 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
ProMerge: Prompt and Merge for Unsupervised Instance Segmentation
Sep 27, 2024



Unsupervised instance segmentation aims to segment distinct object instances in an image without relying on human-labeled data. This field has recently seen significant advancements, partly due to the strong local correspondences afforded by rich visual feature representations from self-supervised models (e.g., DINO). Recent state-of-the-art approaches use self-supervised features to represent images as graphs and solve a generalized eigenvalue system (i.e., normalized-cut) to generate foreground masks. While effective, this strategy is limited by its attendant computational demands, leading to slow inference speeds. In this paper, we propose Prompt and Merge (ProMerge), which leverages self-supervised visual features to obtain initial groupings of patches and applies a strategic merging to these segments, aided by a sophisticated background-based mask pruning technique. ProMerge not only yields competitive results but also offers a significant reduction in inference time compared to state-of-the-art normalized-cut-based approaches. Furthermore, when training an object detector using our mask predictions as pseudo-labels, the resulting detector surpasses the current leading unsupervised model on various challenging instance segmentation benchmarks.
Tails Tell Tales: Chapter-Wide Manga Transcriptions with Character Names
Aug 01, 2024Enabling engagement of manga by visually impaired individuals presents a significant challenge due to its inherently visual nature. With the goal of fostering accessibility, this paper aims to generate a dialogue transcript of a complete manga chapter, entirely automatically, with a particular emphasis on ensuring narrative consistency. This entails identifying (i) what is being said, i.e., detecting the texts on each page and classifying them into essential vs non-essential, and (ii) who is saying it, i.e., attributing each dialogue to its speaker, while ensuring the same characters are named consistently throughout the chapter. To this end, we introduce: (i) Magiv2, a model that is capable of generating high-quality chapter-wide manga transcripts with named characters and significantly higher precision in speaker diarisation over prior works; (ii) an extension of the PopManga evaluation dataset, which now includes annotations for speech-bubble tail boxes, associations of text to corresponding tails, classifications of text as essential or non-essential, and the identity for each character box; and (iii) a new character bank dataset, which comprises over 11K characters from 76 manga series, featuring 11.5K exemplar character images in total, as well as a list of chapters in which they appear. The code, trained model, and both datasets can be found at: https://github.com/ragavsachdeva/magi
arXiVeri: Automatic table verification with GPT
Jun 13, 2023Without accurate transcription of numerical data in scientific documents, a scientist cannot draw accurate conclusions. Unfortunately, the process of copying numerical data from one paper to another is prone to human error. In this paper, we propose to meet this challenge through the novel task of automatic table verification (AutoTV), in which the objective is to verify the accuracy of numerical data in tables by cross-referencing cited sources. To support this task, we propose a new benchmark, arXiVeri, which comprises tabular data drawn from open-access academic papers on arXiv. We introduce metrics to evaluate the performance of a table verifier in two key areas: (i) table matching, which aims to identify the source table in a cited document that corresponds to a target table, and (ii) cell matching, which aims to locate shared cells between a target and source table and identify their row and column indices accurately. By leveraging the flexible capabilities of modern large language models (LLMs), we propose simple baselines for table verification. Our findings highlight the complexity of this task, even for state-of-the-art LLMs like OpenAI's GPT-4. The code and benchmark will be made publicly available.
Zero-shot Unsupervised Transfer Instance Segmentation
Apr 27, 2023

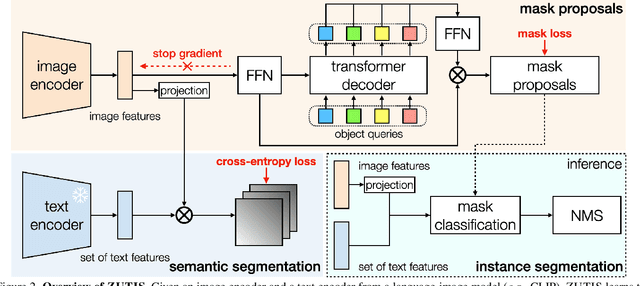
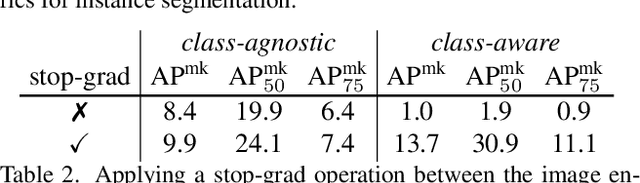
Segmentation is a core computer vision competency, with applications spanning a broad range of scientifically and economically valuable domains. To date, however, the prohibitive cost of annotation has limited the deployment of flexible segmentation models. In this work, we propose Zero-shot Unsupervised Transfer Instance Segmentation (ZUTIS), a framework that aims to meet this challenge. The key strengths of ZUTIS are: (i) no requirement for instance-level or pixel-level annotations; (ii) an ability of zero-shot transfer, i.e., no assumption on access to a target data distribution; (iii) a unified framework for semantic and instance segmentations with solid performance on both tasks compared to state-of-the-art unsupervised methods. While comparing to previous work, we show ZUTIS achieves a gain of 2.2 mask AP on COCO-20K and 14.5 mIoU on ImageNet-S with 919 categories for instance and semantic segmentations, respectively. The code is made publicly available.
