 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot eye-hand coordination learning by watching human demonstrations: a task function approximation approach
Paper and Code
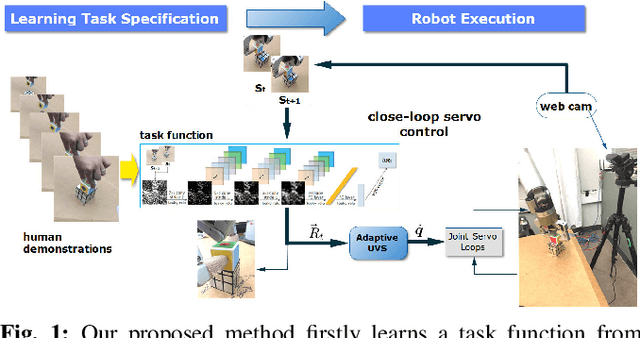
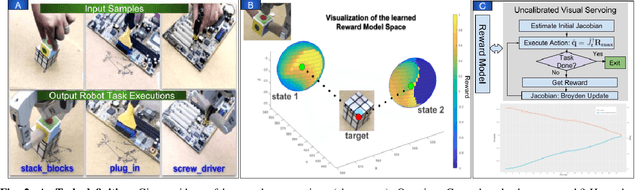


We present a robot eye-hand coordination learning method that can directly learn visual task specification by watching human demonstrations. Task specification is represented as a task function, which is learned using inverse reinforcement learning(IRL) by inferring differential rewards between state changes. The learned task function is then used as continuous feedbacks in an uncalibrated visual servoing(UVS) controller designed for the execution phase. Our proposed method can directly learn from raw videos, which removes the need for hand-engineered task specification. It can also provide task interpretability by directly approximating the task function. Besides, benefiting from the use of a traditional UVS controller, our training process is efficient and the learned policy is independent from a particular robot platform. Various experiments were designed to show that, for a certain DOF task, our method can adapt to task/environment variances in target positions, backgrounds, illuminations, and occlusions without prior retraining.