 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Structure Learning from Unlabeled Data for Event Detection
Paper and Code
Jan 05, 2017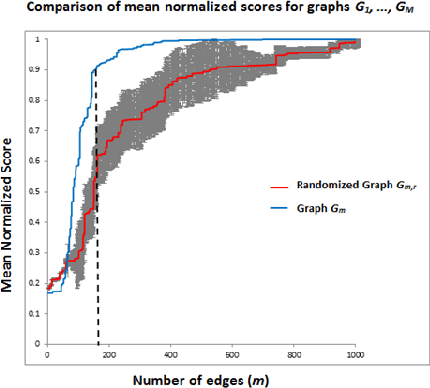
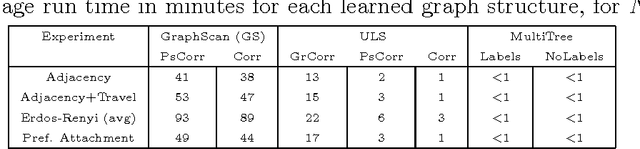
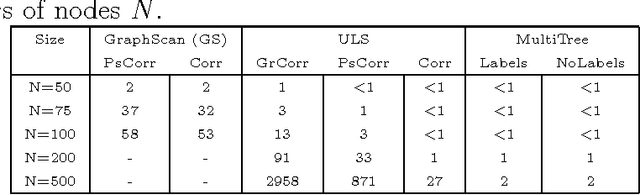
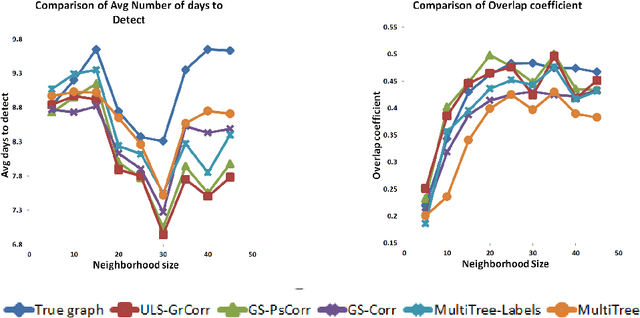
Processes such as disease propagation and information diffusion often spread over some latent network structure which must be learned from observation. Given a set of unlabeled training examples representing occurrences of an event type of interest (e.g., a disease outbreak), our goal is to learn a graph structure that can be used to accurately detect future events of that type. Motivated by new theoretical results on the consistency of constrained and unconstrained subset scans, we propose a novel framework for learning graph structure from unlabeled data by comparing the most anomalous subsets detected with and without the graph constraints. Our framework uses the mean normalized log-likelihood ratio score to measure the quality of a graph structure, and efficiently searches for the highest-scoring graph structure. Using simulated disease outbreaks injected into real-world Emergency Department data from Allegheny County, we show that our method learns a structure similar to the true underlying graph, but enables faster and more accurate detection.