 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of state representation methods in robot hand-eye coordination learning from demonstration
Paper and Code
Mar 02, 2019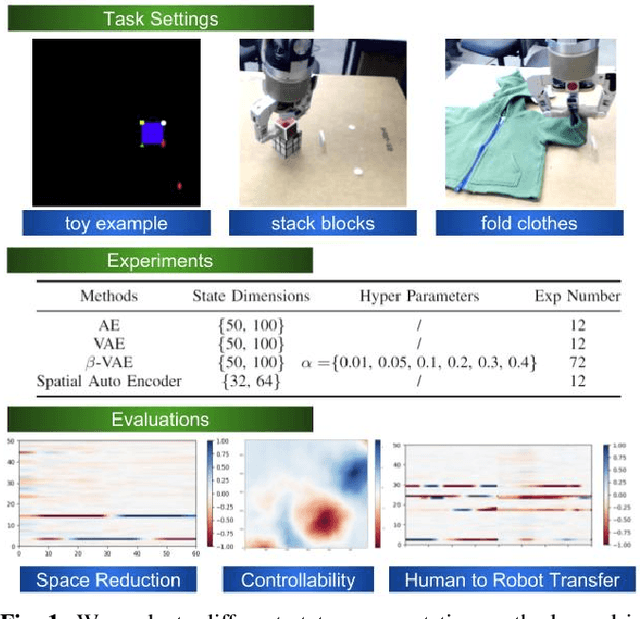

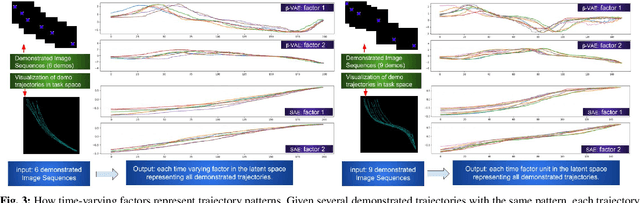
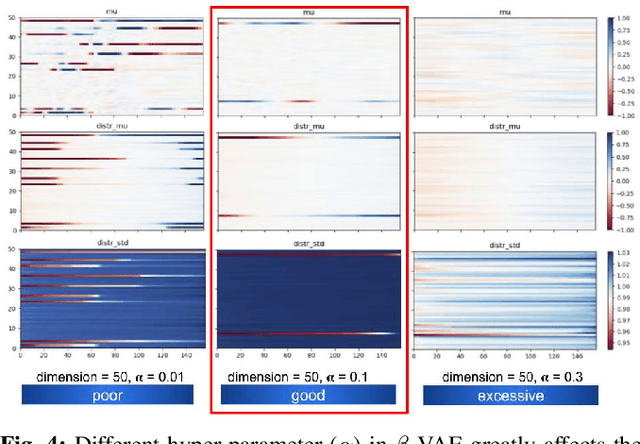
We evaluate different state representation methods in robot hand-eye coordination learning on different aspects. Regarding state dimension reduction: we evaluates how these state representation methods capture relevant task information and how much compactness should a state representation be. Regarding controllability: experiments are designed to use different state representation methods in a traditional visual servoing controller and a REINFORCE controller. We analyze the challenges arisen from the representation itself other than from control algorithms. Regarding embodiment problem in LfD: we evaluate different method's capability in transferring learned representation from human to robot. Results are visualized for better understanding and comparison.