 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic Atomic Skills for Multi-Task Robotic Manipulation
Dec 20, 2025While imitation learning has shown impressive results in single-task robot manipulation, scaling it to multi-task settings remains a fundamental challenge due to issues such as suboptimal demonstrations, trajectory noise, and behavioral multi-modality. Existing skill-based methods attempt to address this by decomposing actions into reusable abstractions, but they often rely on fixed-length segmentation or environmental priors that limit semantic consistency and cross-task generalization. In this work, we propose AtomSkill, a novel multi-task imitation learning framework that learns and leverages a structured Atomic Skill Space for composable robot manipulation. Our approach is built on two key technical contributions. First, we construct a Semantically Grounded Atomic Skill Library by partitioning demonstrations into variable-length skills using gripper-state keyframe detection and vision-language model annotation. A contrastive learning objective ensures the resulting skill embeddings are both semantically consistent and temporally coherent. Second, we propose an Action Generation module with Keypose Imagination, which jointly predicts a skill's long-horizon terminal keypose and its immediate action sequence. This enables the policy to reason about overarching motion goals and fine-grained control simultaneously, facilitating robust skill chaining. Extensive experiments in simulated and real-world environments show that AtomSkill consistently outperforms state-of-the-art methods across diverse manipulation tasks.
SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
Aug 28, 2025
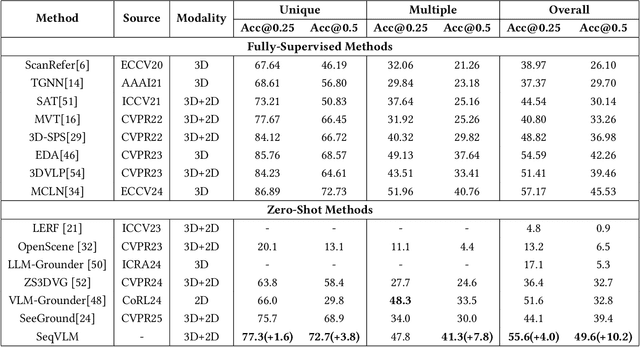

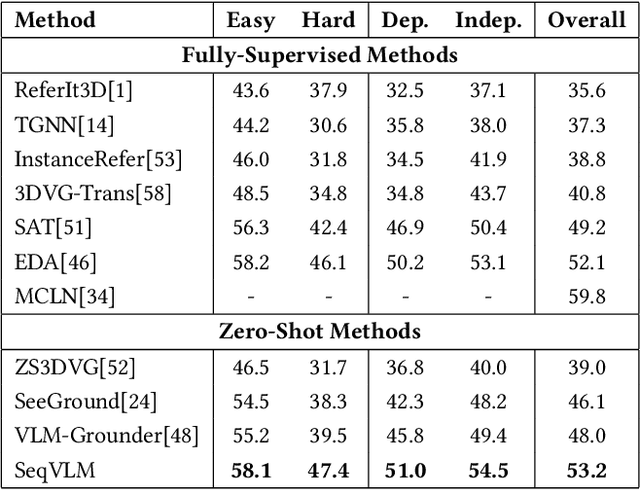
3D Visual Grounding (3DVG) aims to localize objects in 3D scenes using natural language descriptions. Although supervised methods achieve higher accuracy in constrained settings, zero-shot 3DVG holds greater promise for real-world applications since eliminating scene-specific training requirements. However, existing zero-shot methods face challenges of spatial-limited reasoning due to reliance on single-view localization, and contextual omissions or detail degradation. To address these issues, we propose SeqVLM, a novel zero-shot 3DVG framework that leverages multi-view real-world scene images with spatial information for target object reasoning. Specifically, SeqVLM first generates 3D instance proposals via a 3D semantic segmentation network and refines them through semantic filtering, retaining only semantic-relevant candidates. A proposal-guided multi-view projection strategy then projects these candidate proposals onto real scene image sequences, preserving spatial relationships and contextual details in the conversion process of 3D point cloud to images. Furthermore, to mitigate VLM computational overload, we implement a dynamic scheduling mechanism that iteratively processes sequances-query prompts, leveraging VLM's cross-modal reasoning capabilities to identify textually specified objects. Experiments on the ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, achieving Acc@0.25 scores of 55.6% and 53.2%, surpassing previous zero-shot methods by 4.0% and 5.2%, respectively, which advance 3DVG toward greater generalization and real-world applicability. The code is available at https://github.com/JiawLin/SeqVLM.
Multi-modal Multi-platform Person Re-Identification: Benchmark and Method
Mar 21, 2025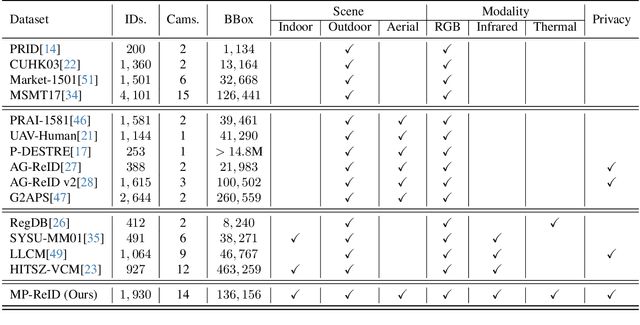

