 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective Synthesis of Indoor 3D Scenes
Paper and Code
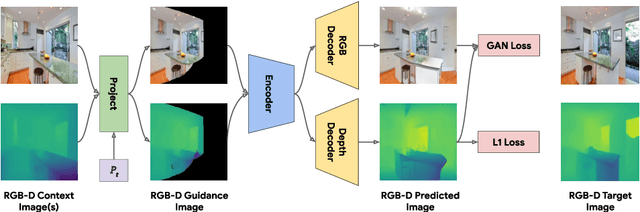
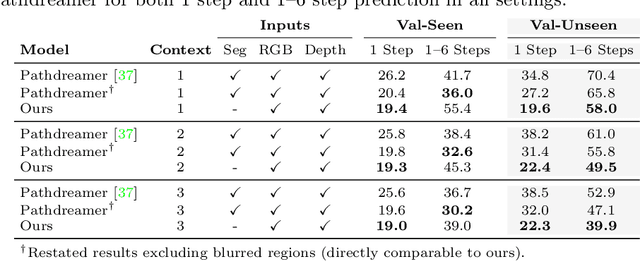


We study the problem of synthesizing immersive 3D indoor scenes from one or more images. Our aim is to generate high-resolution images and videos from novel viewpoints, including viewpoints that extrapolate far beyond the input images while maintaining 3D consistency. Existing approaches are highly complex, with many separately trained stages and components. We propose a simple alternative: an image-to-image GAN that maps directly from reprojections of incomplete point clouds to full high-resolution RGB-D images. On the Matterport3D and RealEstate10K datasets, our approach significantly outperforms prior work when evaluated by humans, as well as on FID scores. Further, we show that our model is useful for generative data augmentation. A vision-and-language navigation (VLN) agent trained with trajectories spatially-perturbed by our model improves success rate by up to 1.5% over a state of the art baseline on the R2R benchmark. Our code will be made available to facilitate generative data augmentation and applications to downstream robotics and embodied AI tasks.