 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Efficiency of Transformers for Resource-Constrained Devices
Jun 30, 2021
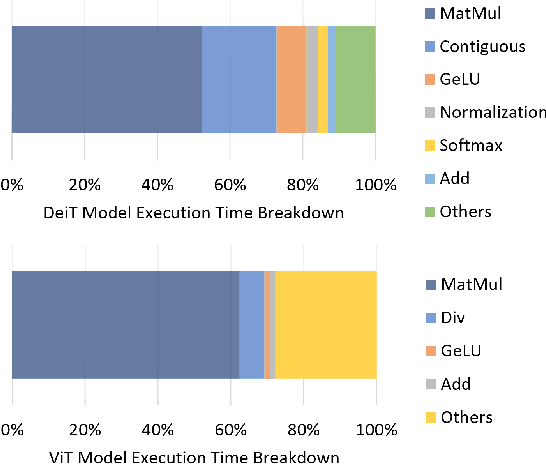
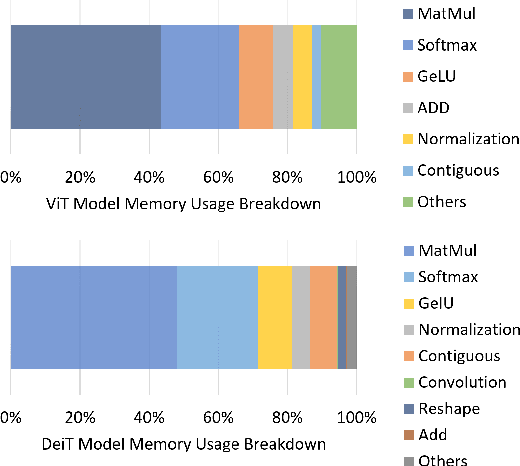
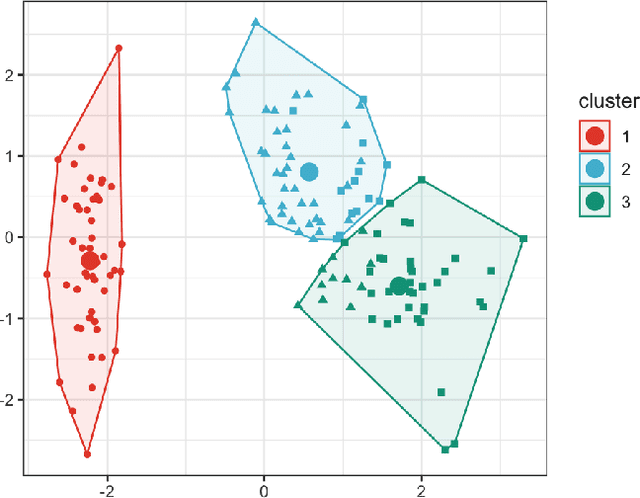
Transformers provide promising accuracy and have become popular and used in various domains such as natural language processing and computer vision. However, due to their massive number of model parameters, memory and computation requirements, they are not suitable for resource-constrained low-power devices. Even with high-performance and specialized devices, the memory bandwidth can become a performance-limiting bottleneck. In this paper, we present a performance analysis of state-of-the-art vision transformers on several devices. We propose to reduce the overall memory footprint and memory transfers by clustering the model parameters. We show that by using only 64 clusters to represent model parameters, it is possible to reduce the data transfer from the main memory by more than 4x, achieve up to 22% speedup and 39% energy savings on mobile devices with less than 0.1% accuracy loss.
