 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Paper and Code
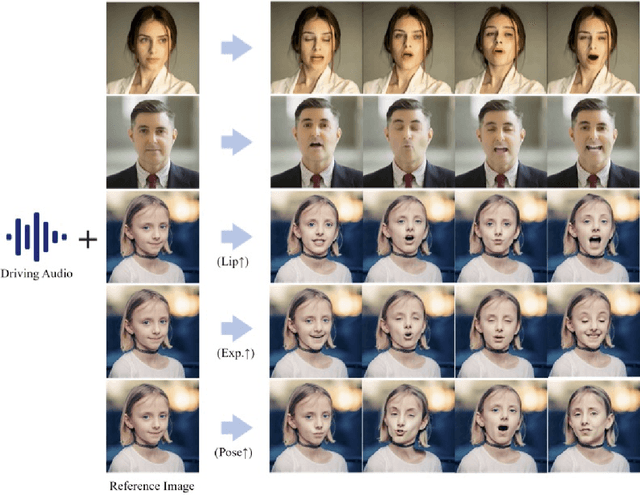
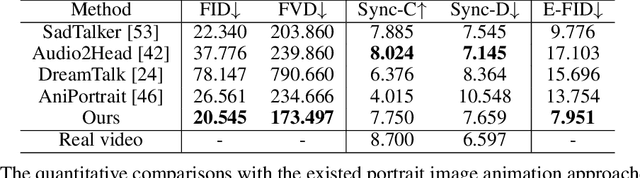
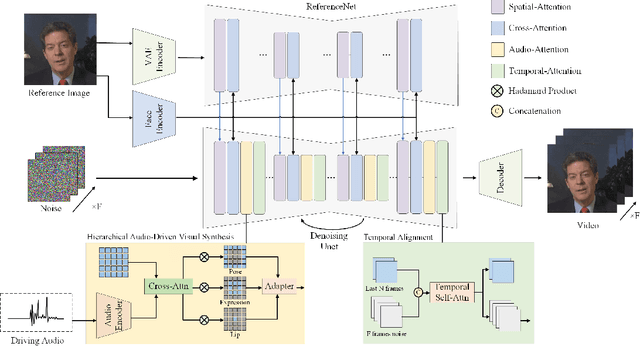
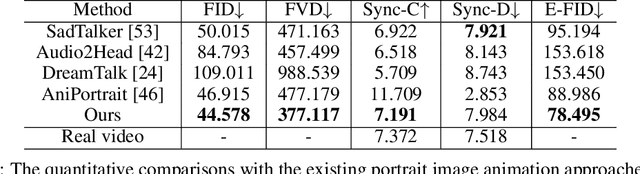
The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.