 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Break Free from Strong Data Augmentations in Self-Supervised Learning?
Apr 15, 2024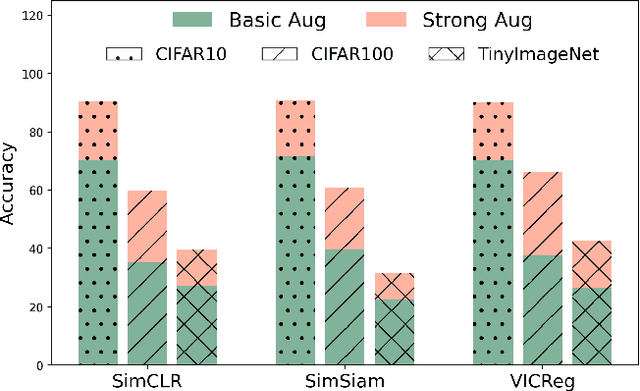

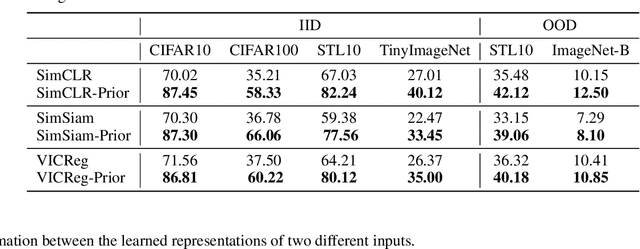
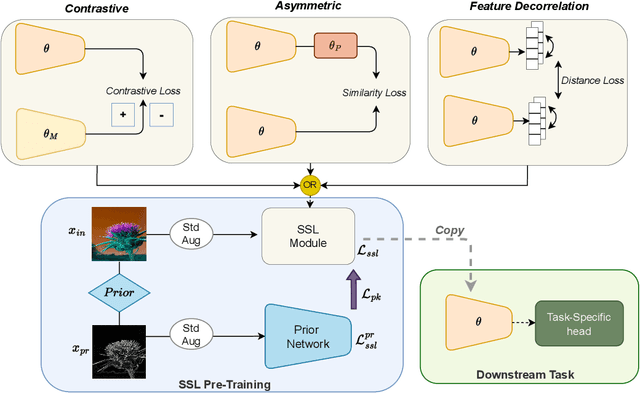
Self-supervised learning (SSL) has emerged as a promising solution for addressing the challenge of limited labeled data in deep neural networks (DNNs), offering scalability potential. However, the impact of design dependencies within the SSL framework remains insufficiently investigated. In this study, we comprehensively explore SSL behavior across a spectrum of augmentations, revealing their crucial role in shaping SSL model performance and learning mechanisms. Leveraging these insights, we propose a novel learning approach that integrates prior knowledge, with the aim of curtailing the need for extensive data augmentations and thereby amplifying the efficacy of learned representations. Notably, our findings underscore that SSL models imbued with prior knowledge exhibit reduced texture bias, diminished reliance on shortcuts and augmentations, and improved robustness against both natural and adversarial corruptions. These findings not only illuminate a new direction in SSL research, but also pave the way for enhancing DNN performance while concurrently alleviating the imperative for intensive data augmentation, thereby enhancing scalability and real-world problem-solving capabilities.
Conserve-Update-Revise to Cure Generalization and Robustness Trade-off in Adversarial Training
Jan 26, 2024Adversarial training improves the robustness of neural networks against adversarial attacks, albeit at the expense of the trade-off between standard and robust generalization. To unveil the underlying factors driving this phenomenon, we examine the layer-wise learning capabilities of neural networks during the transition from a standard to an adversarial setting. Our empirical findings demonstrate that selectively updating specific layers while preserving others can substantially enhance the network's learning capacity. We therefore propose CURE, a novel training framework that leverages a gradient prominence criterion to perform selective conservation, updating, and revision of weights. Importantly, CURE is designed to be dataset- and architecture-agnostic, ensuring its applicability across various scenarios. It effectively tackles both memorization and overfitting issues, thus enhancing the trade-off between robustness and generalization and additionally, this training approach also aids in mitigating "robust overfitting". Furthermore, our study provides valuable insights into the mechanisms of selective adversarial training and offers a promising avenue for future research.
Dual Cognitive Architecture: Incorporating Biases and Multi-Memory Systems for Lifelong Learning
Oct 17, 2023Artificial neural networks (ANNs) exhibit a narrow scope of expertise on stationary independent data. However, the data in the real world is continuous and dynamic, and ANNs must adapt to novel scenarios while also retaining the learned knowledge to become lifelong learners. The ability of humans to excel at these tasks can be attributed to multiple factors ranging from cognitive computational structures, cognitive biases, and the multi-memory systems in the brain. We incorporate key concepts from each of these to design a novel framework, Dual Cognitive Architecture (DUCA), which includes multiple sub-systems, implicit and explicit knowledge representation dichotomy, inductive bias, and a multi-memory system. The inductive bias learner within DUCA is instrumental in encoding shape information, effectively countering the tendency of ANNs to learn local textures. Simultaneously, the inclusion of a semantic memory submodule facilitates the gradual consolidation of knowledge, replicating the dynamics observed in fast and slow learning systems, reminiscent of the principles underpinning the complementary learning system in human cognition. DUCA shows improvement across different settings and datasets, and it also exhibits reduced task recency bias, without the need for extra information. To further test the versatility of lifelong learning methods on a challenging distribution shift, we introduce a novel domain-incremental dataset DN4IL. In addition to improving performance on existing benchmarks, DUCA also demonstrates superior performance on this complex dataset.
LSFSL: Leveraging Shape Information in Few-shot Learning
Apr 13, 2023Few-shot learning (FSL) techniques seek to learn the underlying patterns in data using fewer samples, analogous to how humans learn from limited experience. In this limited-data scenario, the challenges associated with deep neural networks, such as shortcut learning and texture bias behaviors, are further exacerbated. Moreover, the significance of addressing shortcut learning is not yet fully explored in the few-shot setup. To address these issues, we propose LSFSL, which enforces the model to learn more generalizable features utilizing the implicit prior information present in the data. Through comprehensive analyses, we demonstrate that LSFSL-trained models are less vulnerable to alteration in color schemes, statistical correlations, and adversarial perturbations leveraging the global semantics in the data. Our findings highlight the potential of incorporating relevant priors in few-shot approaches to increase robustness and generalization.
A Comprehensive Study of Real-Time Object Detection Networks Across Multiple Domains: A Survey
Aug 23, 2022

