 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-CLFusion: Fast Text-to-3D Rendering with Contrastive Latent Diffusion
Paper and Code
Mar 21, 2023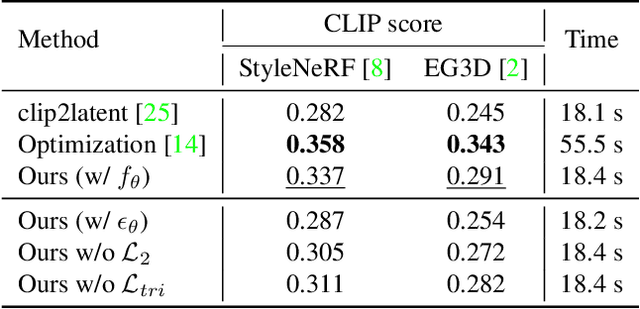



We tackle the task of text-to-3D creation with pre-trained latent-based NeRFs (NeRFs that generate 3D objects given input latent code). Recent works such as DreamFusion and Magic3D have shown great success in generating 3D content using NeRFs and text prompts, but the current approach of optimizing a NeRF for every text prompt is 1) extremely time-consuming and 2) often leads to low-resolution outputs. To address these challenges, we propose a novel method named 3D-CLFusion which leverages the pre-trained latent-based NeRFs and performs fast 3D content creation in less than a minute. In particular, we introduce a latent diffusion prior network for learning the w latent from the input CLIP text/image embeddings. This pipeline allows us to produce the w latent without further optimization during inference and the pre-trained NeRF is able to perform multi-view high-resolution 3D synthesis based on the latent. We note that the novelty of our model lies in that we introduce contrastive learning during training the diffusion prior which enables the generation of the valid view-invariant latent code. We demonstrate through experiments the effectiveness of our proposed view-invariant diffusion process for fast text-to-3D creation, e.g., 100 times faster than DreamFusion. We note that our model is able to serve as the role of a plug-and-play tool for text-to-3D with pre-trained NeRFs.