 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Efficiency of Transformers for Resource-Constrained Devices
Jun 30, 2021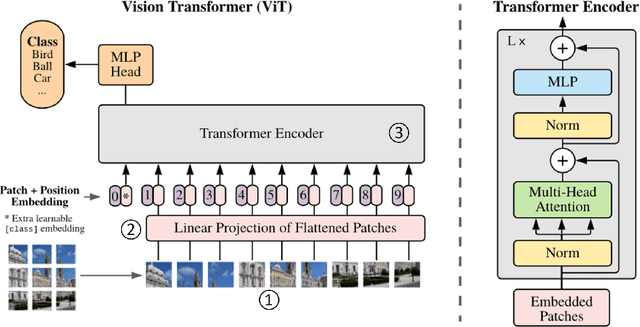
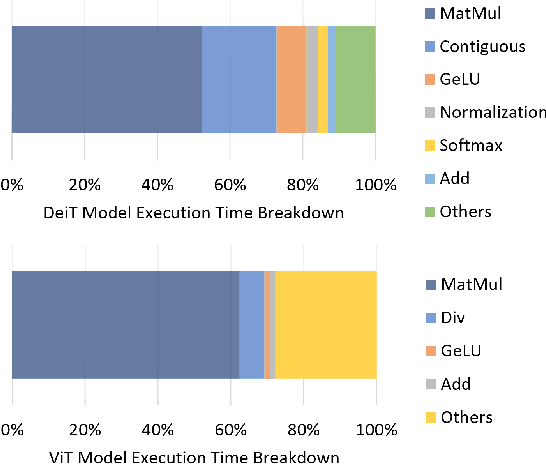
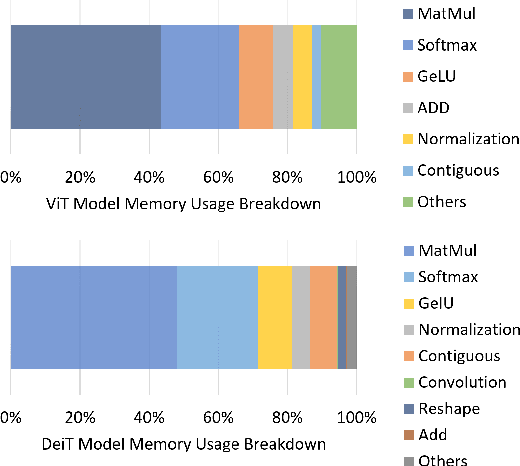
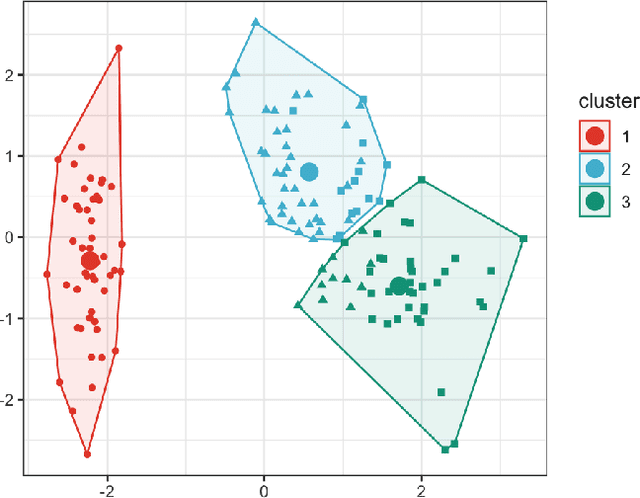
Transformers provide promising accuracy and have become popular and used in various domains such as natural language processing and computer vision. However, due to their massive number of model parameters, memory and computation requirements, they are not suitable for resource-constrained low-power devices. Even with high-performance and specialized devices, the memory bandwidth can become a performance-limiting bottleneck. In this paper, we present a performance analysis of state-of-the-art vision transformers on several devices. We propose to reduce the overall memory footprint and memory transfers by clustering the model parameters. We show that by using only 64 clusters to represent model parameters, it is possible to reduce the data transfer from the main memory by more than 4x, achieve up to 22% speedup and 39% energy savings on mobile devices with less than 0.1% accuracy loss.