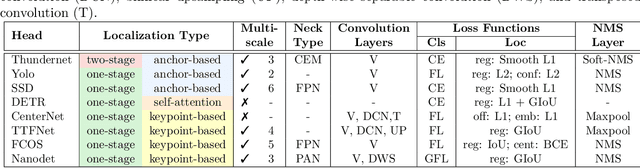
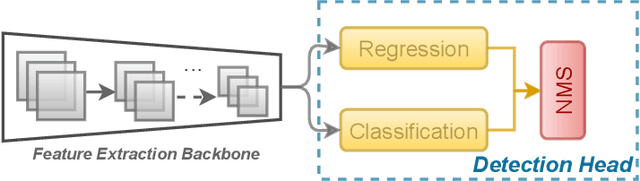
Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detectors, which are a necessity in high-impact real-world applications, are continuously proposed, but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource and energy efficiency are omitted. A reference benchmark for existing networks does not exist, nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, thus, conduct a comprehensive study on multiple real-time detectors (anchor-, keypoint-, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shifts, natural corruptions, and adversarial attacks. Also, we provide a calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare applications. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction in the design and evaluation of networks that focuses on a bigger and holistic overview for a far-reaching impact.
* Published in Transactions on Machine Learning Research (TMLR) with Survey Certification
InBiaseD: Inductive Bias Distillation to Improve Generalization and Robustness through Shape-awareness
Jun 12, 2022



Humans rely less on spurious correlations and trivial cues, such as texture, compared to deep neural networks which lead to better generalization and robustness. It can be attributed to the prior knowledge or the high-level cognitive inductive bias present in the brain. Therefore, introducing meaningful inductive bias to neural networks can help learn more generic and high-level representations and alleviate some of the shortcomings. We propose InBiaseD to distill inductive bias and bring shape-awareness to the neural networks. Our method includes a bias alignment objective that enforces the networks to learn more generic representations that are less vulnerable to unintended cues in the data which results in improved generalization performance. InBiaseD is less susceptible to shortcut learning and also exhibits lower texture bias. The better representations also aid in improving robustness to adversarial attacks and we hence plugin InBiaseD seamlessly into the existing adversarial training schemes to show a better trade-off between generalization and robustness.
Does Thermal data make the detection systems more reliable?
Nov 09, 2021
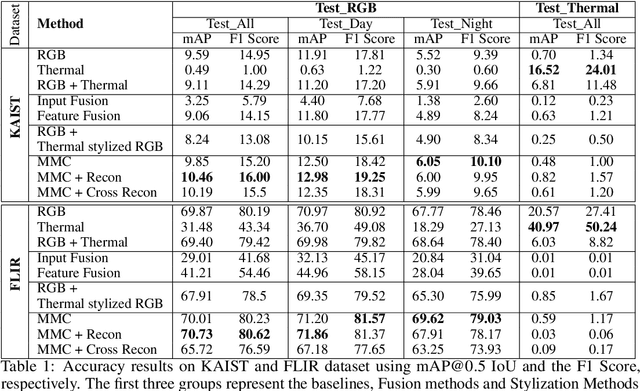


Deep learning-based detection networks have made remarkable progress in autonomous driving systems (ADS). ADS should have reliable performance across a variety of ambient lighting and adverse weather conditions. However, luminance degradation and visual obstructions (such as glare, fog) result in poor quality images by the visual camera which leads to performance decline. To overcome these challenges, we explore the idea of leveraging a different data modality that is disparate yet complementary to the visual data. We propose a comprehensive detection system based on a multimodal-collaborative framework that learns from both RGB (from visual cameras) and thermal (from Infrared cameras) data. This framework trains two networks collaboratively and provides flexibility in learning optimal features of its own modality while also incorporating the complementary knowledge of the other. Our extensive empirical results show that while the improvement in accuracy is nominal, the value lies in challenging and extremely difficult edge cases which is crucial in safety-critical applications such as AD. We provide a holistic view of both merits and limitations of using a thermal imaging system in detection.
AI Driven Road Maintenance Inspection
Jun 04, 2021



Road infrastructure maintenance inspection is typically a labour-intensive and critical task to ensure the safety of all the road users. In this work, we propose a detailed methodology to use state-of-the-art techniques in artificial intelligence and computer vision to automate a sizeable portion of the maintenance inspection subtasks and reduce the labour costs. The proposed methodology uses state-of-the-art computer vision techniques such as object detection and semantic segmentation to automate inspections on primary road structures such as the road surface, markings, barriers (guardrails) and traffic signs. The models are mostly trained on commercially viable datasets and augmented with proprietary data. We demonstrate that our AI models can not only automate and scale maintenance inspections on primary road structures but also result in higher recall compared to traditional manual inspections.