 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Machine Unlearning: Data Removal while Mitigating Disparities
Paper and Code
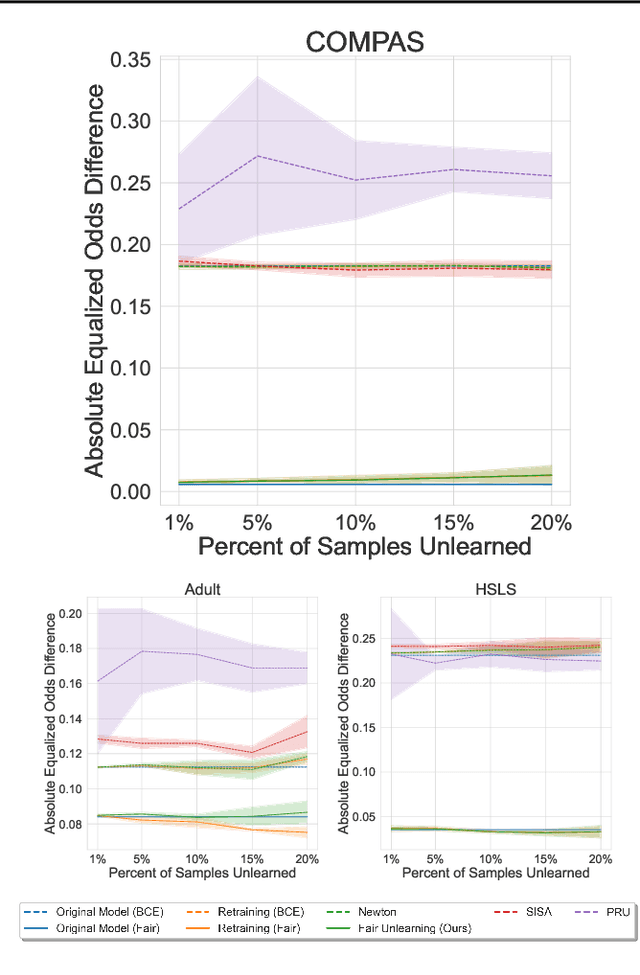
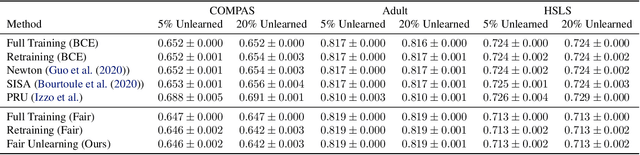
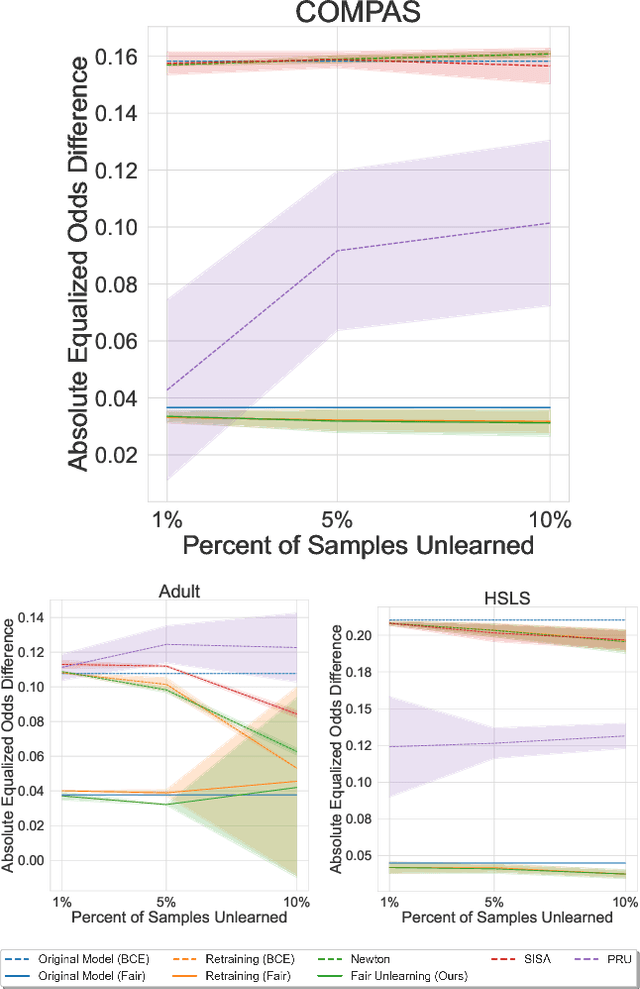
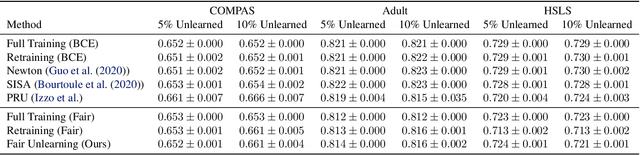
As public consciousness regarding the collection and use of personal information by corporations grows, it is of increasing importance that consumers be active participants in the curation of corporate datasets. In light of this, data governance frameworks such as the General Data Protection Regulation (GDPR) have outlined the right to be forgotten as a key principle allowing individuals to request that their personal data be deleted from the databases and models used by organizations. To achieve forgetting in practice, several machine unlearning methods have been proposed to address the computational inefficiencies of retraining a model from scratch with each unlearning request. While efficient online alternatives to retraining, it is unclear how these methods impact other properties critical to real-world applications, such as fairness. In this work, we propose the first fair machine unlearning method that can provably and efficiently unlearn data instances while preserving group fairness. We derive theoretical results which demonstrate that our method can provably unlearn data instances while maintaining fairness objectives. Extensive experimentation with real-world datasets highlight the efficacy of our method at unlearning data instances while preserving fairness.