 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Label Learning for Large-scale Medical Image Classification
Paper and Code
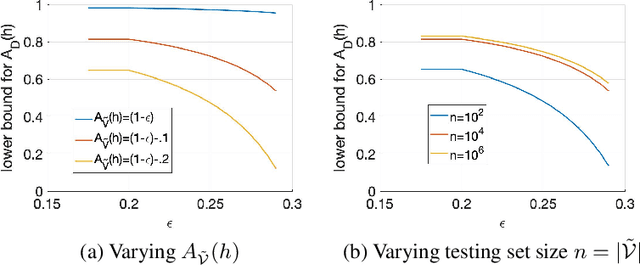
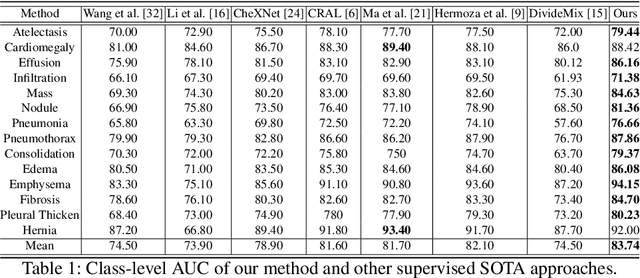
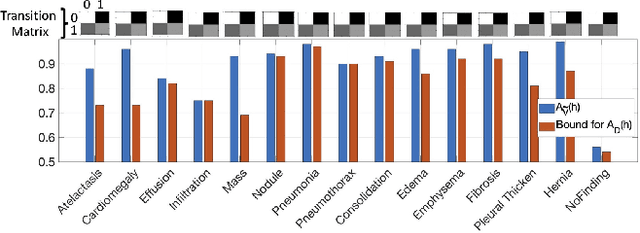

The classification accuracy of deep learning models depends not only on the size of their training sets, but also on the quality of their labels. In medical image classification, large-scale datasets are becoming abundant, but their labels will be noisy when they are automatically extracted from radiology reports using natural language processing tools. Given that deep learning models can easily overfit these noisy-label samples, it is important to study training approaches that can handle label noise. In this paper, we adapt a state-of-the-art (SOTA) noisy-label multi-class training approach to learn a multi-label classifier for the dataset Chest X-ray14, which is a large scale dataset known to contain label noise in the training set. Given that this dataset also has label noise in the testing set, we propose a new theoretically sound method to estimate the performance of the model on a hidden clean testing data, given the result on the noisy testing data. Using our clean data performance estimation, we notice that the majority of label noise on Chest X-ray14 is present in the class 'No Finding', which is intuitively correct because this is the most likely class to contain one or more of the 14 diseases due to labelling mistakes.