 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform Transformation: Refining Latent Representation in Variational Autoencoders
Jul 02, 2024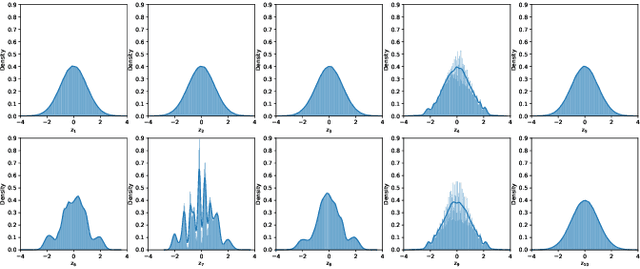
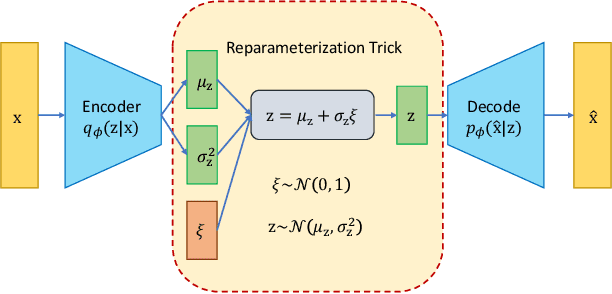
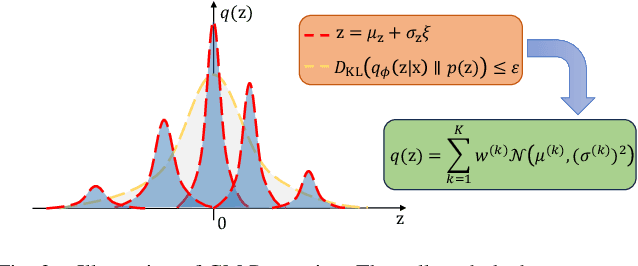
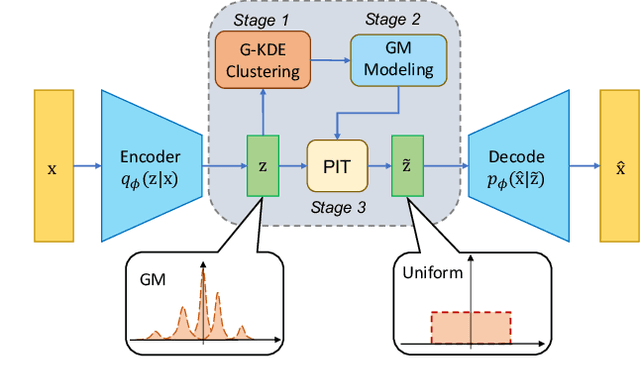
Irregular distribution in latent space causes posterior collapse, misalignment between posterior and prior, and ill-sampling problem in Variational Autoencoders (VAEs). In this paper, we introduce a novel adaptable three-stage Uniform Transformation (UT) module -- Gaussian Kernel Density Estimation (G-KDE) clustering, non-parametric Gaussian Mixture (GM) Modeling, and Probability Integral Transform (PIT) -- to address irregular latent distributions. By reconfiguring irregular distributions into a uniform distribution in the latent space, our approach significantly enhances the disentanglement and interpretability of latent representations, overcoming the limitation of traditional VAE models in capturing complex data structures. Empirical evaluations demonstrated the efficacy of our proposed UT module in improving disentanglement metrics across benchmark datasets -- dSprites and MNIST. Our findings suggest a promising direction for advancing representation learning techniques, with implication for future research in extending this framework to more sophisticated datasets and downstream tasks.
