 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Auto-Calibration for Spatial Scene-Understanding from Crowdsourced Dashcamera Videos
Dec 15, 2020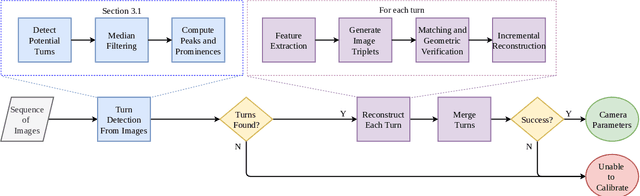
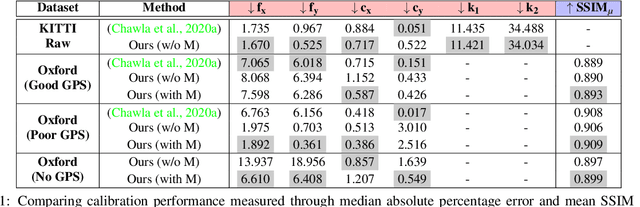


Spatial scene-understanding, including dense depth and ego-motion estimation, is an important problem in computer vision for autonomous vehicles and advanced driver assistance systems. Thus, it is beneficial to design perception modules that can utilize crowdsourced videos collected from arbitrary vehicular onboard or dashboard cameras. However, the intrinsic parameters corresponding to such cameras are often unknown or change over time. Typical manual calibration approaches require objects such as a chessboard or additional scene-specific information. On the other hand, automatic camera calibration does not have such requirements. Yet, the automatic calibration of dashboard cameras is challenging as forward and planar navigation results in critical motion sequences with reconstruction ambiguities. Structure reconstruction of complete visual-sequences that may contain tens of thousands of images is also computationally untenable. Here, we propose a system for practical monocular onboard camera auto-calibration from crowdsourced videos. We show the effectiveness of our proposed system on