 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers in Unsupervised Structure-from-Motion
Dec 16, 2023Transformers have revolutionized deep learning based computer vision with improved performance as well as robustness to natural corruptions and adversarial attacks. Transformers are used predominantly for 2D vision tasks, including image classification, semantic segmentation, and object detection. However, robots and advanced driver assistance systems also require 3D scene understanding for decision making by extracting structure-from-motion (SfM). We propose a robust transformer-based monocular SfM method that learns to predict monocular pixel-wise depth, ego vehicle's translation and rotation, as well as camera's focal length and principal point, simultaneously. With experiments on KITTI and DDAD datasets, we demonstrate how to adapt different vision transformers and compare them against contemporary CNN-based methods. Our study shows that transformer-based architecture, though lower in run-time efficiency, achieves comparable performance while being more robust against natural corruptions, as well as untargeted and targeted attacks.
Continual Learning of Unsupervised Monocular Depth from Videos
Nov 04, 2023



Spatial scene understanding, including monocular depth estimation, is an important problem in various applications, such as robotics and autonomous driving. While improvements in unsupervised monocular depth estimation have potentially allowed models to be trained on diverse crowdsourced videos, this remains underexplored as most methods utilize the standard training protocol, wherein the models are trained from scratch on all data after new data is collected. Instead, continual training of models on sequentially collected data would significantly reduce computational and memory costs. Nevertheless, naive continual training leads to catastrophic forgetting, where the model performance deteriorates on older domains as it learns on newer domains, highlighting the trade-off between model stability and plasticity. While several techniques have been proposed to address this issue in image classification, the high-dimensional and spatiotemporally correlated outputs of depth estimation make it a distinct challenge. To the best of our knowledge, no framework or method currently exists focusing on the problem of continual learning in depth estimation. Thus, we introduce a framework that captures the challenges of continual unsupervised depth estimation (CUDE), and define the necessary metrics to evaluate model performance. We propose a rehearsal-based dual-memory method, MonoDepthCL, which utilizes spatiotemporal consistency for continual learning in depth estimation, even when the camera intrinsics are unknown.
Dynamically Modular and Sparse General Continual Learning
Jan 02, 2023Real-world applications often require learning continuously from a stream of data under ever-changing conditions. When trying to learn from such non-stationary data, deep neural networks (DNNs) undergo catastrophic forgetting of previously learned information. Among the common approaches to avoid catastrophic forgetting, rehearsal-based methods have proven effective. However, they are still prone to forgetting due to task-interference as all parameters respond to all tasks. To counter this, we take inspiration from sparse coding in the brain and introduce dynamic modularity and sparsity (Dynamos) for rehearsal-based general continual learning. In this setup, the DNN learns to respond to stimuli by activating relevant subsets of neurons. We demonstrate the effectiveness of Dynamos on multiple datasets under challenging continual learning evaluation protocols. Finally, we show that our method learns representations that are modular and specialized, while maintaining reusability by activating subsets of neurons with overlaps corresponding to the similarity of stimuli.
AI-Driven Road Maintenance Inspection v2: Reducing Data Dependency & Quantifying Road Damage
Oct 07, 2022

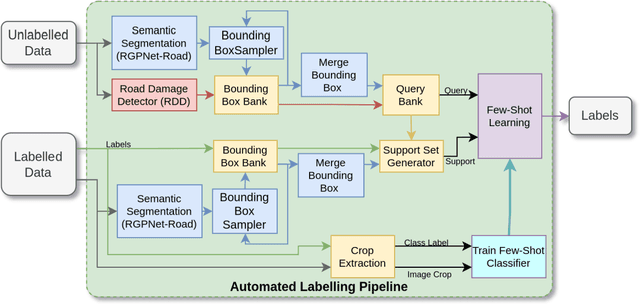
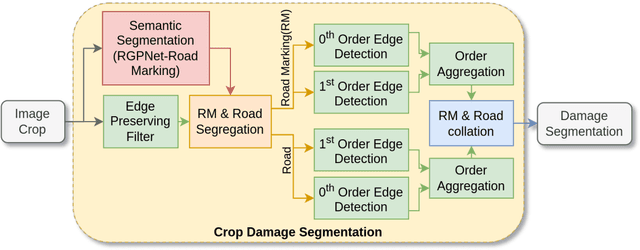
Road infrastructure maintenance inspection is typically a labor-intensive and critical task to ensure the safety of all road users. Existing state-of-the-art techniques in Artificial Intelligence (AI) for object detection and segmentation help automate a huge chunk of this task given adequate annotated data. However, annotating videos from scratch is cost-prohibitive. For instance, it can take an annotator several days to annotate a 5-minute video recorded at 30 FPS. Hence, we propose an automated labelling pipeline by leveraging techniques like few-shot learning and out-of-distribution detection to generate labels for road damage detection. In addition, our pipeline includes a risk factor assessment for each damage by instance quantification to prioritize locations for repairs which can lead to optimal deployment of road maintenance machinery. We show that the AI models trained with these techniques can not only generalize better to unseen real-world data with reduced requirement for human annotation but also provide an estimate of maintenance urgency, thereby leading to safer roads.
Adversarial Attacks on Monocular Pose Estimation
Jul 14, 2022