Ground Manipulator Primitive Tasks to Executable Actions using Large Language Models
Aug 13, 2023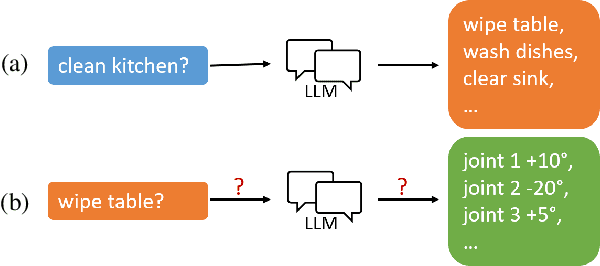


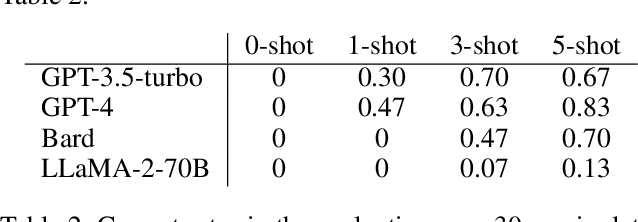
Layered architectures have been widely used in robot systems. The majority of them implement planning and execution functions in separate layers. However, there still lacks a straightforward way to transit high-level tasks in the planning layer to the low-level motor commands in the execution layer. In order to tackle this challenge, we propose a novel approach to ground the manipulator primitive tasks to robot low-level actions using large language models (LLMs). We designed a program-like prompt based on the task frame formalism. In this way, we enable LLMs to generate position/force set-points for hybrid control. Evaluations over several state-of-the-art LLMs are provided.
Robot Behavior-Tree-Based Task Generation with Large Language Models
Feb 24, 2023Nowadays, the behavior tree is gaining popularity as a representation for robot tasks due to its modularity and reusability. Designing behavior-tree tasks manually is time-consuming for robot end-users, thus there is a need for investigating automatic behavior-tree-based task generation. Prior behavior-tree-based task generation approaches focus on fixed primitive tasks and lack generalizability to new task domains. To cope with this issue, we propose a novel behavior-tree-based task generation approach that utilizes state-of-the-art large language models. We propose a Phase-Step prompt design that enables a hierarchical-structured robot task generation and further integrate it with behavior-tree-embedding-based search to set up the appropriate prompt. In this way, we enable an automatic and cross-domain behavior-tree task generation. Our behavior-tree-based task generation approach does not require a set of pre-defined primitive tasks. End-users only need to describe an abstract desired task and our proposed approach can swiftly generate the corresponding behavior tree. A full-process case study is provided to demonstrate our proposed approach. An ablation study is conducted to evaluate the effectiveness of our Phase-Step prompts. Assessment on Phase-Step prompts and the limitation of large language models are presented and discussed.
