 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidentialMix: Learning with Combined Open-set and Closed-set Noisy Labels
Paper and Code
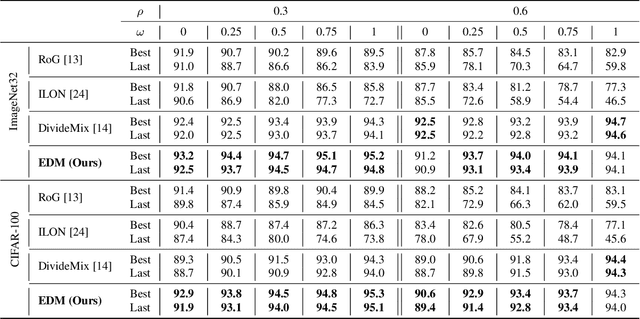

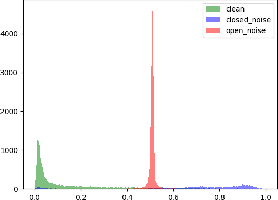
The efficacy of deep learning depends on large-scale data sets that have been carefully curated with reliable data acquisition and annotation processes. However, acquiring such large-scale data sets with precise annotations is very expensive and time-consuming, and the cheap alternatives often yield data sets that have noisy labels. The field has addressed this problem by focusing on training models under two types of label noise: 1) closed-set noise, where some training samples are incorrectly annotated to a training label other than their known true class; and 2) open-set noise, where the training set includes samples that possess a true class that is (strictly) not contained in the set of known training labels. In this work, we study a new variant of the noisy label problem that combines the open-set and closed-set noisy labels, and introduce a benchmark evaluation to assess the performance of training algorithms under this setup. We argue that such problem is more general and better reflects the noisy label scenarios in practice. Furthermore, we propose a novel algorithm, called EvidentialMix, that addresses this problem and compare its performance with the state-of-the-art methods for both closed-set and open-set noise on the proposed benchmark. Our results show that our method produces superior classification results and better feature representations than previous state-of-the-art methods. The code is available at https://github.com/ragavsachdeva/EvidentialMix.