Challenges and Obstacles Towards Deploying Deep Learning Models on Mobile Devices
May 06, 2021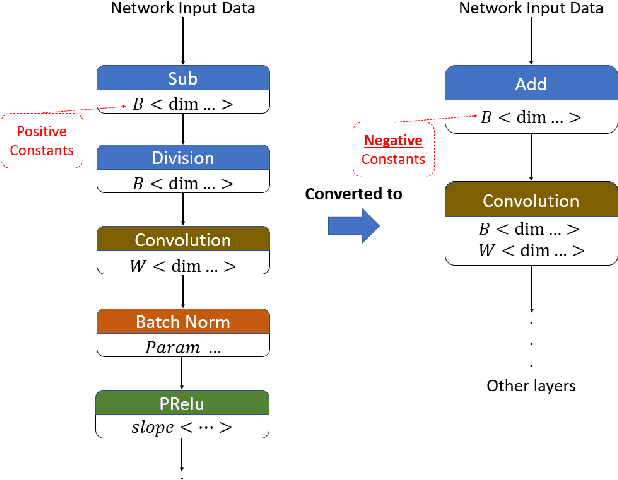
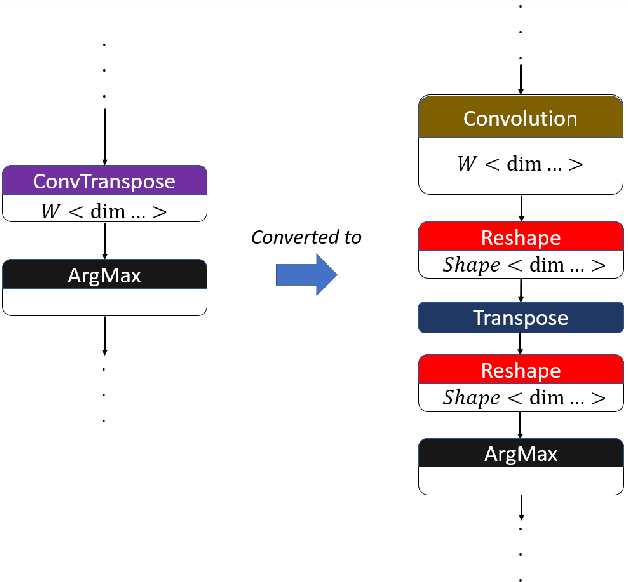
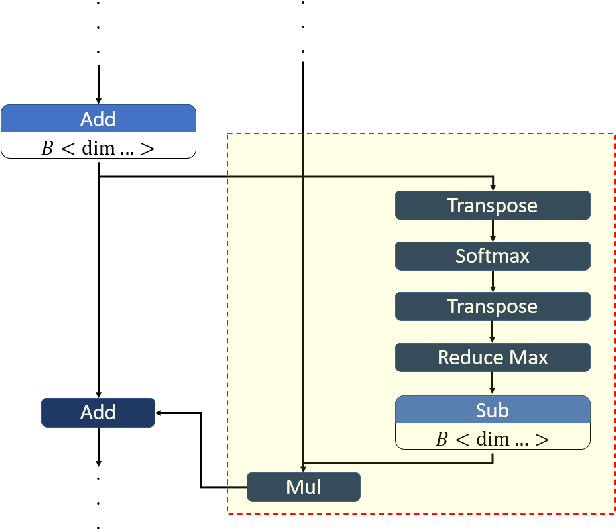
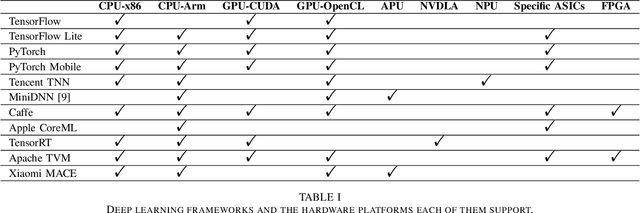
From computer vision and speech recognition to forecasting trajectories in autonomous vehicles, deep learning approaches are at the forefront of so many domains. Deep learning models are developed using plethora of high-level, generic frameworks and libraries. Running those models on the mobile devices require hardware-aware optimizations and in most cases converting the models to other formats or using a third-party framework. In reality, most of the developed models need to undergo a process of conversion, adaptation, and, in some cases, full retraining to match the requirements and features of the framework that is deploying the model on the target platform. Variety of hardware platforms with heterogeneous computing elements, from wearable devices to high-performance GPU clusters are used to run deep learning models. In this paper, we present the existing challenges, obstacles, and practical solutions towards deploying deep learning models on mobile devices.