A Multi-stage Framework with Mean Subspace Computation and Recursive Feedback for Online Unsupervised Domain Adaptation
Jun 24, 2022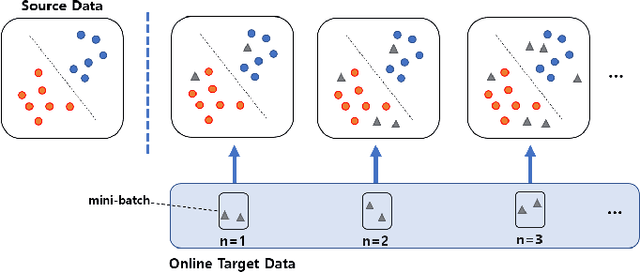
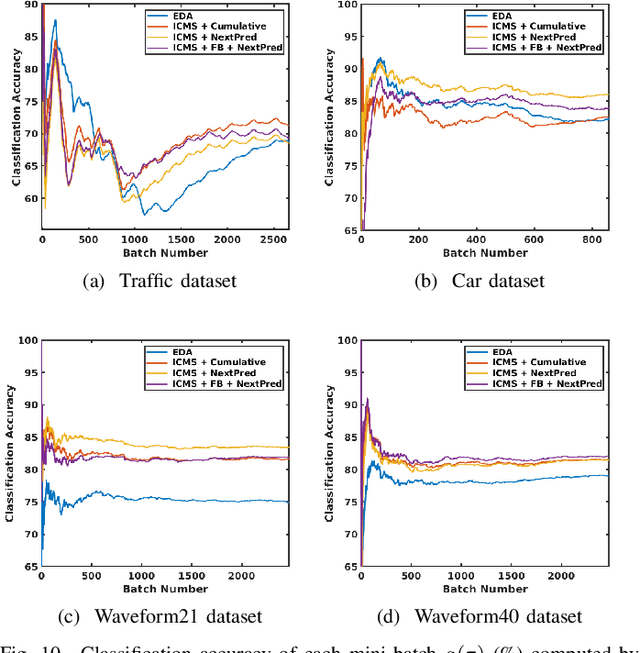
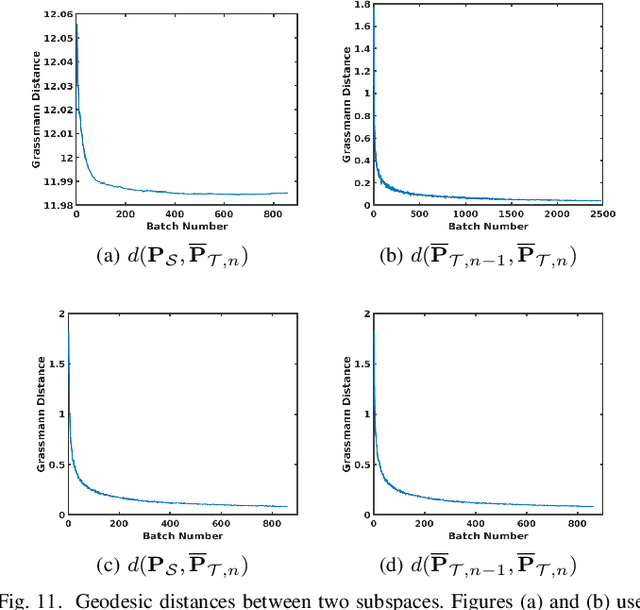
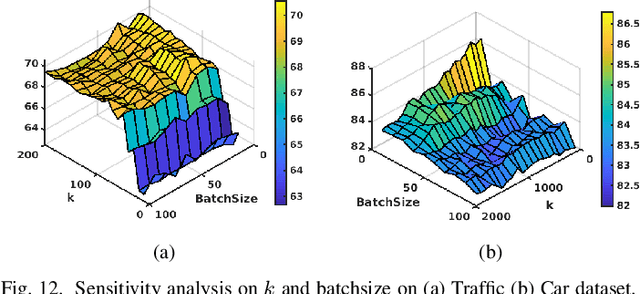
In this paper, we address the Online Unsupervised Domain Adaptation (OUDA) problem and propose a novel multi-stage framework to solve real-world situations when the target data are unlabeled and arriving online sequentially in batches. To project the data from the source and the target domains to a common subspace and manipulate the projected data in real-time, our proposed framework institutes a novel method, called an Incremental Computation of Mean-Subspace (ICMS) technique, which computes an approximation of mean-target subspace on a Grassmann manifold and is proven to be a close approximate to the Karcher mean. Furthermore, the transformation matrix computed from the mean-target subspace is applied to the next target data in the recursive-feedback stage, aligning the target data closer to the source domain. The computation of transformation matrix and the prediction of next-target subspace leverage the performance of the recursive-feedback stage by considering the cumulative temporal dependency among the flow of the target subspace on the Grassmann manifold. The labels of the transformed target data are predicted by the pre-trained source classifier, then the classifier is updated by the transformed data and predicted labels. Extensive experiments on six datasets were conducted to investigate in depth the effect and contribution of each stage in our proposed framework and its performance over previous approaches in terms of classification accuracy and computational speed. In addition, the experiments on traditional manifold-based learning models and neural-network-based learning models demonstrated the applicability of our proposed framework for various types of learning models.