AI Driven Road Maintenance Inspection
Jun 04, 2021



Road infrastructure maintenance inspection is typically a labour-intensive and critical task to ensure the safety of all the road users. In this work, we propose a detailed methodology to use state-of-the-art techniques in artificial intelligence and computer vision to automate a sizeable portion of the maintenance inspection subtasks and reduce the labour costs. The proposed methodology uses state-of-the-art computer vision techniques such as object detection and semantic segmentation to automate inspections on primary road structures such as the road surface, markings, barriers (guardrails) and traffic signs. The models are mostly trained on commercially viable datasets and augmented with proprietary data. We demonstrate that our AI models can not only automate and scale maintenance inspections on primary road structures but also result in higher recall compared to traditional manual inspections.
Practical Auto-Calibration for Spatial Scene-Understanding from Crowdsourced Dashcamera Videos
Dec 15, 2020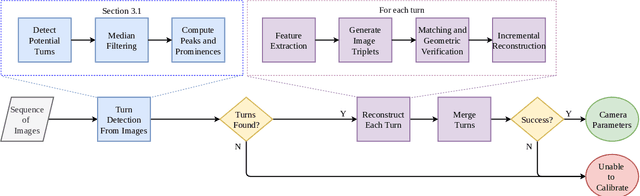
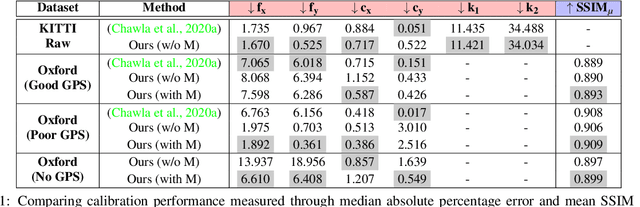


Spatial scene-understanding, including dense depth and ego-motion estimation, is an important problem in computer vision for autonomous vehicles and advanced driver assistance systems. Thus, it is beneficial to design perception modules that can utilize crowdsourced videos collected from arbitrary vehicular onboard or dashboard cameras. However, the intrinsic parameters corresponding to such cameras are often unknown or change over time. Typical manual calibration approaches require objects such as a chessboard or additional scene-specific information. On the other hand, automatic camera calibration does not have such requirements. Yet, the automatic calibration of dashboard cameras is challenging as forward and planar navigation results in critical motion sequences with reconstruction ambiguities. Structure reconstruction of complete visual-sequences that may contain tens of thousands of images is also computationally untenable. Here, we propose a system for practical monocular onboard camera auto-calibration from crowdsourced videos. We show the effectiveness of our proposed system on the KITTI raw, Oxford RobotCar, and the crowdsourced D$^2$-City datasets in varying conditions. Finally, we demonstrate its application for accurate monocular dense depth and ego-motion estimation on uncalibrated videos.
RGPNet: A Real-Time General Purpose Semantic Segmentation
Dec 03, 2019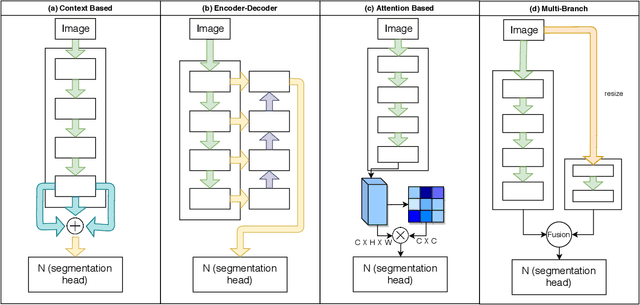
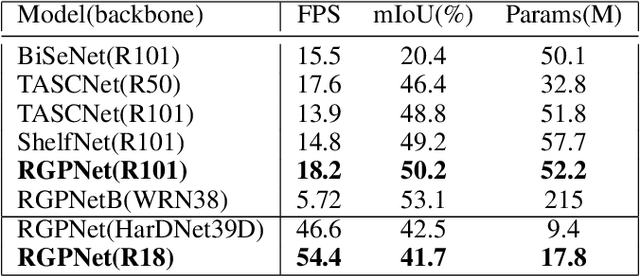
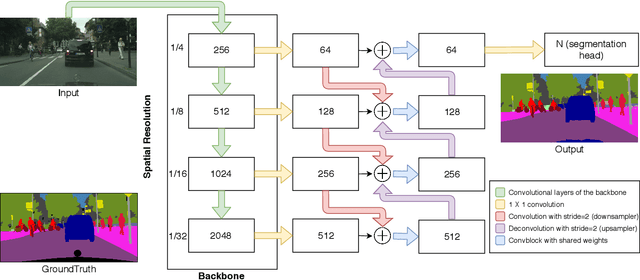
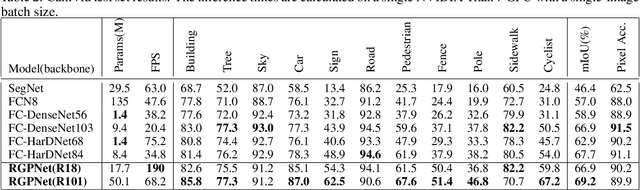
We propose a novel real-time general purpose semantic segmentation architecture, called RGPNet, which achieves significant performance gain in complex environments. RGPNet consists of a light-weight asymmetric encoder-decoder and an adaptor. The adaptor helps preserve and refine the abstract concepts from multiple levels of distributed representations between encoder and decoder. It also facilitates the gradient flow from deeper layers to shallower layers. Our extensive experiments highlight the superior performance of RGPNet compared to the state-of-the-art semantic segmentation networks. Moreover, towards green AI, we show that using a modified label-relaxation technique with progressive resizing can reduce the training time by up to 60% while preserving the performance. Furthermore, we optimize RGPNet for resource-constrained and embedded devices which increases the inference speed by 400% with a negligible loss in performance. We conclude that RGPNet obtains a better speed-accuracy trade-off across multiple datasets.
