 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution Shift in Airline Customer Behavior during COVID-19
Dec 23, 2021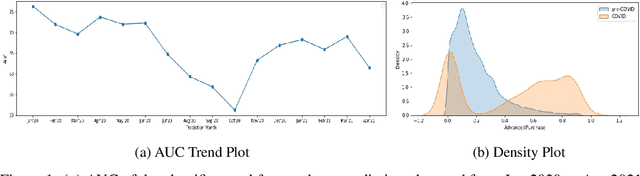

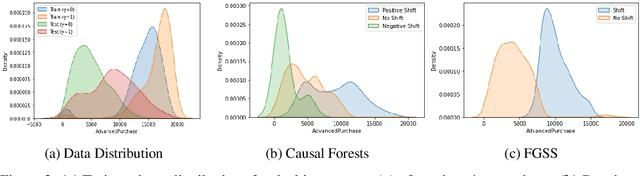
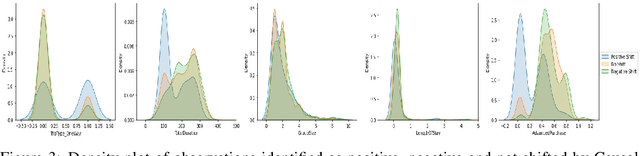
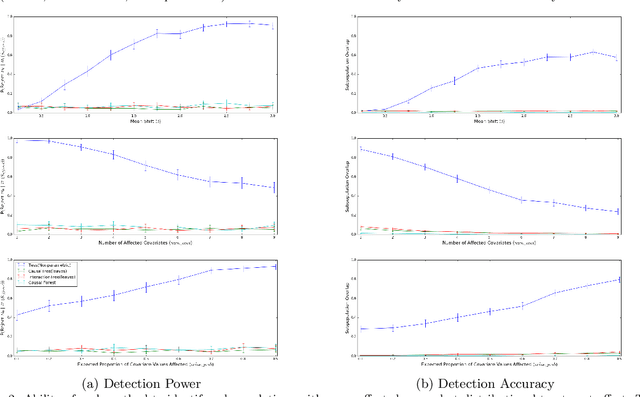
Traditional AI approaches in customized (personalized) contextual pricing applications assume that the data distribution at the time of online pricing is similar to that observed during training. However, this assumption may be violated in practice because of the dynamic nature of customer buying patterns, particularly due to unanticipated system shocks such as COVID-19. We study the changes in customer behavior for a major airline during the COVID-19 pandemic by framing it as a covariate shift and concept drift detection problem. We identify which customers changed their travel and purchase behavior and the attributes affecting that change using (i) Fast Generalized Subset Scanning and (ii) Causal Forests. In our experiments with simulated and real-world data, we present how these two techniques can be used through qualitative analysis.
Efficient Discovery of Heterogeneous Treatment Effects in Randomized Experiments via Anomalous Pattern Detection
Jun 07, 2018
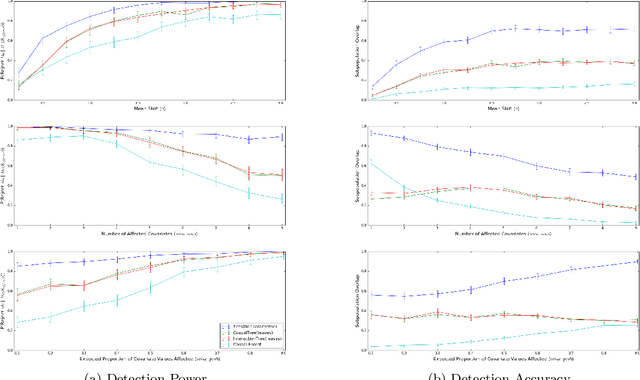

In the recent literature on estimating heterogeneous treatment effects, each proposed method makes its own set of restrictive assumptions about the intervention's effects and which subpopulations to explicitly estimate. Moreover, the majority of the literature provides no mechanism to identify which subpopulations are the most affected--beyond manual inspection--and provides little guarantee on the correctness of the identified subpopulations. Therefore, we propose Treatment Effect Subset Scan (TESS), a new method for discovering which subpopulation in a randomized experiment is most significantly affected by a treatment. We frame this challenge as a pattern detection problem where we efficiently maximize a nonparametric scan statistic over subpopulations. Furthermore, we identify the subpopulation which experiences the largest distributional change as a result of the intervention, while making minimal assumptions about the intervention's effects or the underlying data generating process. In addition to the algorithm, we demonstrate that the asymptotic Type I and II error can be controlled, and provide sufficient conditions for detection consistency--i.e., exact identification of the affected subpopulation. Finally, we validate the efficacy of the method by discovering heterogeneous treatment effects in simulations and in real-world data from a well-known program evaluation study.
Graph Structure Learning from Unlabeled Data for Event Detection
Jan 05, 2017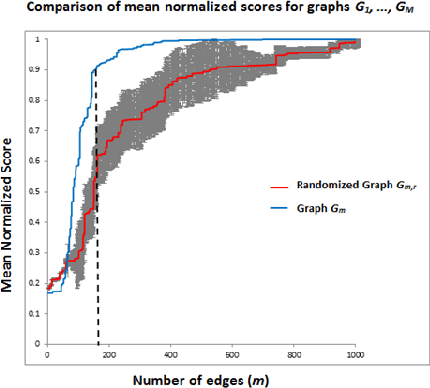
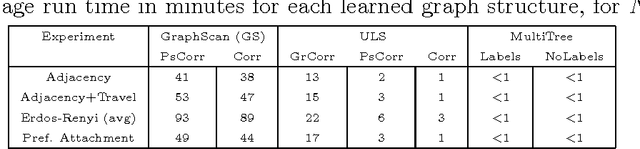
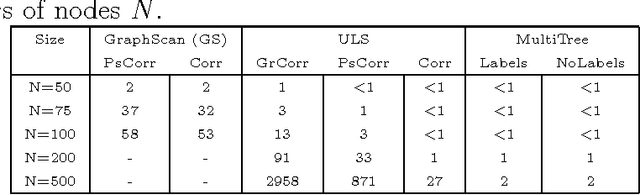
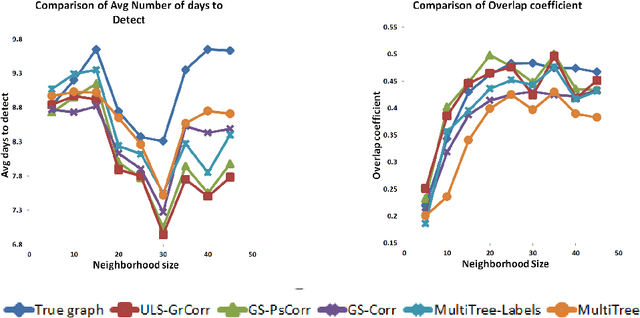
Processes such as disease propagation and information diffusion often spread over some latent network structure which must be learned from observation. Given a set of unlabeled training examples representing occurrences of an event type of interest (e.g., a disease outbreak), our goal is to learn a graph structure that can be used to accurately detect future events of that type. Motivated by new theoretical results on the consistency of constrained and unconstrained subset scans, we propose a novel framework for learning graph structure from unlabeled data by comparing the most anomalous subsets detected with and without the graph constraints. Our framework uses the mean normalized log-likelihood ratio score to measure the quality of a graph structure, and efficiently searches for the highest-scoring graph structure. Using simulated disease outbreaks injected into real-world Emergency Department data from Allegheny County, we show that our method learns a structure similar to the true underlying graph, but enables faster and more accurate detection.