Global-Position Tracking Control of 3-D Bipedal Walking via Virtual Constraint Design and Multiple Lyapunov Analysis
Aug 08, 2021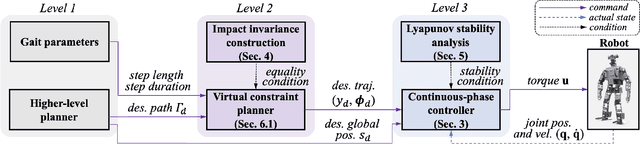
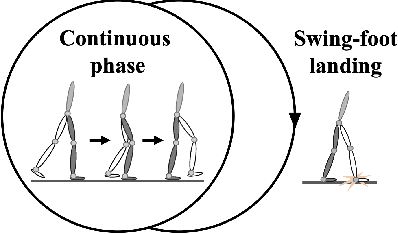
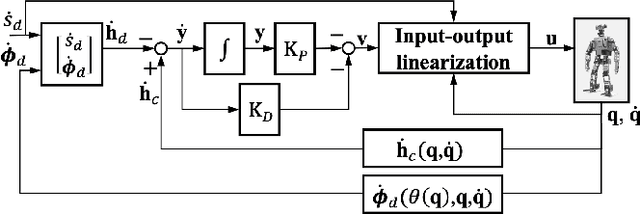
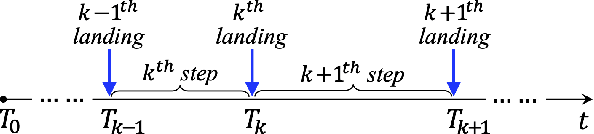
A safety-critical measure of legged locomotion performance is a robot's ability to track its desired time-varying position trajectory in an environment, which is herein termed as "global-position tracking". This paper introduces a nonlinear control approach that achieves asymptotic global-position tracking for three-dimensional (3-D) bipedal robot walking. Designing a global-position tracking controller presents a challenging problem due to the complex hybrid robot model and the time-varying desired global-position trajectory. Towards tackling this problem, the first main contribution is the construction of impact invariance to ensure all desired trajectories respect the foot-landing impact dynamics, which is a necessary condition for realizing asymptotic tracking of hybrid walking systems. Thanks to their independence of the desired global position, these conditions can be exploited to decouple the higher-level planning of the global position and the lower-level planning of the remaining trajectories, thereby greatly alleviating the computational burden of motion planning. The second main contribution is the Lyapunov-based stability analysis of the hybrid closed-loop system, which produces sufficient conditions to guide the controller design for achieving asymptotic global-position tracking during fully actuated walking. Simulations and experiments on a 3-D bipedal robot with twenty revolute joints confirm the validity of the proposed control approach in guaranteeing accurate tracking.
Few-shot Image Recognition with Manifolds
Oct 22, 2020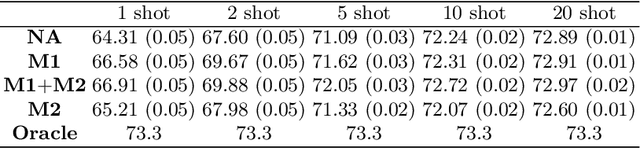
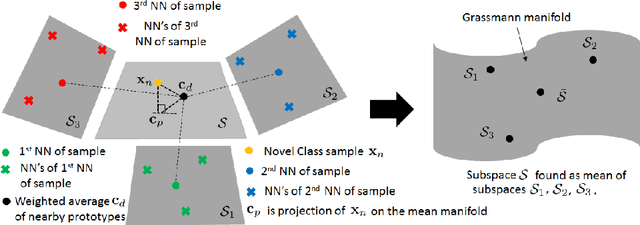
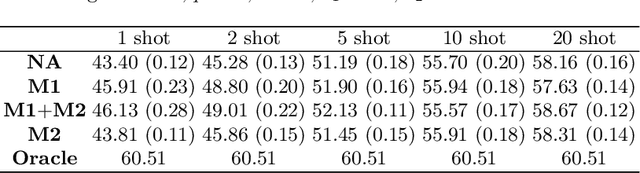

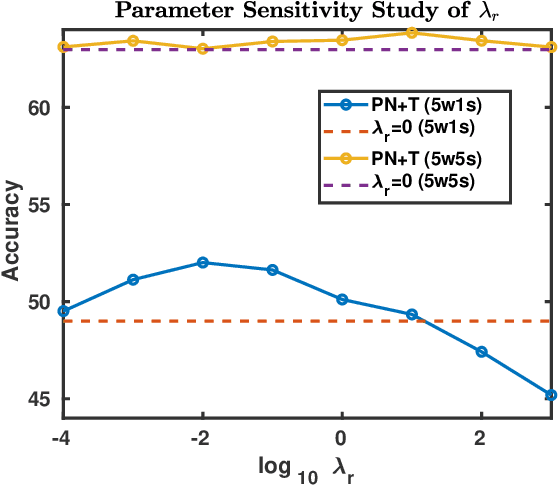
