 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Privacy Personas
Oct 17, 2024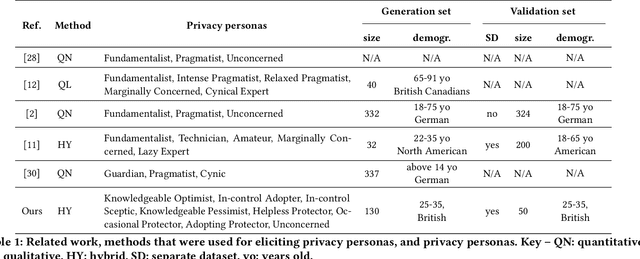



Privacy personas capture the differences in user segments with respect to one's knowledge, behavioural patterns, level of self-efficacy, and perception of the importance of privacy protection. Modelling these differences is essential for appropriately choosing personalised communication about privacy (e.g. to increase literacy) and for defining suitable choices for privacy enhancing technologies (PETs). While various privacy personas have been derived in the literature, they group together people who differ from each other in terms of important attributes such as perceived or desired level of control, and motivation to use PET. To address this lack of granularity and comprehensiveness in describing personas, we propose eight personas that we derive by combining qualitative and quantitative analysis of the responses to an interactive educational questionnaire. We design an analysis pipeline that uses divisive hierarchical clustering and Boschloo's statistical test of homogeneity of proportions to ensure that the elicited clusters differ from each other based on a statistical measure. Additionally, we propose a new measure for calculating distances between questionnaire responses, that accounts for the type of the question (closed- vs open-ended) used to derive traits. We show that the proposed privacy personas statistically differ from each other. We statistically validate the proposed personas and also compare them with personas in the literature, showing that they provide a more granular and comprehensive understanding of user segments, which will allow to better assist users with their privacy needs.