 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Test-Time Adaptation for Vision-Language Models
Mar 12, 2025Test-time adaptation with pre-trained vision-language models, such as CLIP, aims to adapt the model to new, potentially out-of-distribution test data. Existing methods calculate the similarity between visual embedding and learnable class embeddings, which are initialized by text embeddings, for zero-shot image classification. In this work, we first analyze this process based on Bayes theorem, and observe that the core factors influencing the final prediction are the likelihood and the prior. However, existing methods essentially focus on adapting class embeddings to adapt likelihood, but they often ignore the importance of prior. To address this gap, we propose a novel approach, \textbf{B}ayesian \textbf{C}lass \textbf{A}daptation (BCA), which in addition to continuously updating class embeddings to adapt likelihood, also uses the posterior of incoming samples to continuously update the prior for each class embedding. This dual updating mechanism allows the model to better adapt to distribution shifts and achieve higher prediction accuracy. Our method not only surpasses existing approaches in terms of performance metrics but also maintains superior inference rates and memory usage, making it highly efficient and practical for real-world applications.
Rethinking Weak-to-Strong Augmentation in Source-Free Domain Adaptive Object Detection
Oct 07, 2024



Source-Free domain adaptive Object Detection (SFOD) aims to transfer a detector (pre-trained on source domain) to new unlabelled target domains. Current SFOD methods typically follow the Mean Teacher framework, where weak-to-strong augmentation provides diverse and sharp contrast for self-supervised learning. However, this augmentation strategy suffers from an inherent problem called crucial semantics loss: Due to random, strong disturbance, strong augmentation is prone to losing typical visual components, hindering cross-domain feature extraction. To address this thus-far ignored limitation, this paper introduces a novel Weak-to-Strong Contrastive Learning (WSCoL) approach. The core idea is to distill semantics lossless knowledge in the weak features (from the weak/teacher branch) to guide the representation learning upon the strong features (from