 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn LASSO Inference for High Dimensional Predictive Regression
Sep 16, 2024LASSO introduces shrinkage bias into estimated coefficients, which can adversely affect the desirable asymptotic normality and invalidate the standard inferential procedure based on the $t$-statistic. The desparsified LASSO has emerged as a well-known remedy for this issue. In the context of high dimensional predictive regression, the desparsified LASSO faces an additional challenge: the Stambaugh bias arising from nonstationary regressors. To restore the standard inferential procedure, we propose a novel estimator called IVX-desparsified LASSO (XDlasso). XDlasso eliminates the shrinkage bias and the Stambaugh bias simultaneously and does not require prior knowledge about the identities of nonstationary and stationary regressors. We establish the asymptotic properties of XDlasso for hypothesis testing, and our theoretical findings are supported by Monte Carlo simulations. Applying our method to real-world applications from the FRED-MD database -- which includes a rich set of control variables -- we investigate two important empirical questions: (i) the predictability of the U.S. stock returns based on the earnings-price ratio, and (ii) the predictability of the U.S. inflation using the unemployment rate.
On LASSO for High Dimensional Predictive Regression
Dec 14, 2022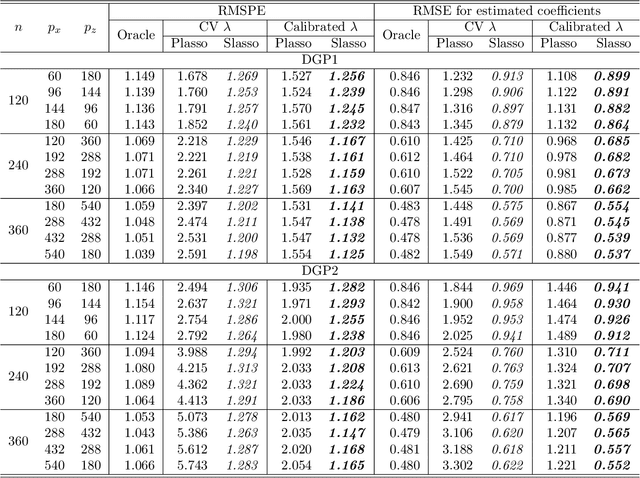
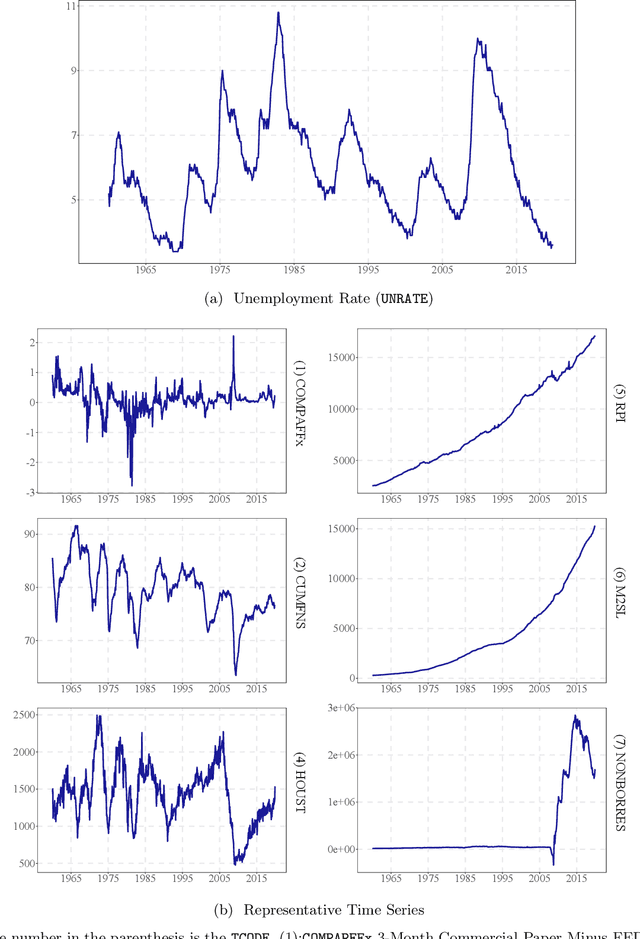
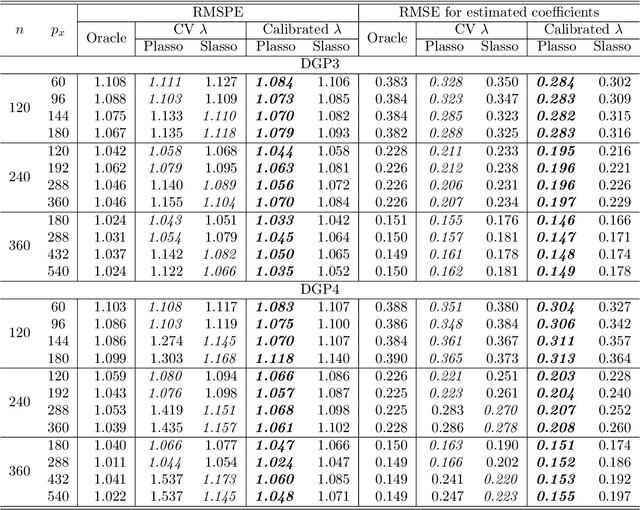
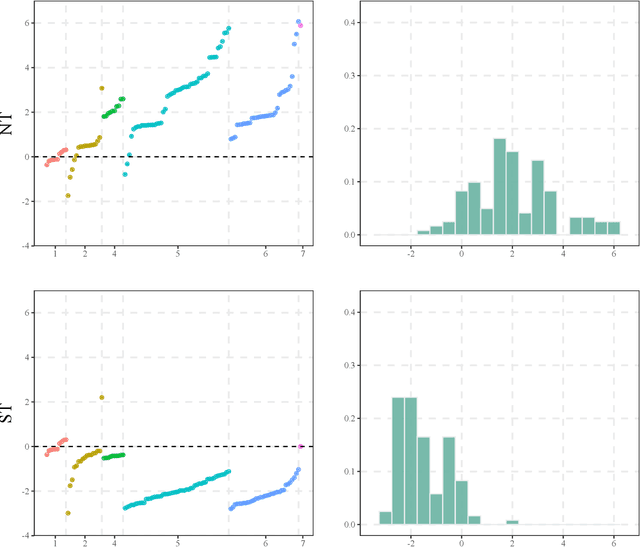
In a high dimensional linear predictive regression where the number of potential predictors can be larger than the sample size, we consider using LASSO, a popular L1-penalized regression method, to estimate the sparse coefficients when many unit root regressors are present. Consistency of LASSO relies on two building blocks: the deviation bound of the cross product of the regressors and the error term, and the restricted eigenvalue of the Gram matrix of the regressors. In our setting where unit root regressors are driven by temporal dependent non-Gaussian innovations, we establish original probabilistic bounds for these two building blocks. The bounds imply that the rates of convergence of LASSO are different from those in the familiar cross sectional case. In practical applications given a mixture of stationary and nonstationary predictors, asymptotic guarantee of LASSO is preserved if all predictors are scale-standardized. In an empirical example of forecasting the unemployment rate with many macroeconomic time series, strong performance is delivered by LASSO when the initial specification is guided by macroeconomic domain expertise.