NamedMask: Distilling Segmenters from Complementary Foundation Models
Sep 22, 2022

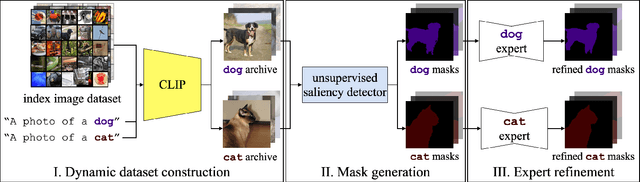
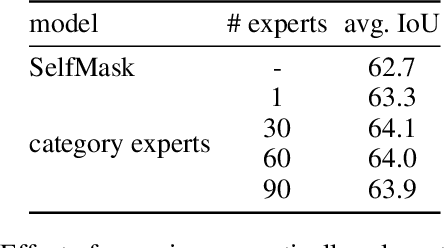
The goal of this work is to segment and name regions of images without access to pixel-level labels during training. To tackle this task, we construct segmenters by distilling the complementary strengths of two foundation models. The first, CLIP (Radford et al. 2021), exhibits the ability to assign names to image content but lacks an accessible representation of object structure. The second, DINO (Caron et al. 2021), captures the spatial extent of objects but has no knowledge of object names. Our method, termed NamedMask, begins by using CLIP to construct category-specific archives of images. These images are pseudo-labelled with a category-agnostic salient object detector bootstrapped from DINO, then refined by category-specific segmenters using the CLIP archive labels. Thanks to the high quality of the refined masks, we show that a standard segmentation architecture trained on these archives with appropriate data augmentation achieves impressive semantic segmentation abilities for both single-object and multi-object images. As a result, our proposed NamedMask performs favourably against a range of prior work on five benchmarks including the VOC2012, COCO and large-scale ImageNet-S datasets.
ReCo: Retrieve and Co-segment for Zero-shot Transfer
Jun 14, 2022
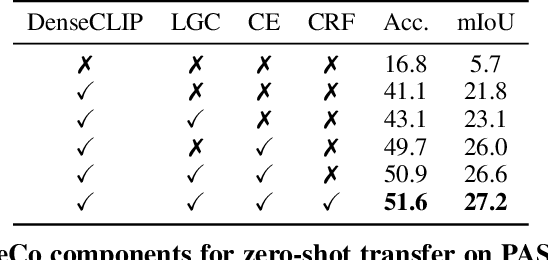
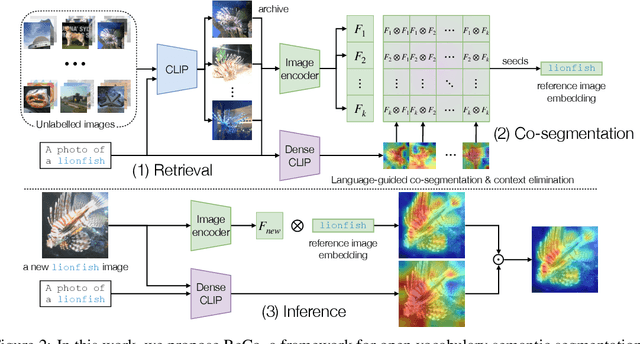
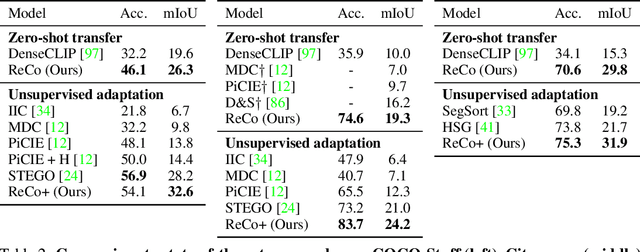
Semantic segmentation has a broad range of applications, but its real-world impact has been significantly limited by the prohibitive annotation costs necessary to enable deployment. Segmentation methods that forgo supervision can side-step these costs, but exhibit the inconvenient requirement to provide labelled examples from the target distribution to assign concept names to predictions. An alternative line of work in language-image pre-training has recently demonstrated the potential to produce models that can both assign names across large vocabularies of concepts and