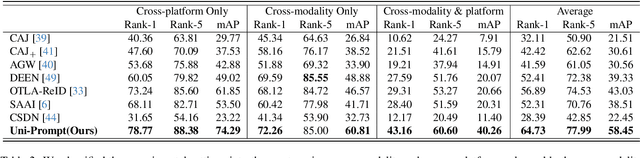
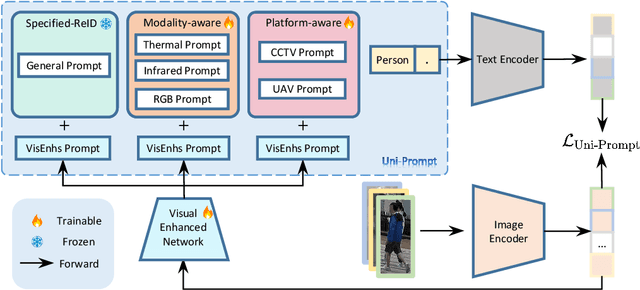
Conventional person re-identification (ReID) research is often limited to single-modality sensor data from static cameras, which fails to address the complexities of real-world scenarios where multi-modal signals are increasingly prevalent. For instance, consider an urban ReID system integrating stationary RGB cameras, nighttime infrared sensors, and UAVs equipped with dynamic tracking capabilities. Such systems face significant challenges due to variations in camera perspectives, lighting conditions, and sensor modalities, hindering effective person ReID. To address these challenges, we introduce the MP-ReID benchmark, a novel dataset designed specifically for multi-modality and multi-platform ReID. This benchmark uniquely compiles data from 1,930 identities across diverse modalities, including RGB, infrared, and thermal imaging, captured by both UAVs and ground-based cameras in indoor and outdoor environments. Building on this benchmark, we introduce Uni-Prompt ReID, a framework with specific-designed prompts, tailored for cross-modality and cross-platform scenarios. Our method consistently outperforms state-of-the-art approaches, establishing a robust foundation for future research in complex and dynamic ReID environments. Our dataset are available at:https://mp-reid.github.io/.
AffordDP: Generalizable Diffusion Policy with Transferable Affordance
Dec 04, 2024



Diffusion-based policies have shown impressive performance in robotic manipulation tasks while struggling with out-of-domain distributions. Recent efforts attempted to enhance generalization by improving the visual feature encoding for diffusion policy. However, their generalization is typically limited to the same category with similar appearances. Our key insight is that leveraging affordances--manipulation priors that define "where" and "how" an agent interacts with an object--can substantially enhance generalization to entirely unseen object instances and categories. We introduce the Diffusion Policy with transferable Affordance (AffordDP), designed for generalizable manipulation across novel categories. AffordDP models affordances through 3D contact points and post-contact trajectories, capturing the essential static and dynamic information for complex tasks. The transferable affordance from in-domain data to unseen objects is achieved by estimating a 6D transformation matrix using foundational vision models and point cloud registration techniques. More importantly, we incorporate affordance guidance during diffusion sampling that can refine action sequence generation. This guidance directs the generated action to gradually move towards the desired manipulation for unseen objects while keeping the generated action within the manifold of action space. Experimental results from both simulated and real-world environments demonstrate that AffordDP consistently outperforms previous diffusion-based methods, successfully generalizing to unseen instances and categories where others fail.