 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Smoothing for Provably Robust Reinforcement Learning
Paper and Code
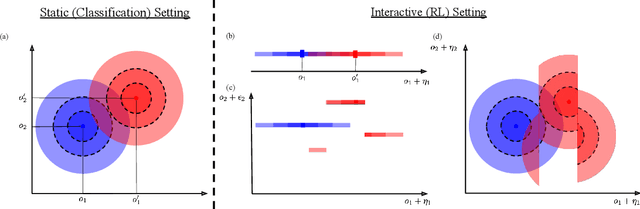

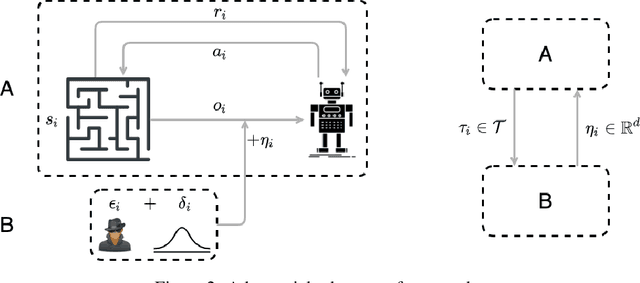

The study of provable adversarial robustness for deep neural network (DNN) models has mainly focused on static supervised learning tasks such as image classification. However, DNNs have been used extensively in real-world adaptive tasks such as reinforcement learning (RL), making RL systems vulnerable to adversarial attacks. The key challenge in adversarial RL is that the attacker can adapt itself to the defense strategy used by the agent in previous time-steps to strengthen its attack in future steps. In this work, we study the provable robustness of RL against norm-bounded adversarial perturbations of the inputs. We focus on smoothing-based provable defenses and propose policy smoothing where the agent adds a Gaussian noise to its observation at each time-step before applying the policy network to make itself less sensitive to adversarial perturbations of its inputs. Our main theoretical contribution is to prove an adaptive version of the Neyman-Pearson Lemma where the adversarial perturbation at a particular time can be a stochastic function of current and previous observations and states as well as previously observed actions. Using this lemma, we adapt the robustness certificates produced by randomized smoothing in the static setting of image classification to the dynamic setting of RL. We generate certificates that guarantee that the total reward obtained by the smoothed policy will not fall below a certain threshold under a norm-bounded adversarial perturbation of the input. We show that our certificates are tight by constructing a worst-case setting that achieves the bounds derived in our analysis. In our experiments, we show that this method can yield meaningful certificates in complex environments demonstrating its effectiveness against adversarial attacks.