 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
Jun 24, 2022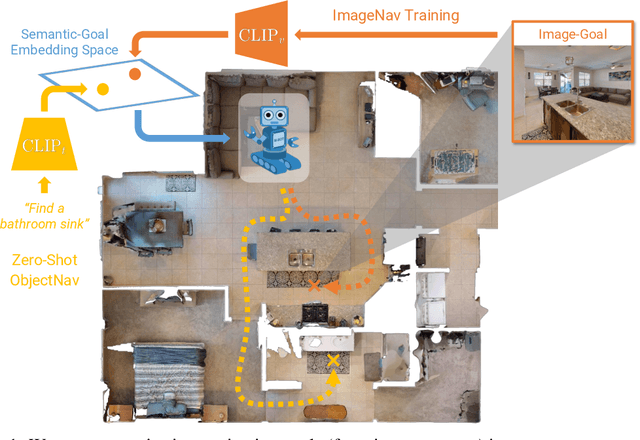

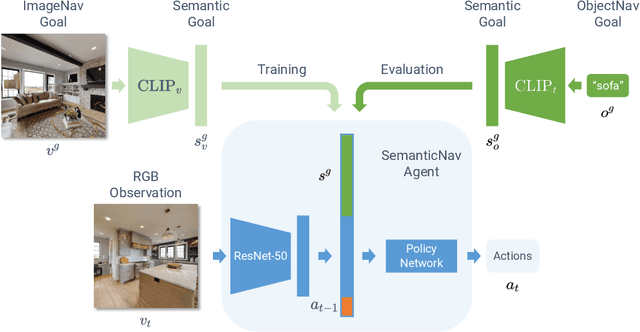
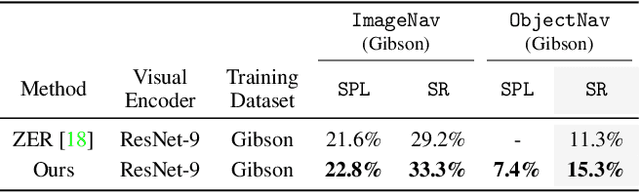
We present a scalable approach for learning open-world object-goal navigation (ObjectNav) -- the task of asking a virtual robot (agent) to find any instance of an object in an unexplored environment (e.g., "find a sink"). Our approach is entirely zero-shot -- i.e., it does not require ObjectNav rewards or demonstrations of any kind. Instead, we train on the image-goal navigation (ImageNav) task, in which agents find the location where a picture (i.e., goal image) was captured. Specifically, we encode goal images into a multimodal, semantic embedding space to enable training semantic-goal navigation (SemanticNav) agents at scale in unannotated 3D environments (e.g., HM3D). After training, SemanticNav agents can be instructed to find objects described in free-form natural language (e.g., "sink", "bathroom sink", etc.) by projecting language goals into the same multimodal, semantic embedding space. As a result, our approach enables open-world ObjectNav. We extensively evaluate our agents on three ObjectNav datasets (Gibson, HM3D, and MP3D) and observe absolute improvements in success of 4.2% - 20.0% over existing zero-shot methods. For reference, these gains are similar or better than the 5% improvement in success between the Habitat 2020 and 2021 ObjectNav challenge winners. In an open-world setting, we discover that our agents can generalize to compound instructions with a room explicitly mentioned (e.g., "Find a kitchen sink") and when the target room can be inferred (e.g., "Find a sink and a stove").
Dance2Music: Automatic Dance-driven Music Generation
Jul 20, 2021

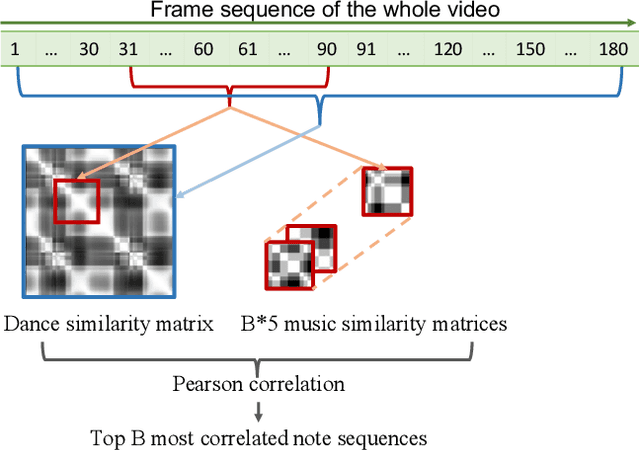
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.
Neuro-Symbolic Generative Art: A Preliminary Study
Jul 04, 2020


