Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecutive Function: A Contrastive Value Policy for Resampling and Relabeling Perceptions via Hindsight Summarization?
Paper and Code
Apr 27, 2022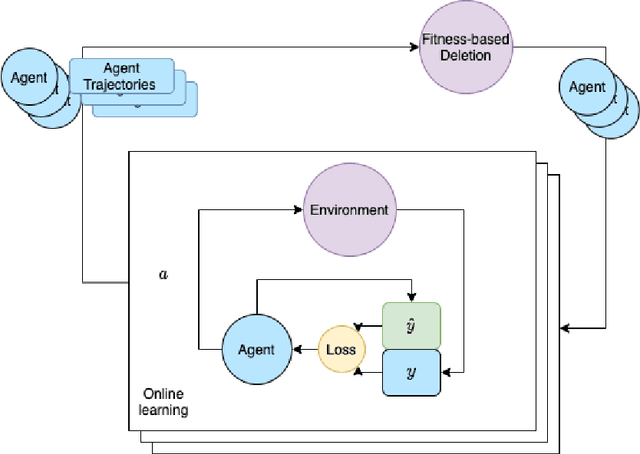
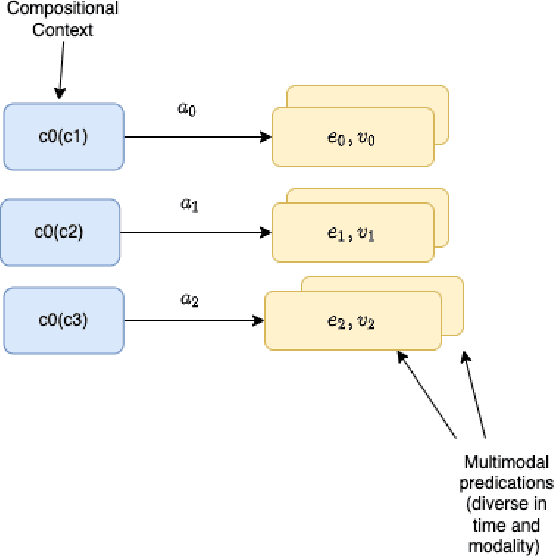
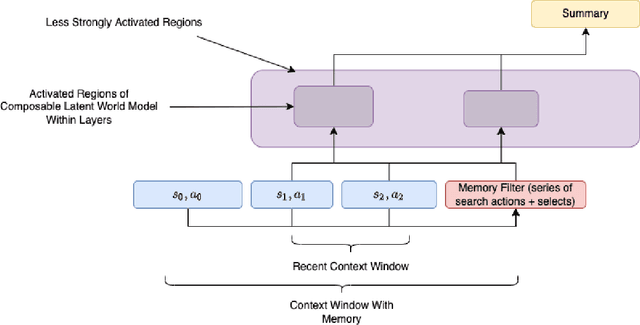
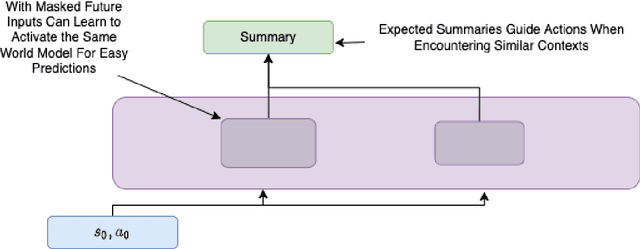
We develop the few-shot continual learning task from first principles and hypothesize an evolutionary motivation and mechanism of action for executive function as a contrastive value policy which resamples and relabels perception data via hindsight summarization to minimize attended prediction error, similar to an online prompt engineering problem. This is made feasible by the use of a memory policy and a pretrained network with inductive biases for a grammar of learning and is trained to maximize evolutionary survival. We show how this model of executive function can be used to implement hypothesis testing as a stream of consciousness and may explain observations of human few-shot learning and neuroanatomy.
* The authors also thank MeiMei the golden retriever for insightful
collaboration, in particular, sampling contrastive data on human vs. dog
hindsight summarization
View paper on