In this paper, we extend the traditional few-shot learning (FSL) problem to the situation when the source-domain data is not accessible but only high-level information in the form of class prototypes is available. This limited information setup for the FSL problem deserves much attention due to its implication of privacy-preserving inaccessibility to the source-domain data but it has rarely been addressed before. Because of limited training data, we propose a non-parametric approach to this FSL problem by assuming that all the class prototypes are structurally arranged on a manifold. Accordingly, we estimate the novel-class prototype locations by projecting the few-shot samples onto the average of the subspaces on which the surrounding classes lie. During classification, we again exploit the structural arrangement of the categories by inducing a Markov chain on the graph constructed with the class prototypes. This manifold distance obtained using the Markov chain is expected to produce better results compared to a traditional nearest-neighbor-based Euclidean distance. To evaluate our proposed framework, we have tested it on two image datasets - the large-scale ImageNet and the small-scale but fine-grained CUB-200. We have also studied parameter sensitivity to better understand our framework.
Multi-step Online Unsupervised Domain Adaptation
Feb 20, 2020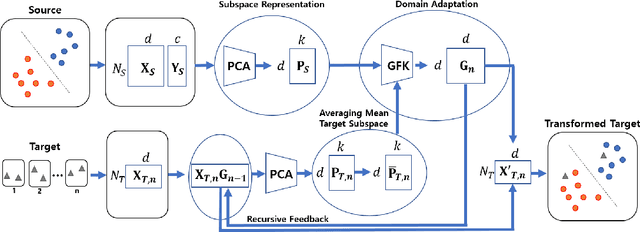
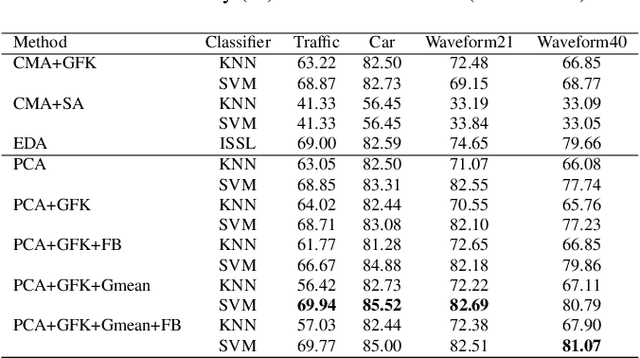
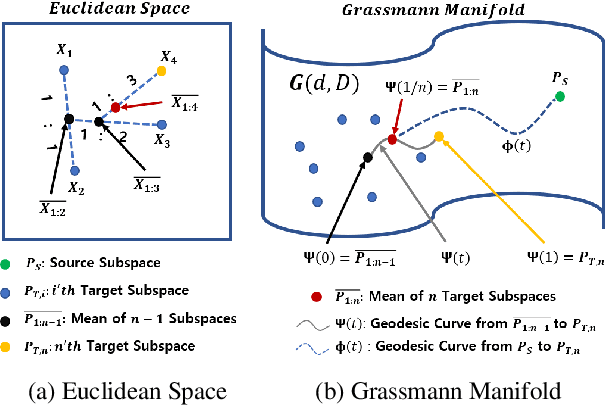

In this paper, we address the Online Unsupervised Domain Adaptation (OUDA) problem, where the target data are unlabelled and arriving sequentially. The traditional methods on the OUDA problem mainly focus on transforming each arriving target data to the source domain, and they do not sufficiently consider the temporal coherency and accumulative statistics among the arriving target data. We propose a multi-step framework for the OUDA problem, which institutes a novel method to compute the mean-target subspace inspired by the geometrical interpretation on the Euclidean space. This mean-target subspace contains accumulative temporal information among the arrived target data. Moreover, the transformation matrix computed from the mean-target subspace is applied to the next target data as a preprocessing step, aligning the target data closer to the source domain. Experiments on four datasets demonstrated the contribution of each step in our proposed multi-step OUDA framework and its performance over previous approaches.
