 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Reinforcement Learning for Vision-Based Robotics Utilizing Local and Remote Computers
Paper and Code
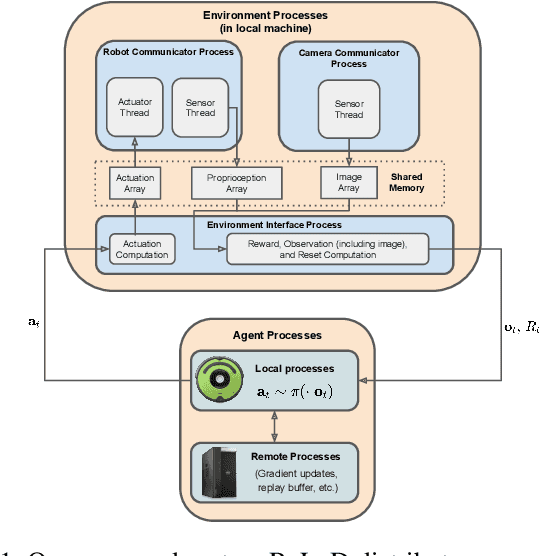
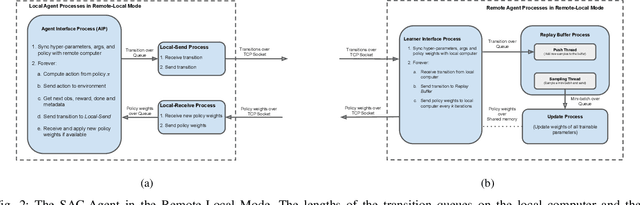
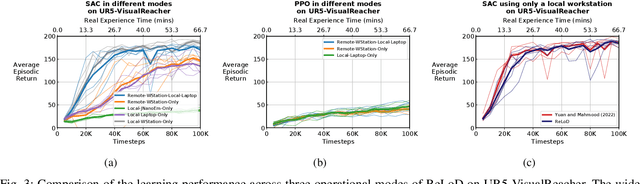
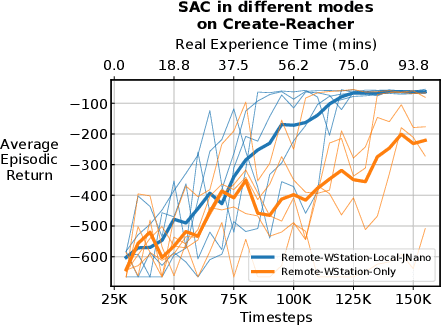
Real-time learning is crucial for robotic agents adapting to ever-changing, non-stationary environments. A common setup for a robotic agent is to have two different computers simultaneously: a resource-limited local computer tethered to the robot and a powerful remote computer connected wirelessly. Given such a setup, it is unclear to what extent the performance of a learning system can be affected by resource limitations and how to efficiently use the wirelessly connected powerful computer to compensate for any performance loss. In this paper, we implement a real-time learning system called the Remote-Local Distributed (ReLoD) system to distribute computations of two deep reinforcement learning (RL) algorithms, Soft Actor-Critic (SAC) and Proximal Policy Optimization (PPO), between a local and a remote computer. The performance of the system is evaluated on two vision-based control tasks developed using a robotic arm and a mobile robot. Our results show that SAC's performance degrades heavily on a resource-limited local computer. Strikingly, when all computations of the learning system are deployed on a remote workstation, SAC fails to compensate for the performance loss, indicating that, without careful consideration, using a powerful remote computer may not result in performance improvement. However, a carefully chosen distribution of computations of SAC consistently and substantially improves its performance on both tasks. On the other hand, the performance of PPO remains largely unaffected by the distribution of computations. In addition, when all computations happen solely on a powerful tethered computer, the performance of our system remains on par with an existing system that is well-tuned for using a single machine. ReLoD is the only publicly available system for real-time RL that applies to multiple robots for vision-based tasks.