 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Human-Object Reconstruction in the Wild
Jul 31, 2024Learning the prior knowledge of the 3D human-object spatial relation is crucial for reconstructing human-object interaction from images and understanding how humans interact with objects in 3D space. Previous works learn this prior from datasets collected in controlled environments, but due to the diversity of domains, they struggle to generalize to real-world scenarios. To overcome this limitation, we present a 2D-supervised method that learns the 3D human-object spatial relation prior purely from 2D images in the wild. Our method utilizes a flow-based neural network to learn the prior distribution of the 2D human-object keypoint layout and viewports for each image in the dataset. The effectiveness of the prior learned from 2D images is demonstrated on the human-object reconstruction task by applying the prior to tune the relative pose between the human and the object during the post-optimization stage. To validate and benchmark our method on in-the-wild images, we collect the WildHOI dataset from the YouTube website, which consists of various interactions with 8 objects in real-world scenarios. We conduct the experiments on the indoor BEHAVE dataset and the outdoor WildHOI dataset. The results show that our method achieves almost comparable performance with fully 3D supervised methods on the BEHAVE dataset, even if we have only utilized the 2D layout information, and outperforms previous methods in terms of generality and interaction diversity on in-the-wild images.
StackFLOW: Monocular Human-Object Reconstruction by Stacked Normalizing Flow with Offset
Jul 30, 2024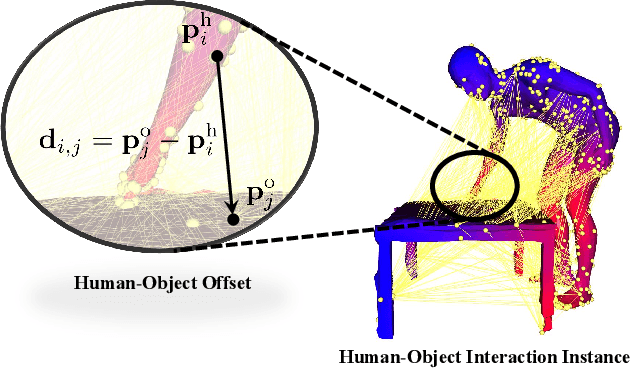
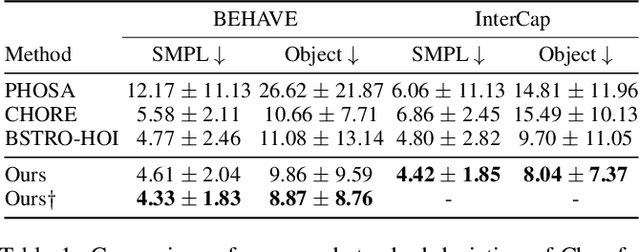

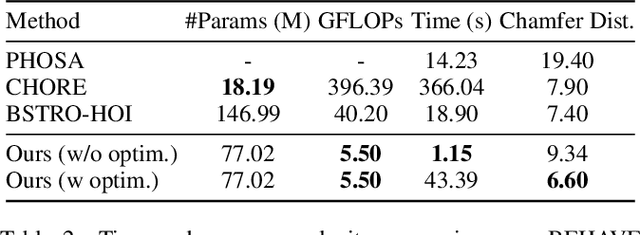
Modeling and capturing the 3D spatial arrangement of the human and the object is the key to perceiving 3D human-object interaction from monocular images. In this work, we propose to use the Human-Object Offset between anchors which are densely sampled from the surface of human mesh and object mesh to represent human-object spatial relation. Compared with previous works which use contact map or implicit distance filed to encode 3D human-object spatial relations, our method is a simple and efficient way to encode the highly detailed spatial correlation between the human and object. Based on this representation, we propose Stacked Normalizing Flow (StackFLOW) to infer the posterior distribution of human-object spatial relations from the image. During the optimization stage, we finetune the human body pose and object 6D pose by maximizing the likelihood of samples based on this posterior distribution and minimizing the 2D-3D corresponding reprojection loss. Extensive experimental results show that our method achieves impressive results on two challenging benchmarks, BEHAVE and InterCap datasets.