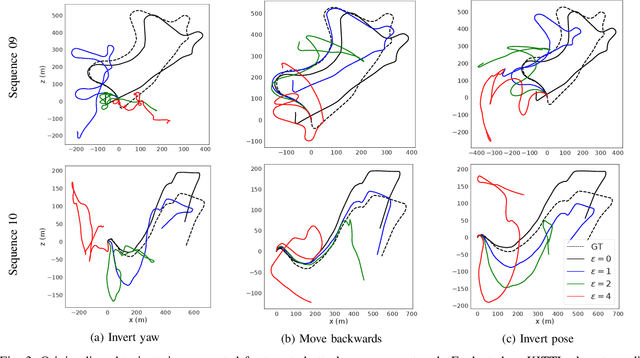
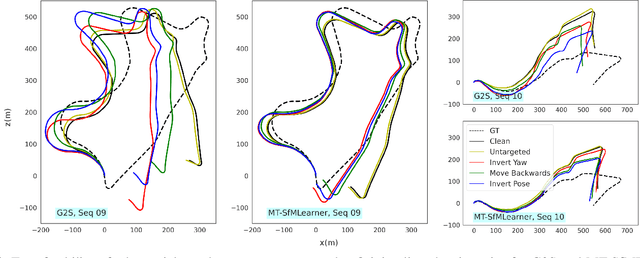
Advances in deep learning have resulted in steady progress in computer vision with improved accuracy on tasks such as object detection and semantic segmentation. Nevertheless, deep neural networks are vulnerable to adversarial attacks, thus presenting a challenge in reliable deployment. Two of the prominent tasks in 3D scene-understanding for robotics and advanced drive assistance systems are monocular depth and pose estimation, often learned together in an unsupervised manner. While studies evaluating the impact of adversarial attacks on monocular depth estimation exist, a systematic demonstration and analysis of adversarial perturbations against pose estimation are lacking. We show how additive imperceptible perturbations can not only change predictions to increase the trajectory drift but also catastrophically alter its geometry. We also study the relation between adversarial perturbations targeting monocular depth and pose estimation networks, as well as the transferability of perturbations to other networks with different architectures and losses. Our experiments show how the generated perturbations lead to notable errors in relative rotation and translation predictions and elucidate vulnerabilities of the networks.
Transformers in Self-Supervised Monocular Depth Estimation with Unknown Camera Intrinsics
Feb 07, 2022The advent of autonomous driving and advanced driver assistance systems necessitates continuous developments in computer vision for 3D scene understanding. Self-supervised monocular depth estimation, a method for pixel-wise distance estimation of objects from a single camera without the use of ground truth labels, is an important task in 3D scene understanding. However, existing methods for this task are limited to convolutional neural network (CNN) architectures. In contrast with CNNs that use localized linear operations and lose feature resolution across the layers, vision transformers process at constant resolution with a global receptive field at every stage. While recent works have compared transformers against their CNN counterparts for tasks such as image classification, no study exists that investigates the impact of using transformers for self-supervised monocular depth estimation. Here, we first demonstrate how to adapt vision transformers for self-supervised monocular depth estimation. Thereafter, we compare the transformer and CNN-based architectures for their performance on KITTI depth prediction benchmarks, as well as their robustness to natural corruptions and adversarial attacks, including when the camera intrinsics are unknown. Our study demonstrates how transformer-based architecture, though lower in run-time efficiency, achieves comparable performance while being more robust and generalizable.
A Comprehensive Study of Vision Transformers on Dense Prediction Tasks
Jan 21, 2022