A Two-Stage Approach to Few-Shot Learning for Image Recognition
Dec 10, 2019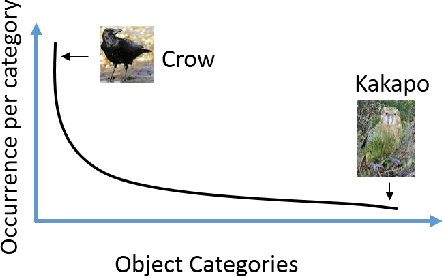
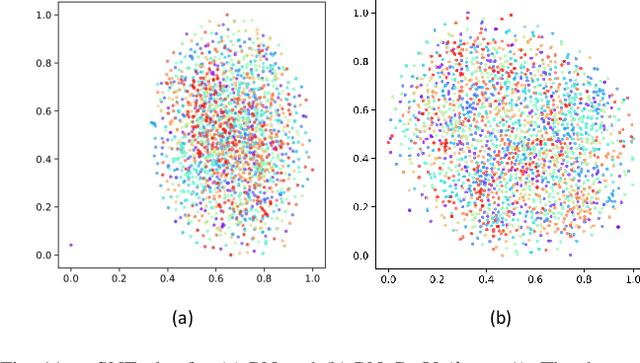
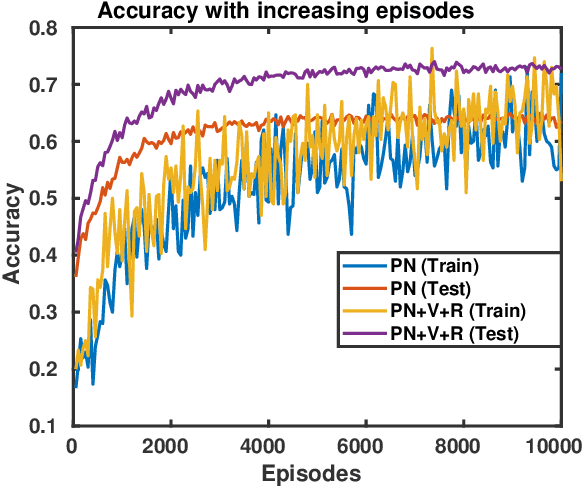
This paper proposes a multi-layer neural network structure for few-shot image recognition of novel categories. The proposed multi-layer neural network architecture encodes transferable knowledge extracted from a large annotated dataset of base categories. This architecture is then applied to novel categories containing only a few samples. The transfer of knowledge is carried out at the feature-extraction and the classification levels distributed across the two training stages. In the first-training stage, we introduce the relative feature to capture the structure of the data as well as obtain a low-dimensional discriminative space. Secondly, we account for the variable variance of different categories by using a network to predict the variance of each class. Classification is then performed by computing the Mahalanobis distance to the mean-class representation in contrast to previous approaches that used the Euclidean distance. In the second-training stage, a category-agnostic mapping is learned from the mean-sample representation to its corresponding class-prototype representation. This is because the mean-sample representation may not accurately represent the novel category prototype. Finally, we evaluate the proposed network structure on four standard few-shot image recognition datasets, where our proposed few-shot learning system produces competitive performance compared to previous work. We also extensively studied and analyzed the contribution of each component of our proposed framework.