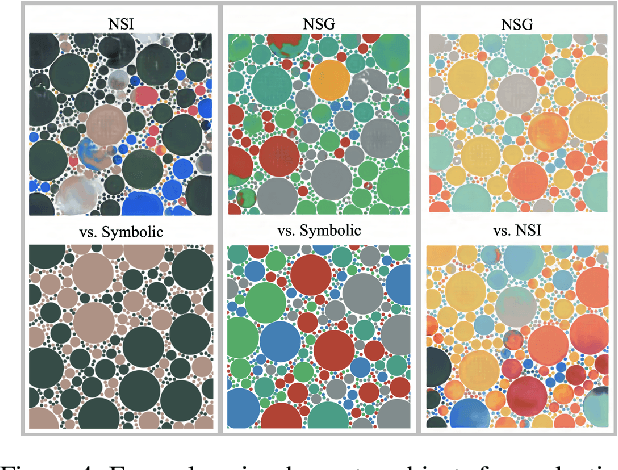
There are two classes of generative art approaches: neural, where a deep model is trained to generate samples from a data distribution, and symbolic or algorithmic, where an artist designs the primary parameters and an autonomous system generates samples within these constraints. In this work, we propose a new hybrid genre: neuro-symbolic generative art. As a preliminary study, we train a generative deep neural network on samples from the symbolic approach. We demonstrate through human studies that subjects find the final artifacts and the creation process using our neuro-symbolic approach to be more creative than the symbolic approach 61% and 82% of the time respectively.
On the Benefits of Models with Perceptually-Aligned Gradients
May 04, 2020



Adversarial robust models have been shown to learn more robust and interpretable features than standard trained models. As shown in [\cite{tsipras2018robustness}], such robust models inherit useful interpretable properties where the gradient aligns perceptually well with images, and adding a large targeted adversarial perturbation leads to an image resembling the target class. We perform experiments to show that interpretable and perceptually aligned gradients are present even in models that do not show high robustness to adversarial attacks. Specifically, we perform adversarial training with attack for different max-perturbation bound. Adversarial training with low max-perturbation bound results in models that have interpretable features with only slight drop in performance over clean samples. In this paper, we leverage models with interpretable perceptually-aligned features and show that adversarial training with low max-perturbation bound can improve the performance of models for zero-shot and weakly supervised localization tasks.
cFineGAN: Unsupervised multi-conditional fine-grained image generation
Dec 06, 2019
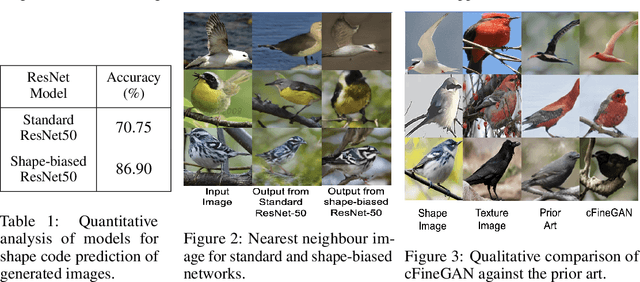


We propose an unsupervised multi-conditional image generation pipeline: cFineGAN, that can generate an image conditioned on two input images such that the generated image preserves the texture of one and the shape of the other input. To achieve this goal, we extend upon the recently proposed work of FineGAN \citep{singh2018finegan} and make use of standard as well as shape-biased pre-trained ImageNet models. We demonstrate both qualitatively as well as quantitatively the benefit of using the shape-biased network. We present our image generation result across three benchmark datasets- CUB-200-2011, Stanford Dogs and UT Zappos50k.