 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Road Maintenance Inspection v2: Reducing Data Dependency & Quantifying Road Damage
Oct 07, 2022

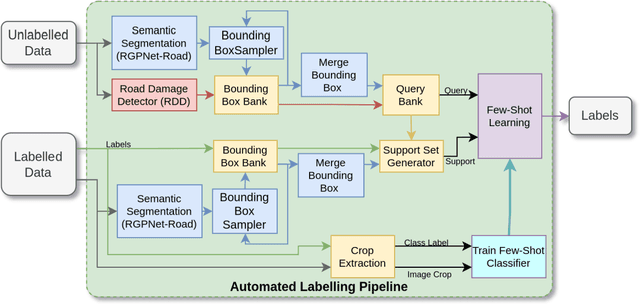
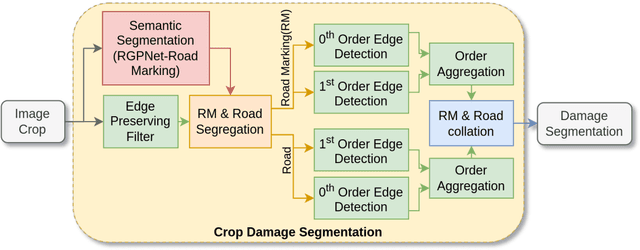
Road infrastructure maintenance inspection is typically a labor-intensive and critical task to ensure the safety of all road users. Existing state-of-the-art techniques in Artificial Intelligence (AI) for object detection and segmentation help automate a huge chunk of this task given adequate annotated data. However, annotating videos from scratch is cost-prohibitive. For instance, it can take an annotator several days to annotate a 5-minute video recorded at 30 FPS. Hence, we propose an automated labelling pipeline by leveraging techniques like few-shot learning and out-of-distribution detection to generate labels for road damage detection. In addition, our pipeline includes a risk factor assessment for each damage by instance quantification to prioritize locations for repairs which can lead to optimal deployment of road maintenance machinery. We show that the AI models trained with these techniques can not only generalize better to unseen real-world data with reduced requirement for human annotation but also provide an estimate of maintenance urgency, thereby leading to safer roads.
AI Driven Road Maintenance Inspection
Jun 04, 2021



Road infrastructure maintenance inspection is typically a labour-intensive and critical task to ensure the safety of all the road users. In this work, we propose a detailed methodology to use state-of-the-art techniques in artificial intelligence and computer vision to automate a sizeable portion of the maintenance inspection subtasks and reduce the labour costs. The proposed methodology uses state-of-the-art computer vision techniques such as object detection and semantic segmentation to automate inspections on primary road structures such as the road surface, markings, barriers (guardrails) and traffic signs. The models are mostly trained on commercially viable datasets and augmented with proprietary data. We demonstrate that our AI models can not only automate and scale maintenance inspections on primary road structures but also result in higher recall compared to traditional manual inspections.
Crowdsourced 3D Mapping: A Combined Multi-View Geometry and Self-Supervised Learning Approach
Jul 25, 2020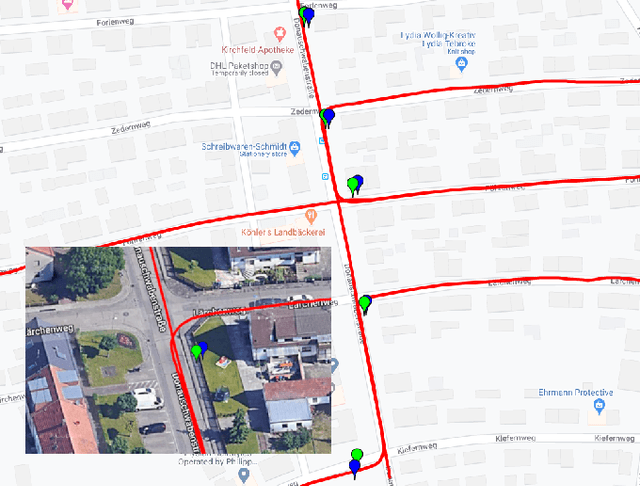
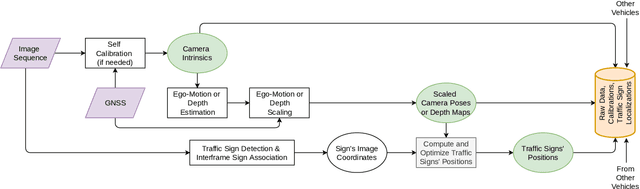
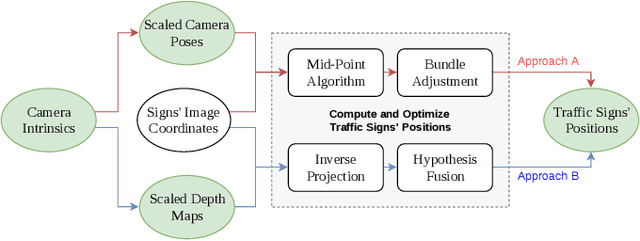
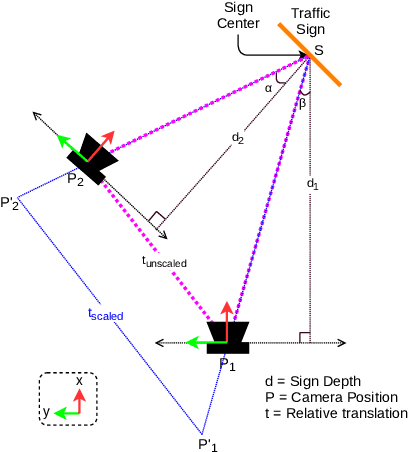
The ability to efficiently utilize crowdsourced visual data carries immense potential for the domains of large scale dynamic mapping and autonomous driving. However, state-of-the-art methods for crowdsourced 3D mapping assume prior knowledge of camera intrinsics. In this work, we propose a framework that estimates the 3D positions of semantically meaningful landmarks such as traffic signs without assuming known camera intrinsics, using only monocular color camera and GPS. We utilize multi-view geometry as well as deep learning based self-calibration, depth, and ego-motion estimation for traffic sign positioning, and show that combining their strengths is important for increasing the map coverage. To facilitate research on this task, we construct and make available a KITTI based 3D traffic sign ground truth positioning dataset. Using our proposed framework, we achieve an average single-journey relative and absolute positioning accuracy of 39cm and 1.26m respectively, on this dataset.
Robust Video-Based Eye Tracking Using Recursive Estimation of Pupil Characteristics
Jun 27, 2017



Video-based eye tracking is a valuable technique in various research fields. Numerous open-source eye tracking algorithms have been developed in recent years, primarily designed for general application with many different camera types. These algorithms do not, however, capitalize on the high frame rate of eye tracking cameras often employed in psychophysical studies. We present a pupil detection method that utilizes this high-speed property to obtain reliable predictions through recursive estimation about certain pupil characteristics in successive camera frames. These predictions are subsequently used to carry out novel image segmentation and classification routines to improve pupil detection performance. Based on results from hand-labelled eye images, our approach was found to have a greater detection rate, accuracy and speed compared to other recently published open-source pupil detection algorithms. The program's source code, together with a graphical user interface, can be downloaded at https://github.com/tbrouns/eyestalker