Convolutional Neural Networks (CNNs), architectures consisting of convolutional layers, have been the standard choice in vision tasks. Recent studies have shown that Vision Transformers (VTs), architectures based on self-attention modules, achieve comparable performance in challenging tasks such as object detection and semantic segmentation. However, the image processing mechanism of VTs is different from that of conventional CNNs. This poses several questions about their generalizability, robustness, reliability, and texture bias when used to extract features for complex tasks. To address these questions, we study and compare VT and CNN architectures as feature extractors in object detection and semantic segmentation. Our extensive empirical results show that the features generated by VTs are more robust to distribution shifts, natural corruptions, and adversarial attacks in both tasks, whereas CNNs perform better at higher image resolutions in object detection. Furthermore, our results demonstrate that VTs in dense prediction tasks produce more reliable and less texture-biased predictions.
Highlighting the Importance of Reducing Research Bias and Carbon Emissions in CNNs
Jun 06, 2021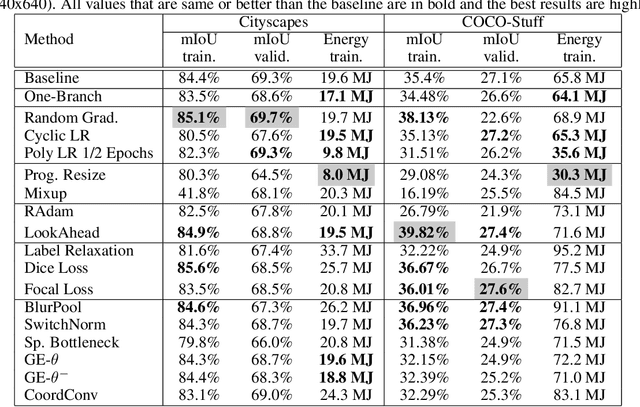

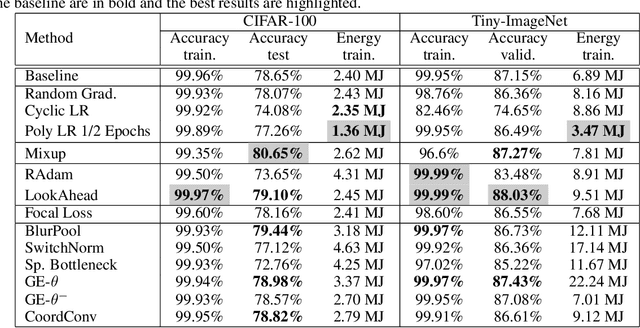
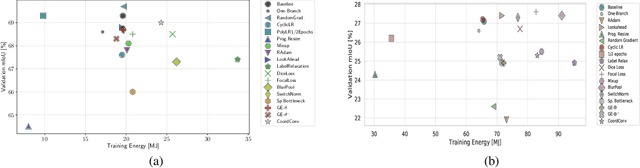
Convolutional neural networks (CNNs) have become commonplace in addressing major challenges in computer vision. Researchers are not only coming up with new CNN architectures but are also researching different techniques to improve the performance of existing architectures. However, there is a tendency to over-emphasize performance improvement while neglecting certain important variables such as simplicity, versatility, the fairness of comparisons, and energy efficiency. Overlooking these variables in architectural design and evaluation has led to research bias and a significantly negative environmental impact. Furthermore, this can undermine the positive impact of research in using deep learning models to tackle climate change. Here, we perform an extensive and fair empirical study of a number of proposed techniques to gauge the utility of each technique for segmentation and classification. Our findings restate the importance of favoring simplicity over complexity in model design (Occam's Razor). Furthermore, our results indicate that simple standardized practices can lead to a significant reduction in environmental impact with little drop in performance. We highlight that there is a need to rethink the design and evaluation of CNNs to alleviate the issue of research bias and carbon emissions.
Multimodal Scale Consistency and Awareness for Monocular Self-Supervised Depth Estimation
Mar 03, 2021



Dense depth estimation is essential to scene-understanding for autonomous driving. However, recent self-supervised approaches on monocular videos suffer from scale-inconsistency across long sequences. Utilizing data from the ubiquitously copresent global positioning systems (GPS), we tackle this challenge by proposing a dynamically-weighted GPS-to-Scale (g2s) loss to complement the appearance-based losses. We emphasize that the GPS is needed only during the multimodal training, and not at inference. The relative distance between frames captured through the GPS provides a scale signal that is independent of the camera setup and scene distribution, resulting in richer learned feature representations. Through extensive evaluation on multiple datasets, we demonstrate scale-consistent and -aware depth estimation during inference, improving the performance even when training with low-frequency GPS data.