 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Aleatoric Uncertainty in Object Detection via Vision Foundation Models
Paper and Code
Nov 26, 2024
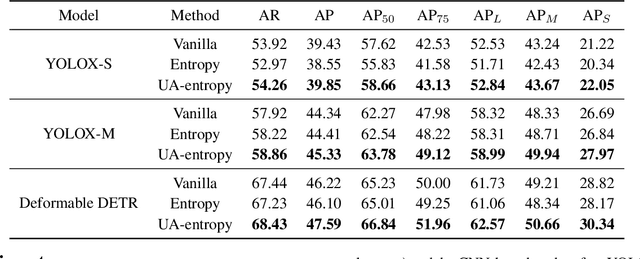
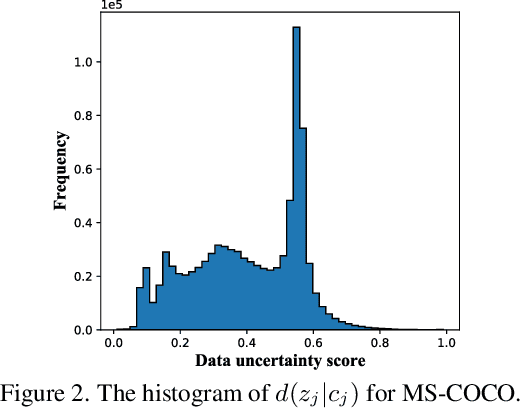
Datasets collected from the open world unavoidably suffer from various forms of randomness or noiseness, leading to the ubiquity of aleatoric (data) uncertainty. Quantifying such uncertainty is particularly pivotal for object detection, where images contain multi-scale objects with occlusion, obscureness, and even noisy annotations, in contrast to images with centric and similar-scale objects in classification. This paper suggests modeling and exploiting the uncertainty inherent in object detection data with vision foundation models and develops a data-centric reliable training paradigm. Technically, we propose to estimate the data uncertainty of each object instance based on the feature space of vision foundation models, which are trained on ultra-large-scale datasets and able to exhibit universal data representation. In particular, we assume a mixture-of-Gaussian structure of the object features and devise Mahalanobis distance-based measures to quantify the data uncertainty. Furthermore, we suggest two curial and practical usages of the estimated uncertainty: 1) for defining uncertainty-aware sample filter to abandon noisy and redundant instances to avoid over-fitting, and 2) for defining sample adaptive regularizer to balance easy/hard samples for adaptive training. The estimated aleatoric uncertainty serves as an extra level of annotations of the dataset, so it can be utilized in a plug-and-play manner with any model. Extensive empirical studies verify the effectiveness of the proposed aleatoric uncertainty measure on various advanced detection models and challenging benchmarks.