enable zero-shot transfer for classification, but do not demonstrate commensurate segmentation abilities. In this work, we strive to achieve a synthesis of these two approaches that combines their strengths. We leverage the retrieval abilities of one such language-image pre-trained model, CLIP, to dynamically curate training sets from unlabelled images for arbitrary collections of concept names, and leverage the robust correspondences offered by modern image representations to co-segment entities among the resulting collections. The synthetic segment collections are then employed to construct a segmentation model (without requiring pixel labels) whose knowledge of concepts is inherited from the scalable pre-training process of CLIP. We demonstrate that our approach, termed Retrieve and Co-segment (ReCo) performs favourably to unsupervised segmentation approaches while inheriting the convenience of nameable predictions and zero-shot transfer. We also demonstrate ReCo's ability to generate specialist segmenters for extremely rare objects.
Unsupervised Salient Object Detection with Spectral Cluster Voting
Mar 23, 2022
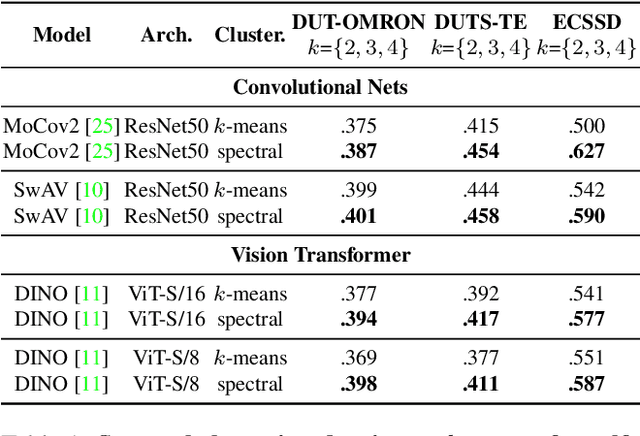
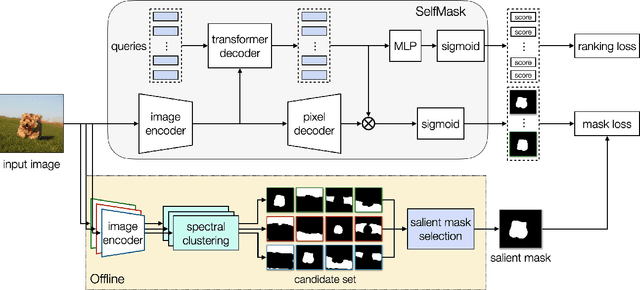
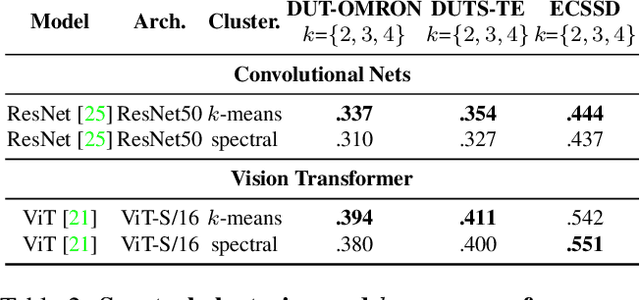
In this paper, we tackle the challenging task of unsupervised salient object detection (SOD) by leveraging spectral clustering on self-supervised features. We make the following contributions: (i) We revisit spectral clustering and demonstrate its potential to group the pixels of salient objects; (ii) Given mask proposals from multiple applications of spectral clustering on image features computed from various self-supervised models, e.g., MoCov2, SwAV, DINO, we propose a simple but effective winner-takes-all voting mechanism for selecting the salient masks, leveraging object priors based on framing and distinctiveness; (iii) Using the selected object segmentation as pseudo groundtruth masks, we train a salient object detector, dubbed SelfMask, which outperforms prior approaches on three unsupervised SOD benchmarks. Code is publicly available at https://github.com/NoelShin/selfmask.
