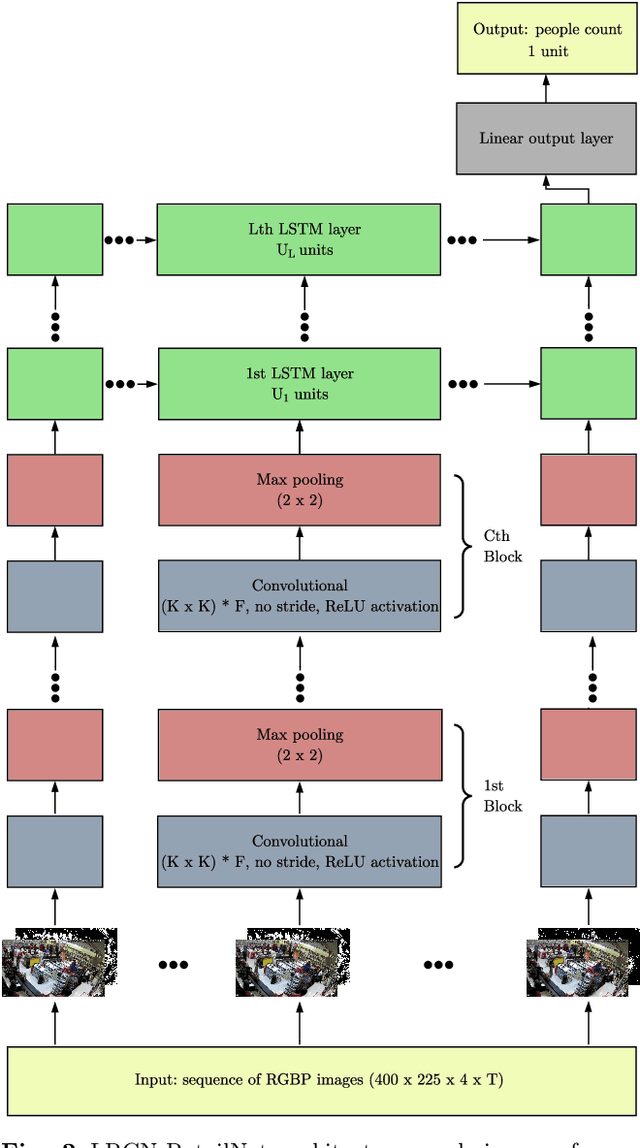
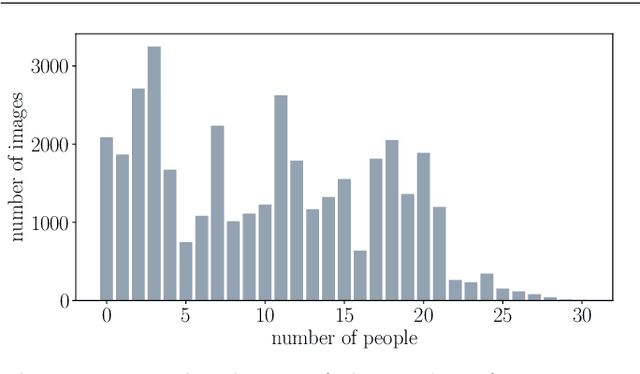
Measuring and analyzing the flow of customers in retail stores is essential for a retailer to better comprehend customers' behavior and support decision-making. Nevertheless, not much attention has been given to the development of novel technologies for automatic people counting. We introduce LRCN-RetailNet: a recurrent neural network architecture capable of learning a non-linear regression model and accurately predicting the people count from videos captured by low-cost surveillance cameras. The input video format follows the recently proposed RGBP image format, which is comprised of color and people (foreground) information. Our architecture is capable of considering two relevant aspects: spatial features extracted through convolutional layers from the RGBP images; and the temporal coherence of the problem, which is exploited by recurrent layers. We show that, through a supervised learning approach, the trained models are capable of predicting the people count with high accuracy. Additionally, we present and demonstrate that a straightforward modification of the methodology is effective to exclude salespeople from the people count. Comprehensive experiments were conducted to validate, evaluate and compare the proposed architecture. Results corroborated that LRCN-RetailNet remarkably outperforms both the previous RetailNet architecture, which was limited to evaluating a single image per iteration; and a state-of-the-art neural network for object detection. Finally, computational performance experiments confirmed that the entire methodology is effective to estimate people count in real-time.