the KITTI raw, Oxford RobotCar, and the crowdsourced D$^2$-City datasets in varying conditions. Finally, we demonstrate its application for accurate monocular dense depth and ego-motion estimation on uncalibrated videos.
Crowdsourced 3D Mapping: A Combined Multi-View Geometry and Self-Supervised Learning Approach
Jul 25, 2020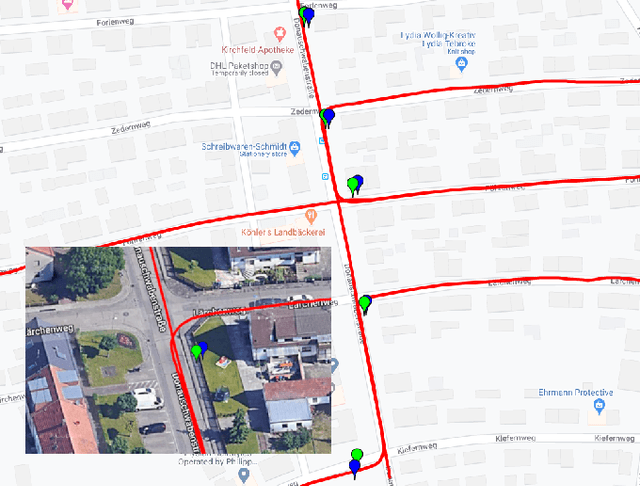
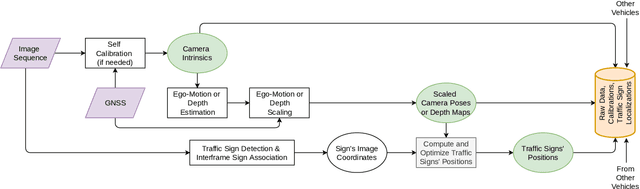
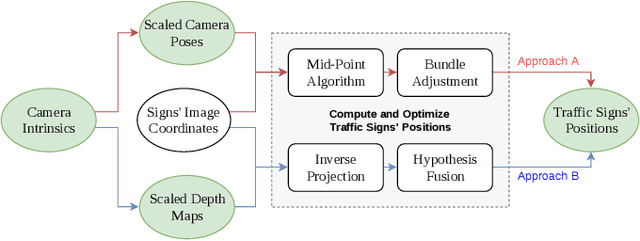
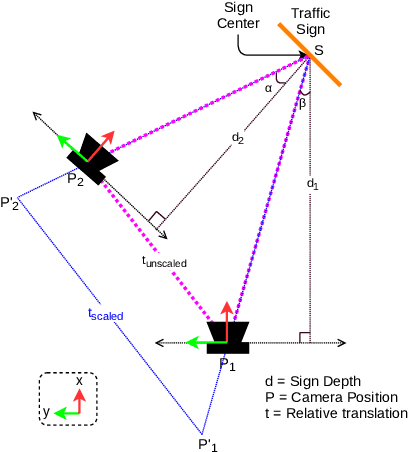
The ability to efficiently utilize crowdsourced visual data carries immense potential for the domains of large scale dynamic mapping and autonomous driving. However, state-of-the-art methods for crowdsourced 3D mapping assume prior knowledge of camera intrinsics. In this work, we propose a framework that estimates the 3D positions of semantically meaningful landmarks such as traffic signs without assuming known camera intrinsics, using only monocular color camera and GPS. We utilize multi-view geometry as well as deep learning based self-calibration, depth, and ego-motion estimation for traffic sign positioning, and show that combining their strengths is important for increasing the map coverage. To facilitate research on this task, we construct and make available a KITTI based 3D traffic sign ground truth positioning dataset. Using our proposed framework, we achieve an average single-journey relative and absolute positioning accuracy of 39cm and 1.26m respectively, on this dataset.