The boosted HP filter is more general than you might think
Sep 20, 2022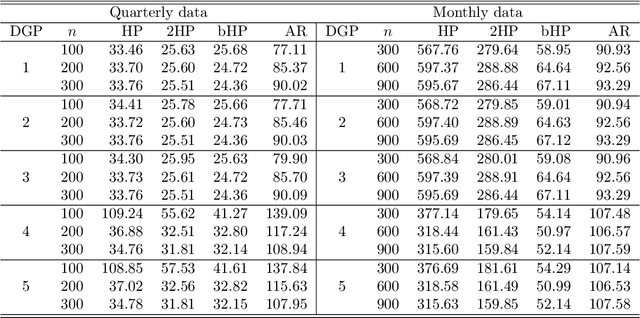
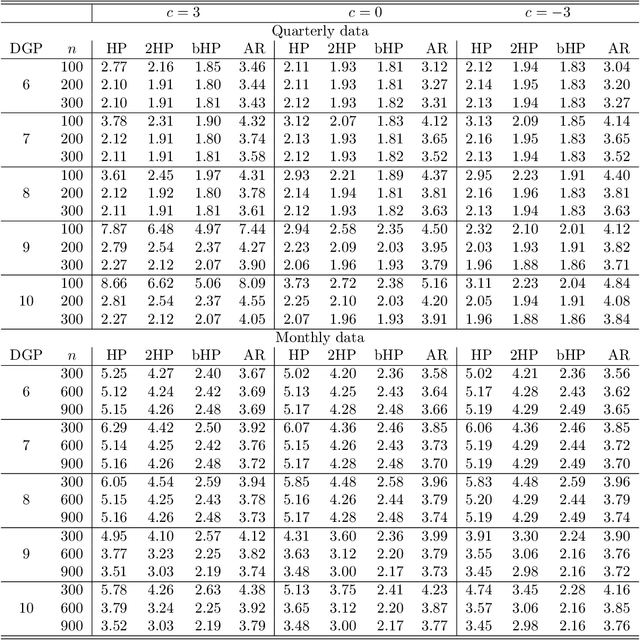
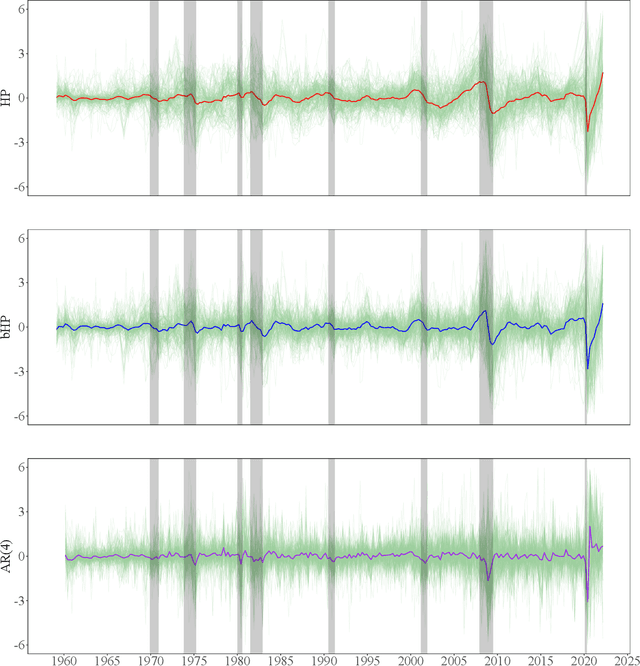
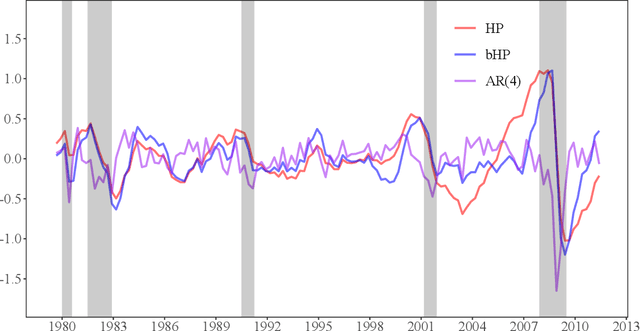
The global financial crisis and Covid recession have renewed discussion concerning trend-cycle discovery in macroeconomic data, and boosting has recently upgraded the popular HP filter to a modern machine learning device suited to data-rich and rapid computational environments. This paper sheds light on its versatility in trend-cycle determination, explaining in a simple manner both HP filter smoothing and the consistency delivered by boosting for general trend detection. Applied to a universe of time series in FRED databases, boosting outperforms other methods in timely capturing downturns at crises and recoveries that follow. With its wide applicability the boosted HP filter is a useful automated machine learning addition to the macroeconometric toolkit.