All you need are a few pixels: semantic segmentation with PixelPick
Apr 15, 2021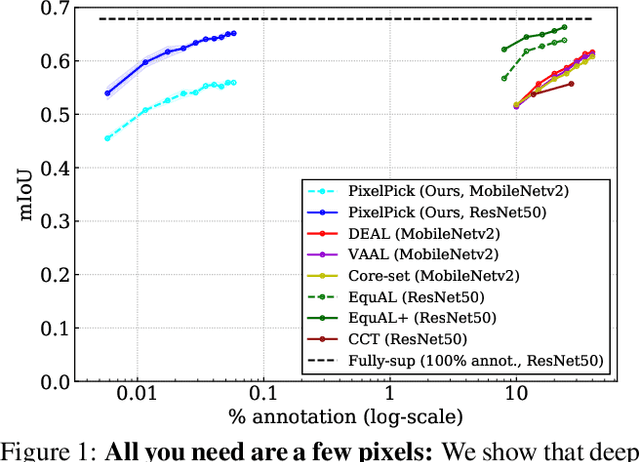
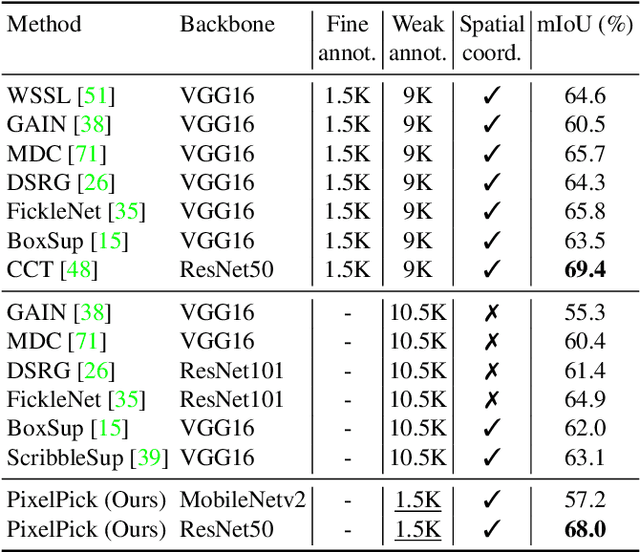
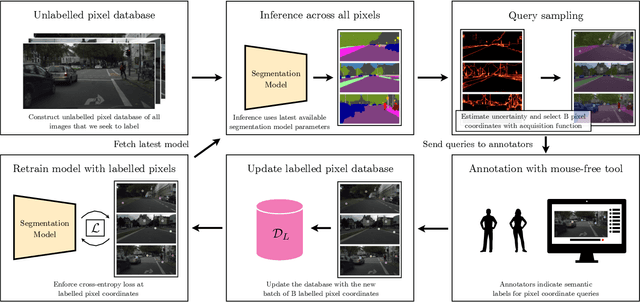
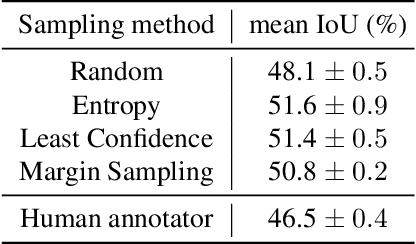
A central challenge for the task of semantic segmentation is the prohibitive cost of obtaining dense pixel-level annotations to supervise model training. In this work, we show that in order to achieve a good level of segmentation performance, all you need are a few well-chosen pixel labels. We make the following contributions: (i) We investigate the novel semantic segmentation setting in which labels are supplied only at sparse pixel locations, and show that deep neural networks can use a handful of such labels to good effect; (ii) We demonstrate how to exploit this phenomena within an active learning framework, termed PixelPick, to radically reduce labelling cost, and propose an efficient "mouse-free" annotation strategy to implement our approach; (iii) We conduct extensive experiments to study the influence of annotation diversity under a fixed budget, model pretraining, model capacity and the sampling mechanism for picking pixels in this low annotation regime; (iv) We provide comparisons to the existing state of the art in semantic segmentation with active learning, and demonstrate comparable performance with up to two orders of magnitude fewer pixel annotations on the CamVid, Cityscapes and PASCAL VOC 2012 benchmarks; (v) Finally, we evaluate the efficiency of our annotation pipeline and its sensitivity to annotator error to demonstrate its practicality.