 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-RDW: Redirected Walking with Forecasting Future Position
Apr 07, 2023In order to serve better VR experiences to users, existing predictive methods of Redirected Walking (RDW) exploit future information to reduce the number of reset occurrences. However, such methods often impose a precondition during deployment, either in the virtual environment's layout or the user's walking direction, which constrains its universal applications. To tackle this challenge, we propose a novel mechanism F-RDW that is twofold: (1) forecasts the future information of a user in the virtual space without any assumptions, and (2) fuse this information while maneuvering existing RDW methods. The backbone of the first step is an LSTM-based model that ingests the user's spatial and eye-tracking data to predict the user's future position in the virtual space, and the following step feeds those predicted values into existing RDW methods (such as MPCRed, S2C, TAPF, and ARC) while respecting their internal mechanism in applicable ways.The results of our simulation test and user study demonstrate the significance of future information when using RDW in small physical spaces or complex environments. We prove that the proposed mechanism significantly reduces the number of resets and increases the traveled distance between resets, hence augmenting the redirection performance of all RDW methods explored in this work.
Deep learning for determining a near-optimal topological design without any iteration
Sep 22, 2018
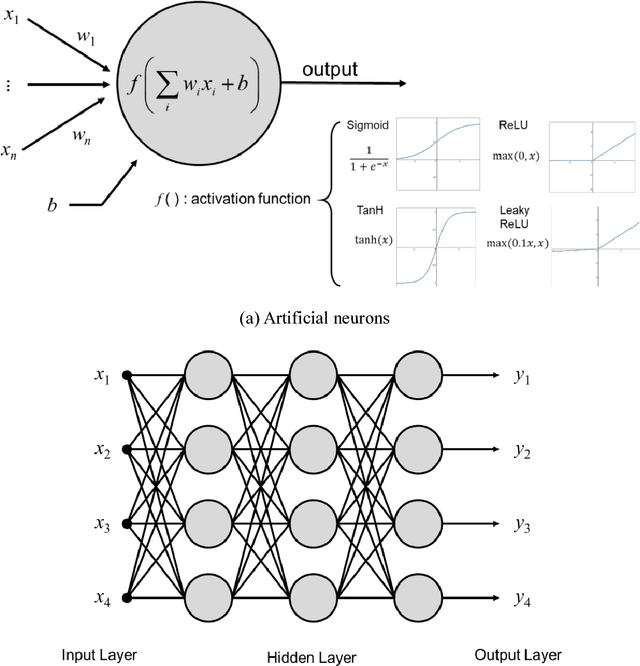
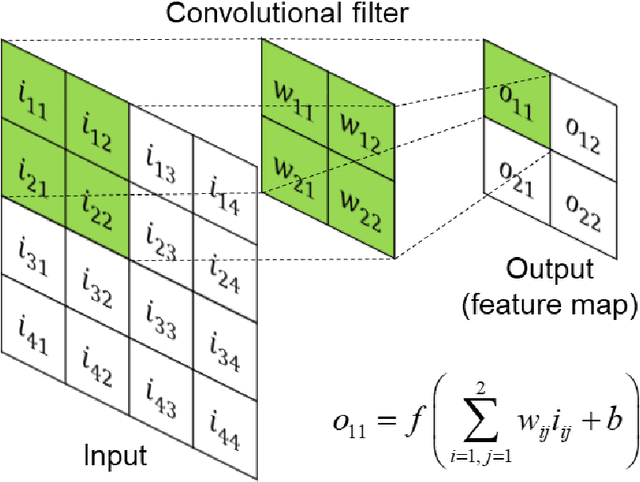
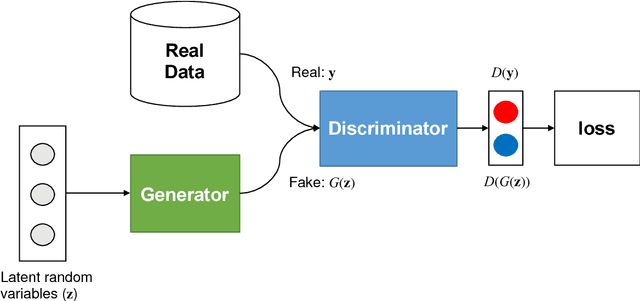
In this study, we propose a novel deep learning-based method to predict an optimized structure for a given boundary condition and optimization setting without using any iterative scheme. For this purpose, first, using open-source topology optimization code, datasets of the optimized structures paired with the corresponding information on boundary conditions and optimization settings are generated at low (32 x 32) and high (128 x 128) resolutions. To construct the artificial neural network for the proposed method, a convolutional neural network (CNN)-based encoder and decoder network is trained using the training dataset generated at low resolution. Then, as a two-stage refinement, the conditional generative adversarial network (cGAN) is trained with the optimized structures paired at both low and high resolutions, and is connected to the trained CNN-based encoder and decoder network. The performance evaluation results of the integrated network demonstrate that the proposed method can determine a near-optimal structure in terms of pixel values and compliance with negligible computational time.