 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting
Paper and Code
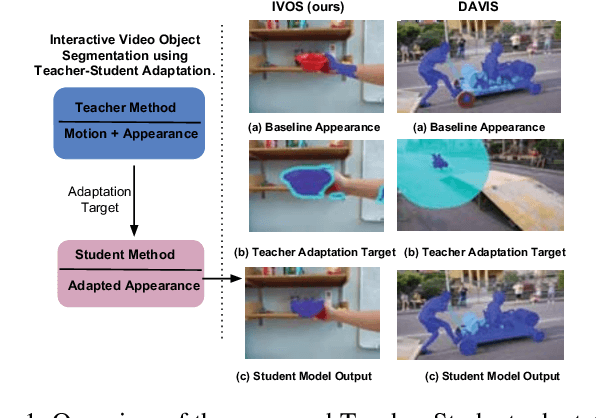


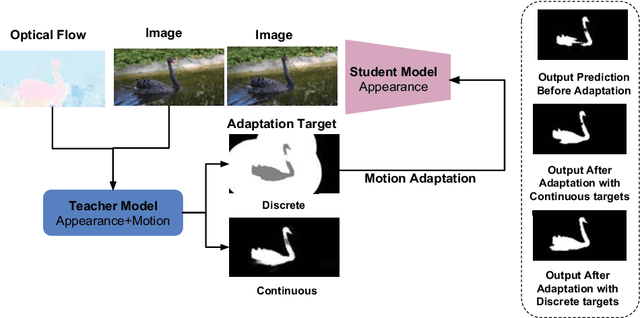
Video segmentation is a challenging task that has many applications in robotics. Learning segmentation from few examples on-line is important for robotics in unstructured environments. The total number of objects and their variation in the real world is intractable, but for a specific task the robot deals with a small subset. Our network is taught, by a human moving a hand-held object through different poses. A novel two-stream motion and appearance "teacher" network provides pseudo-labels. These labels are used to adapt an appearance "student" network. Segmentation can be used to support a variety of robot vision functionality, such as grasping or affordance segmentation. We propose different variants of motion adaptation training and extensively compare against the state-of-the-art methods. We collected a carefully designed dataset in the human robot interaction (HRI) setting. We denote our dataset as (L)ow-shot (O)bject (R)ecognition, (D)etection and (S)egmentation using HRI. Our dataset contains teaching videos of different hand-held objects moving in translation, scale and rotation. It contains kitchen manipulation tasks as well, performed by humans and robots. Our proposed method outperforms the state-of-the-art on DAVIS and FBMS with 7% and 1.2% in F-measure respectively. In our more challenging LORDS-HRI dataset, our approach achieves significantly better performance with 46.7% and 24.2% relative improvement in mIoU over the baseline.