 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Real-Time Object Detection Networks Across Multiple Domains: A Survey
Aug 23, 2022

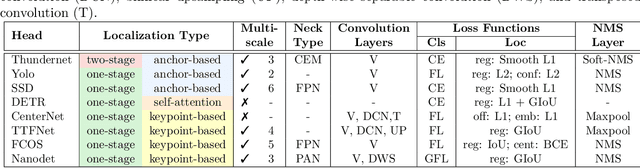
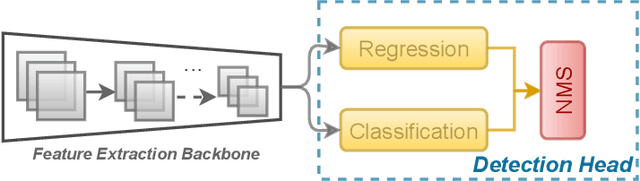
Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detectors, which are a necessity in high-impact real-world applications, are continuously proposed, but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource and energy efficiency are omitted. A reference benchmark for existing networks does not exist, nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, thus, conduct a comprehensive study on multiple real-time detectors (anchor-, keypoint-, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shifts, natural corruptions, and adversarial attacks. Also, we provide a calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare applications. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction in the design and evaluation of networks that focuses on a bigger and holistic overview for a far-reaching impact.
* Published in Transactions on Machine Learning Research (TMLR) with Survey Certification
A Comprehensive Study of Vision Transformers on Dense Prediction Tasks
Jan 21, 2022



Convolutional Neural Networks (CNNs), architectures consisting of convolutional layers, have been the standard choice in vision tasks. Recent studies have shown that Vision Transformers (VTs), architectures based on self-attention modules, achieve comparable performance in challenging tasks such as object detection and semantic segmentation. However, the image processing mechanism of VTs is different from that of conventional CNNs. This poses several questions about their generalizability, robustness, reliability, and texture bias when used to extract features for complex tasks. To address these questions, we study and compare VT and CNN architectures as feature extractors in object detection and semantic segmentation. Our extensive empirical results show that the features generated by VTs are more robust to distribution shifts, natural corruptions, and adversarial attacks in both tasks, whereas CNNs perform better at higher image resolutions in object detection. Furthermore, our results demonstrate that VTs in dense prediction tasks produce more reliable and less texture-biased predictions.