Zero-shot Image Recognition Using Relational Matching, Adaptation and Calibration
Mar 27, 2019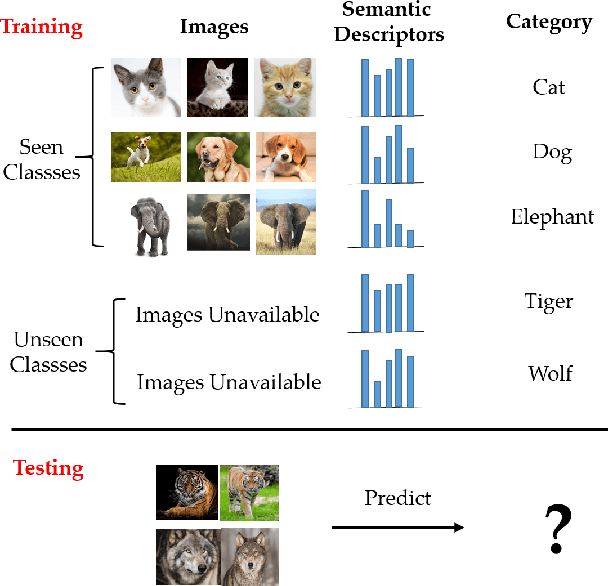
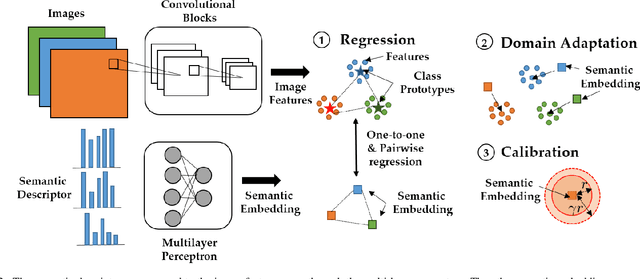
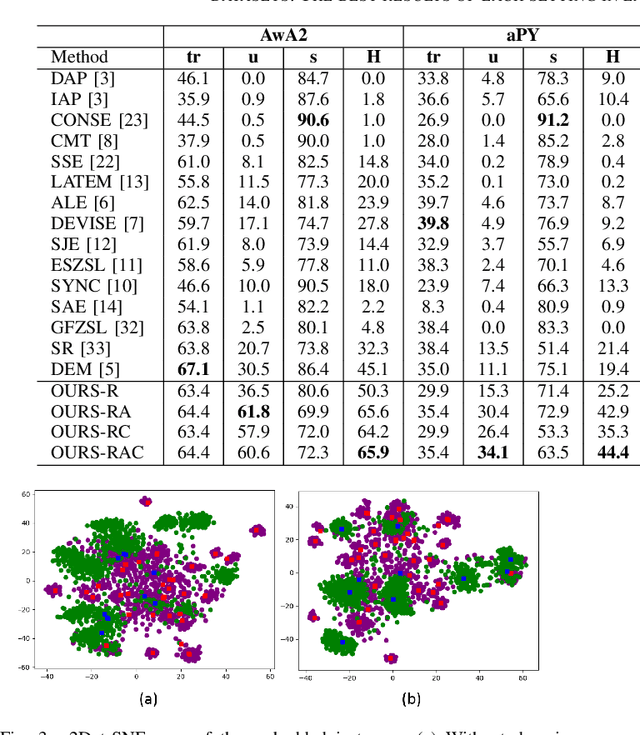
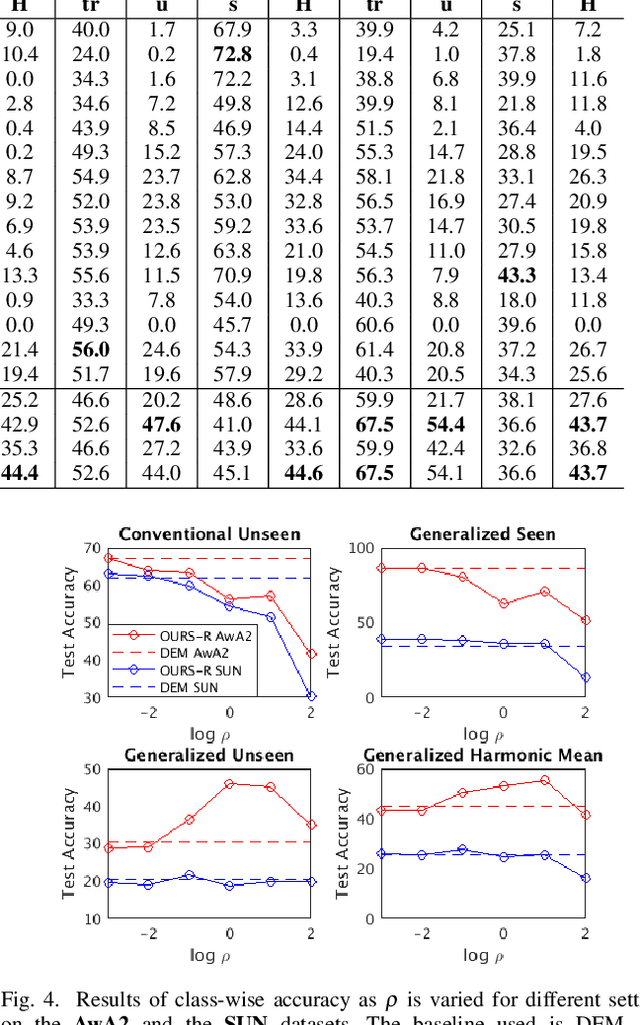
Zero-shot learning (ZSL) for image classification focuses on recognizing novel categories that have no labeled data available for training. The learning is generally carried out with the help of mid-level semantic descriptors associated with each class. This semantic-descriptor space is generally shared by both seen and unseen categories. However, ZSL suffers from hubness, domain discrepancy and biased-ness towards seen classes. To tackle these problems, we propose a three-step approach to zero-shot learning. Firstly, a mapping is learned from the semantic-descriptor space to the image-feature space. This mapping learns to minimize both one-to-one and pairwise distances between semantic embeddings and the image features of the corresponding classes. Secondly, we propose test-time domain adaptation to adapt the semantic embedding of the unseen classes to the test data. This is achieved by finding correspondences between the semantic descriptors and the image features. Thirdly, we propose scaled calibration on the classification scores of the seen classes. This is necessary because the ZSL model is biased towards seen classes as the unseen classes are not used in the training. Finally, to