Monocular Vision based Crowdsourced 3D Traffic Sign Positioning with Unknown Camera Intrinsics and Distortion Coefficients
Jul 09, 2020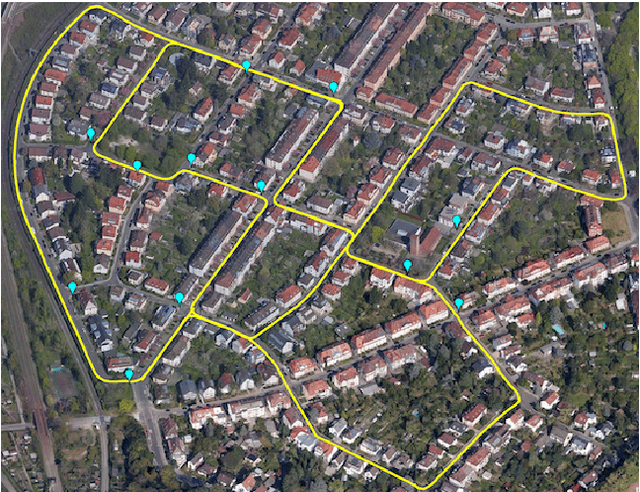
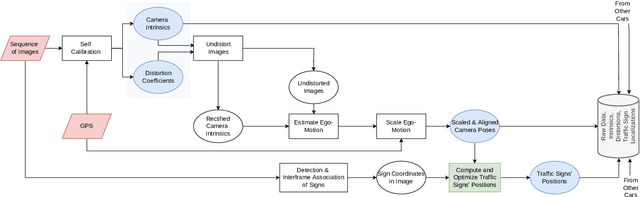
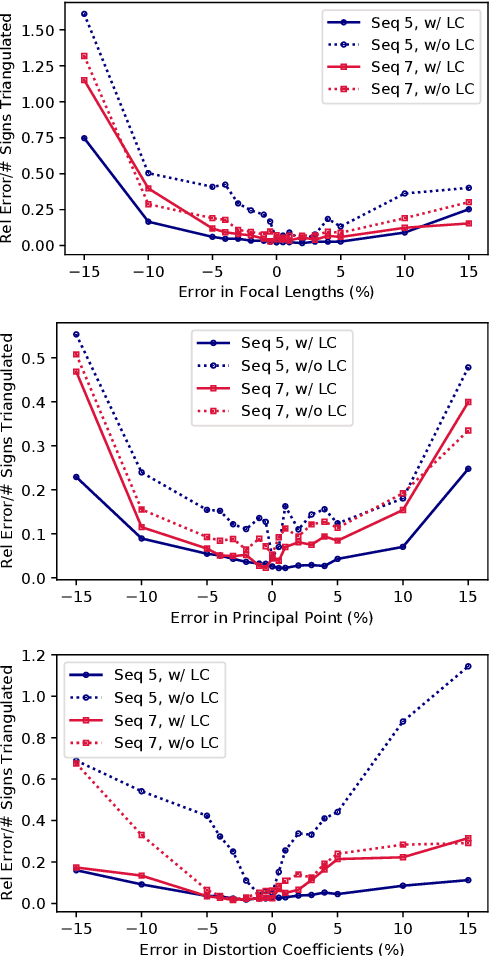
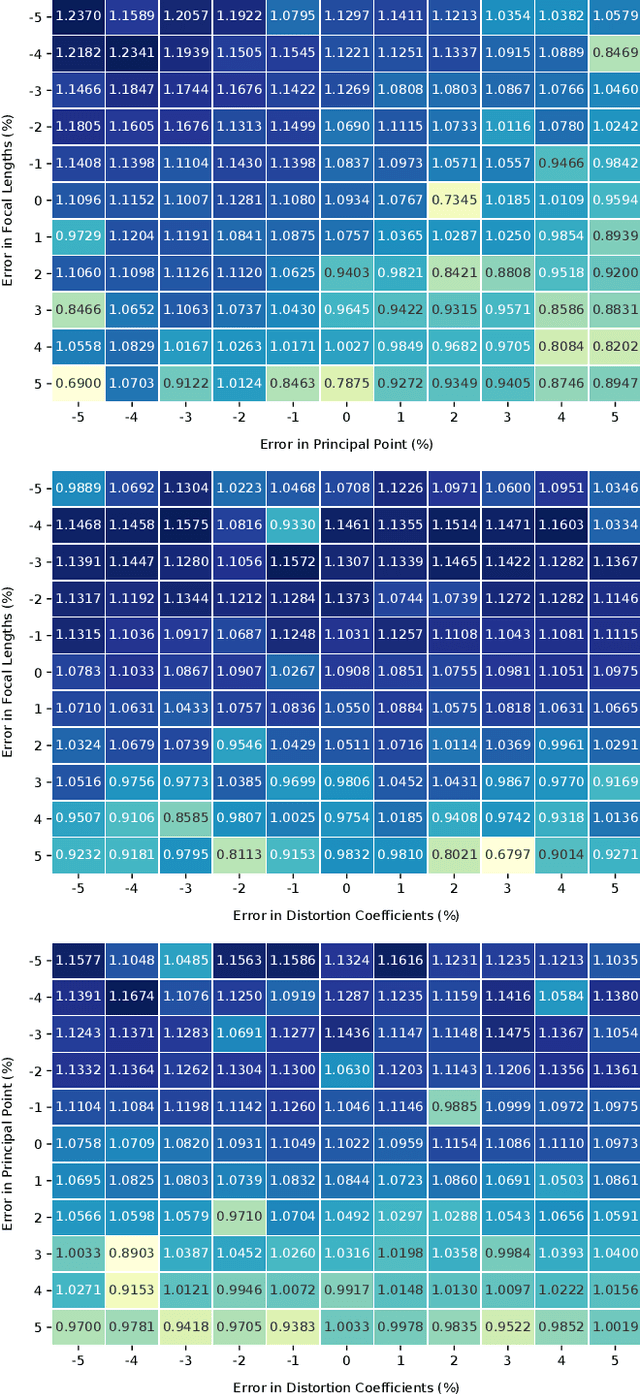
Autonomous vehicles and driver assistance systems utilize maps of 3D semantic landmarks for improved decision making. However, scaling the mapping process as well as regularly updating such maps come with a huge cost. Crowdsourced mapping of these landmarks such as traffic sign positions provides an appealing alternative. The state-of-the-art approaches to crowdsourced mapping use ground truth camera parameters, which may not always be known or may change over time. In this work, we demonstrate an approach to computing 3D traffic sign positions without knowing the camera focal lengths, principal point, and distortion coefficients a priori. We validate our proposed approach on a public dataset of traffic signs in KITTI. Using only a monocular color camera and GPS, we achieve an average single journey relative and absolute positioning accuracy of 0.26 m and 1.38 m, respectively.