 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarks in the Sand: Impossibility of Strong Watermarking for Generative Models
Nov 15, 2023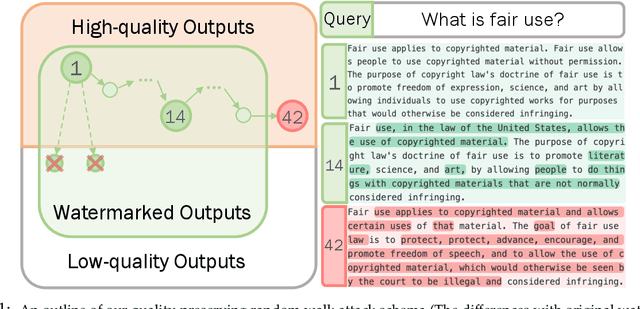

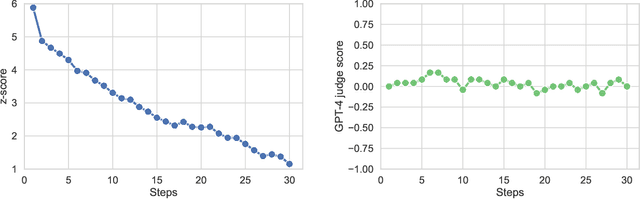

Watermarking generative models consists of planting a statistical signal (watermark) in a model's output so that it can be later verified that the output was generated by the given model. A strong watermarking scheme satisfies the property that a computationally bounded attacker cannot erase the watermark without causing significant quality degradation. In this paper, we study the (im)possibility of strong watermarking schemes. We prove that, under well-specified and natural assumptions, strong watermarking is impossible to achieve. This holds even in the private detection algorithm setting, where the watermark insertion and detection algorithms share a secret key, unknown to the attacker. To prove this result, we introduce a generic efficient watermark attack; the attacker is not required to know the private key of the scheme or even which scheme is used. Our attack is based on two assumptions: (1) The attacker has access to a "quality oracle" that can evaluate whether a candidate output is a high-quality response to a prompt, and (2) The attacker has access to a "perturbation oracle" which can modify an output with a nontrivial probability of maintaining quality, and which induces an efficiently mixing random walk on high-quality outputs. We argue that both assumptions can be satisfied in practice by an attacker with weaker computational capabilities than the watermarked model itself, to which the attacker has only black-box access. Furthermore, our assumptions will likely only be easier to satisfy over time as models grow in capabilities and modalities. We demonstrate the feasibility of our attack by instantiating it to attack three existing watermarking schemes for large language models: Kirchenbauer et al. (2023), Kuditipudi et al. (2023), and Zhao et al. (2023). The same attack successfully removes the watermarks planted by all three schemes, with only minor quality degradation.
Eluding Secure Aggregation in Federated Learning via Model Inconsistency
Nov 14, 2021
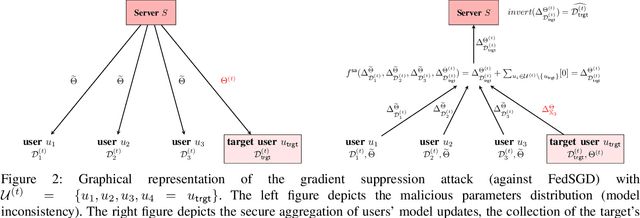
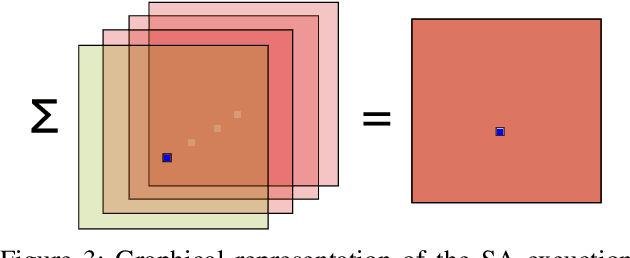
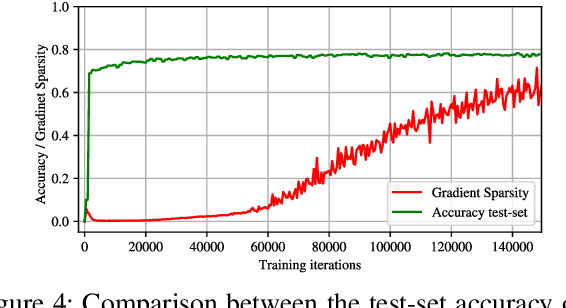
Federated learning allows a set of users to train a deep neural network over their private training datasets. During the protocol, datasets never leave the devices of the respective users. This is achieved by requiring each user to send "only" model updates to a central server that, in turn, aggregates them to update the parameters of the deep neural network. However, it has been shown that each model update carries sensitive information about the user's dataset (e.g., gradient inversion attacks). The state-of-the-art implementations of federated learning protect these model updates by leveraging secure aggregation: A cryptographic protocol that securely computes the aggregation of the model updates of the users. Secure aggregation is pivotal to protect users' privacy since it hinders the server from learning the value and the source of the individual model updates provided by the users, preventing inference and data attribution attacks. In this work, we show that a malicious server can easily elude secure aggregation as if the latter were not in place. We devise two different attacks capable of inferring information on individual private training datasets, independently of the number of users participating in the secure aggregation. This makes them concrete threats in large-scale, real-world federated learning applications. The attacks are generic and do not target any specific secure aggregation protocol. They are equally effective even if the secure aggregation protocol is replaced by its ideal functionality that provides the perfect level of security. Our work demonstrates that secure aggregation has been incorrectly combined with federated learning and that current implementations offer only a "false sense of security".