validate the proposed three-step approach, we performed experiments on four benchmark datasets where the proposed method outperformed previous results. We also studied and analyzed the performance of each component of our proposed ZSL framework.
Unsupervised Domain Adaptation using Regularized Hyper-graph Matching
May 22, 2018
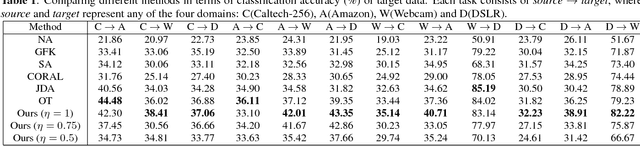
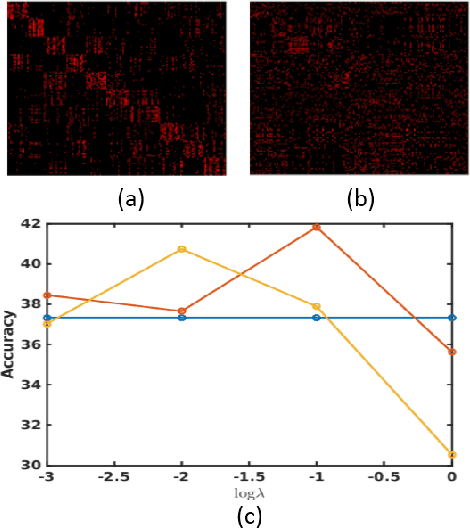
Domain adaptation (DA) addresses the real-world image classification problem of discrepancy between training (source) and testing (target) data distributions. We propose an unsupervised DA method that considers the presence of only unlabelled data in the target domain. Our approach centers on finding matches between samples of the source and target domains. The matches are obtained by treating the source and target domains as hyper-graphs and carrying out a class-regularized hyper-graph matching using first-, second- and third-order similarities between the graphs. We have also developed a computationally efficient algorithm by initially selecting a subset of the samples to construct a graph and then developing a customized optimization routine for graph-matching based on Conditional Gradient and Alternating Direction Multiplier Method. This allows the proposed method to be used widely. We also performed a set of experiments on standard object recognition datasets to validate the effectiveness of our framework over state-of-the-art approaches.