Proceedings of eNTERFACE 2015 Workshop on Intelligent Interfaces
Jan 19, 2018
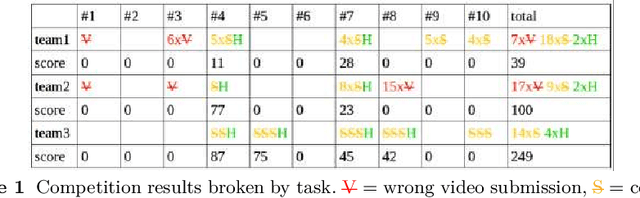
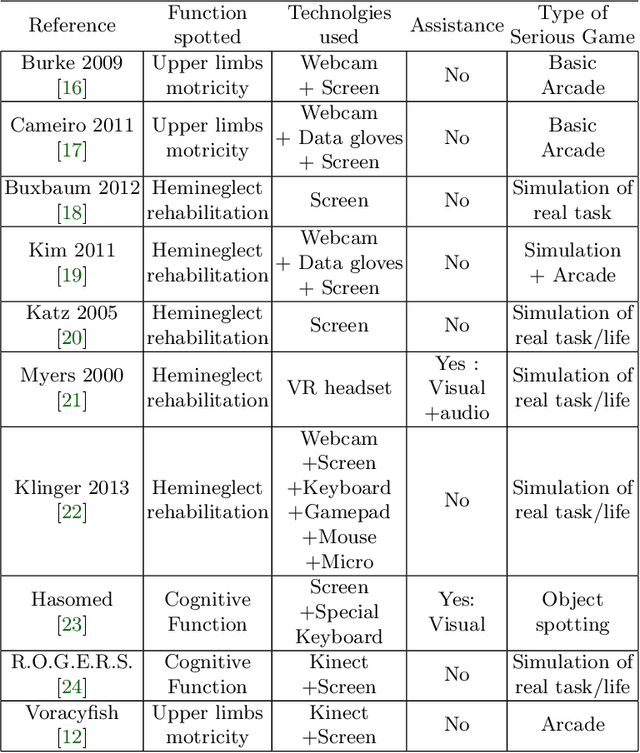
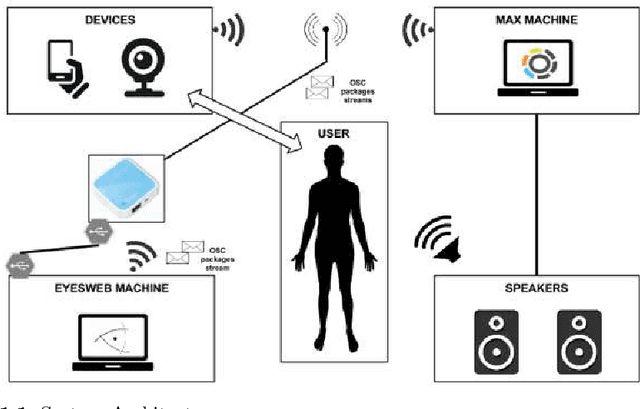
The 11th Summer Workshop on Multimodal Interfaces eNTERFACE 2015 was hosted by the Numediart Institute of Creative Technologies of the University of Mons from August 10th to September 2015. During the four weeks, students and researchers from all over the world came together in the Numediart Institute of the University of Mons to work on eight selected projects structured around intelligent interfaces. Eight projects were selected and their reports are shown here.