 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStackFLOW: Monocular Human-Object Reconstruction by Stacked Normalizing Flow with Offset
Paper and Code
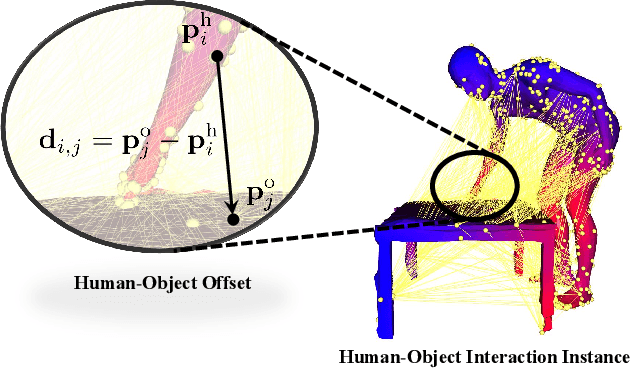
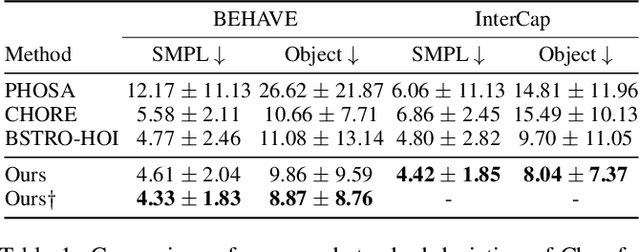

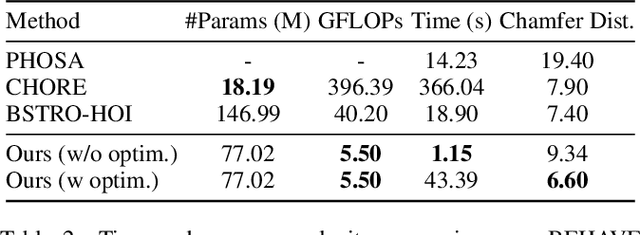
Modeling and capturing the 3D spatial arrangement of the human and the object is the key to perceiving 3D human-object interaction from monocular images. In this work, we propose to use the Human-Object Offset between anchors which are densely sampled from the surface of human mesh and object mesh to represent human-object spatial relation. Compared with previous works which use contact map or implicit distance filed to encode 3D human-object spatial relations, our method is a simple and efficient way to encode the highly detailed spatial correlation between the human and object. Based on this representation, we propose Stacked Normalizing Flow (StackFLOW) to infer the posterior distribution of human-object spatial relations from the image. During the optimization stage, we finetune the human body pose and object 6D pose by maximizing the likelihood of samples based on this posterior distribution and minimizing the 2D-3D corresponding reprojection loss. Extensive experimental results show that our method achieves impressive results on two challenging benchmarks, BEHAVE and InterCap datasets.