Boosting the Hodrick-Prescott Filter
May 01, 2019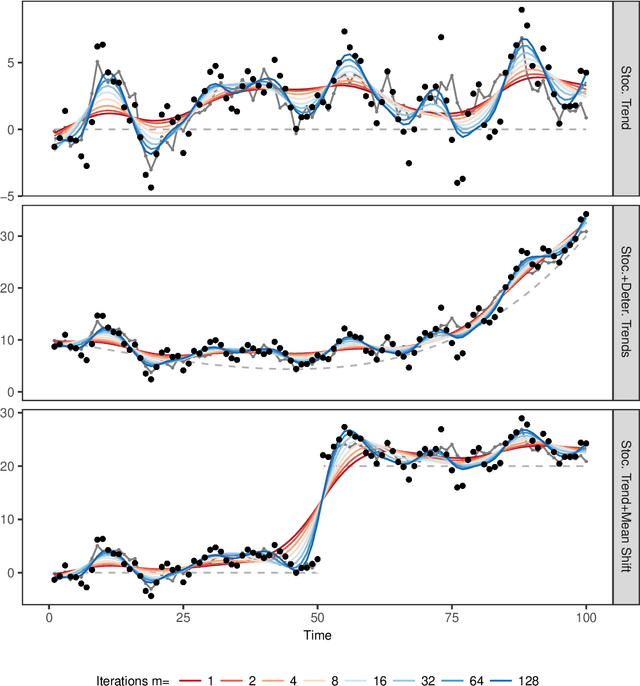
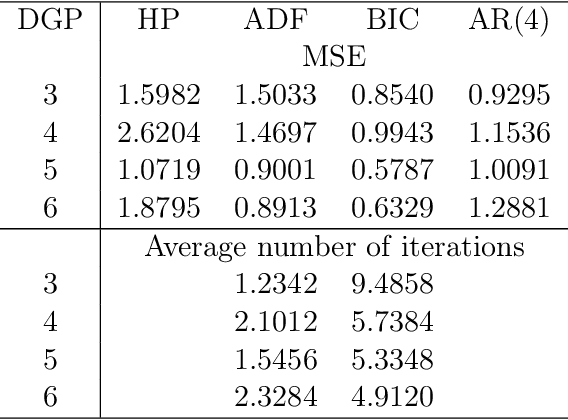
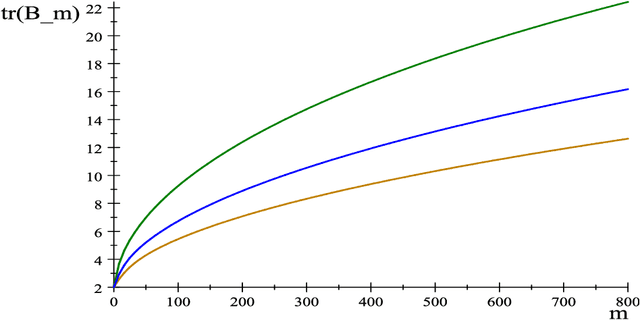
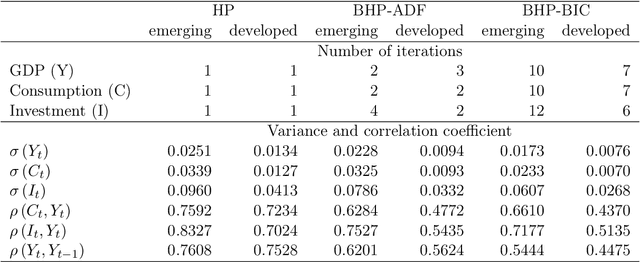
The Hodrick-Prescott (HP) filter is one of the most widely used econometric methods in applied macroeconomic research. The technique is nonparametric and seeks to decompose a time series into a trend and a cyclical component unaided by economic theory or prior trend specification. Like all nonparametric methods, the HP filter depends critically on a tuning parameter that controls the degree of smoothing. Yet in contrast to modern nonparametric methods and applied work with these procedures, empirical practice with the HP filter almost universally relies on standard settings for the tuning parameter that have been suggested largely by experimentation with macroeconomic data and heuristic reasoning about the form of economic cycles and trends. As recent research has shown, standard settings may not be adequate in removing trends, particularly stochastic trends, in economic data. This paper proposes an easy-to-implement practical procedure of iterating the HP smoother that is intended to make the filter a smarter smoothing device for trend estimation and trend elimination. We call this iterated HP technique the boosted HP filter in view of its connection to L2-boosting in machine learning. The paper develops limit theory to show that the boosted HP filter asymptotically recovers trend mechanisms that involve unit root processes, deterministic polynomial drifts, and polynomial drifts with structural breaks -- the most common trends that appear in macroeconomic data and current modeling methodology. A stopping criterion is used to automate the iterative HP algorithm, making it a data-determined method that is ready for modern data-rich environments in economic research. The methodology is illustrated using three real data examples that highlight the differences between simple HP filtering, the data-determined boosted filter, and an alternative autoregressive approach.