the strong/student branch). To achieve this, we project the original features into a shared space using a mapping network, thereby reducing the bias between the weak and strong features. Meanwhile, a weak features-guided contrastive learning is performed in a weak-to-strong manner alternatively. Specifically, we first conduct an adaptation-aware prototype-guided clustering on the weak features to generate pseudo labels for corresponding strong features matched through proposals. Sequentially, we identify positive-negative samples based on the pseudo labels and perform cross-category contrastive learning on the strong features where an uncertainty estimator encourages adaptive background contrast. Extensive experiments demonstrate that WSCoL yields new state-of-the-art performance, offering a built-in mechanism mitigating crucial semantics loss for traditional Mean Teacher framework. The code and data will be released soon.
Training all-mechanical neural networks for task learning through in situ backpropagation
Apr 23, 2024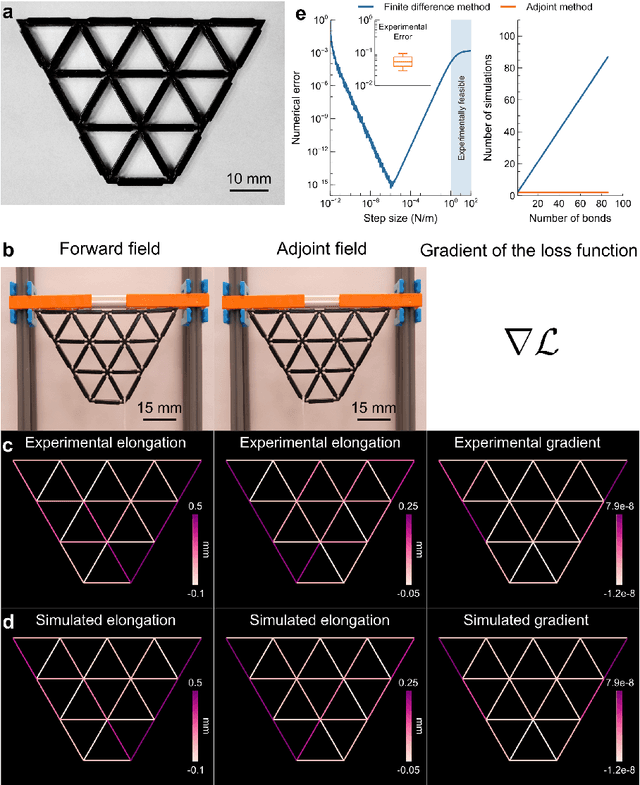
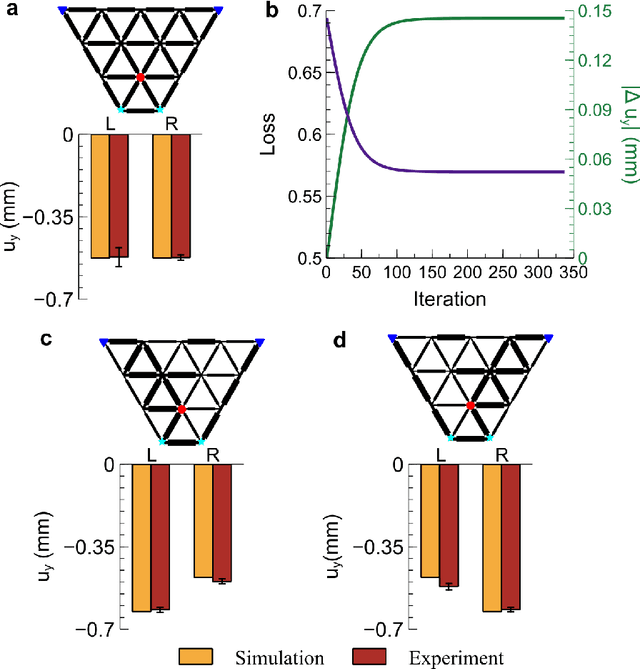
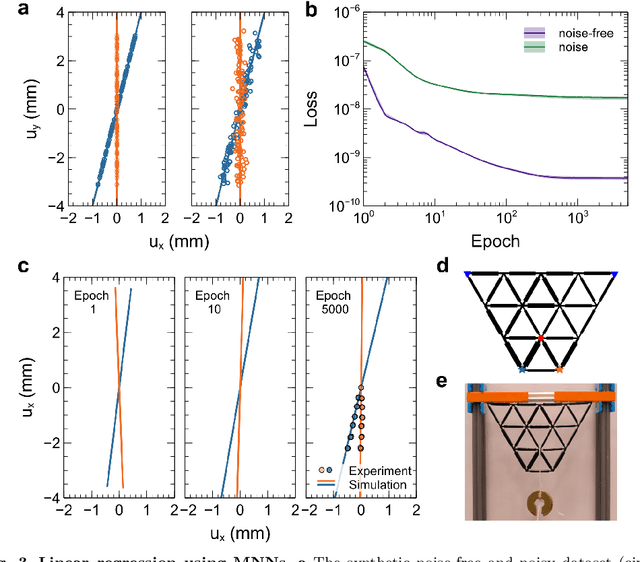
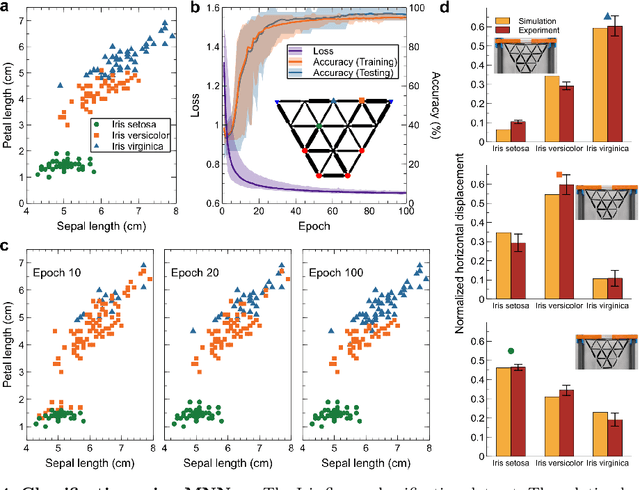
Recent advances unveiled physical neural networks as promising machine learning platforms, offering faster and more energy-efficient information processing. Compared with extensively-studied optical neural networks, the development of mechanical neural networks (MNNs) remains nascent and faces significant challenges, including heavy computational demands and learning with approximate gradients. Here, we introduce the mechanical analogue of in situ backpropagation to enable highly efficient training of MNNs. We demonstrate that the exact gradient can be obtained locally in MNNs, enabling learning through their immediate vicinity. With the gradient information, we showcase the successful training of MNNs for behavior learning and machine learning tasks, achieving high accuracy in regression and classification. Furthermore, we present the retrainability of MNNs involving task-switching and damage, demonstrating the resilience. Our findings, which integrate the theory for training MNNs and experimental and numerical validations, pave the way for mechanical machine learning hardware and autonomous self-learning material systems.