 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARFISH: faST Accuracy Recovery in pruned networks From Internal State Healing
May 31, 2026Pruning is a process designed to reduce the number of weights in a large neural network. This can substantially speed up inference but might cause a considerable reduction in the model's accuracy, and thus it is usually followed by a healing process that regains some of the lost accuracy. In this paper, we propose a new healing method, STARFISH, that can recover (most of) the accuracy of any pruned network efficiently. The main idea of STARFISH is to optimize the pruned network to align with the original network's internal state representations using a tiny calibration set of unlabeled examples. For the common case of removing 50% of the weights, STARFISH healing improves the recovered accuracy by up to 22% over the state-of-the-art methods on ViT-based networks. Its advantage is even more pronounced under aggressive pruning. For example, after eliminating 75% of the weights in a DeiT-B network for ImageNet, STARFISH uses only 0.4% of the number of training images as a calibration set and recovers 82% of the original dense accuracy, whereas competing recovery techniques reach only 40% of the dense model accuracy.
A Provable Energy-Guided Test-Time Defense Boosting Adversarial Robustness of Large Vision-Language Models
Mar 31, 2026Despite the rapid progress in multimodal models and Large Visual-Language Models (LVLM), they remain highly susceptible to adversarial perturbations, raising serious concerns about their reliability in real-world use. While adversarial training has become the leading paradigm for building models that are robust to adversarial attacks, Test-Time Transformations (TTT) have emerged as a promising strategy to boost robustness at inference. In light of this, we propose Energy-Guided Test-Time Transformation (ET3), a lightweight, training-free defense that enhances the robustness by minimizing the energy of the input samples. Our method is grounded in a theory that proves our transformation succeeds in classification under reasonable assumptions. We present extensive experiments demonstrating that ET3 provides a strong defense for classifiers, zero-shot classification with CLIP, and also for boosting the robustness of LVLMs in tasks such as Image Captioning and Visual Question Answering. Code is available at github.com/OmnAI-Lab/Energy-Guided-Test-Time-Defense .
MALT Powers Up Adversarial Attacks
Jul 02, 2024

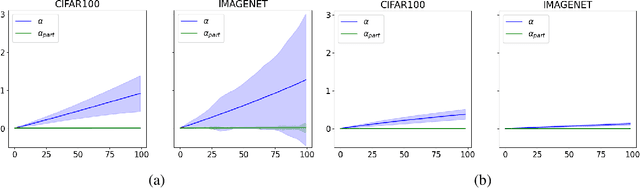
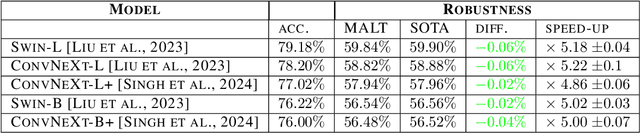
Current adversarial attacks for multi-class classifiers choose the target class for a given input naively, based on the classifier's confidence levels for various target classes. We present a novel adversarial targeting method, \textit{MALT - Mesoscopic Almost Linearity Targeting}, based on medium-scale almost linearity assumptions. Our attack wins over the current state of the art AutoAttack on the standard benchmark datasets CIFAR-100 and ImageNet and for a variety of robust models. In particular, our attack is \emph{five times faster} than AutoAttack, while successfully matching all of AutoAttack's successes and attacking additional samples that were previously out of reach. We then prove formally and demonstrate empirically that our targeting method, although inspired by linear predictors, also applies to standard non-linear models.
Explaining high-dimensional text classifiers
Nov 22, 2023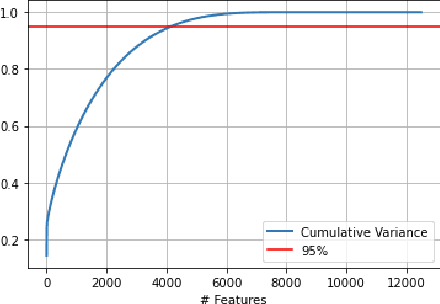

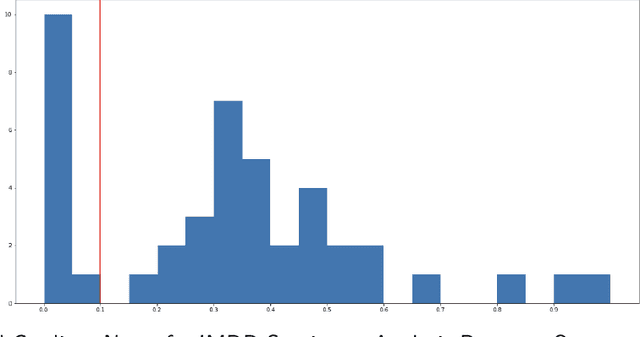

Explainability has become a valuable tool in the last few years, helping humans better understand AI-guided decisions. However, the classic explainability tools are sometimes quite limited when considering high-dimensional inputs and neural network classifiers. We present a new explainability method using theoretically proven high-dimensional properties in neural network classifiers. We present two usages of it: 1) On the classical sentiment analysis task for the IMDB reviews dataset, and 2) our Malware-Detection task for our PowerShell scripts dataset.
Adversarial Examples Exist in Two-Layer ReLU Networks for Low Dimensional Data Manifolds
Mar 01, 2023



Despite a great deal of research, it is still not well-understood why trained neural networks are highly vulnerable to adversarial examples. In this work we focus on two-layer neural networks trained using data which lie on a low dimensional linear subspace. We show that standard gradient methods lead to non-robust neural networks, namely, networks which have large gradients in directions orthogonal to the data subspace, and are susceptible to small adversarial $L_2$-perturbations in these directions. Moreover, we show that decreasing the initialization scale of the training algorithm, or adding $L_2$ regularization, can make the trained network more robust to adversarial perturbations orthogonal to the data.
The Dimpled Manifold Model of Adversarial Examples in Machine Learning
Jun 18, 2021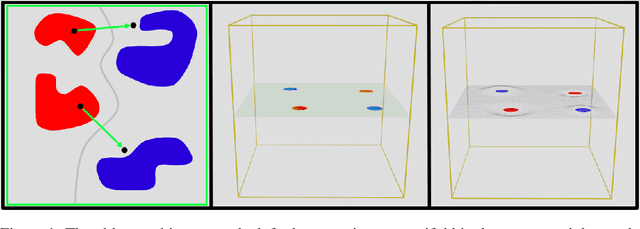

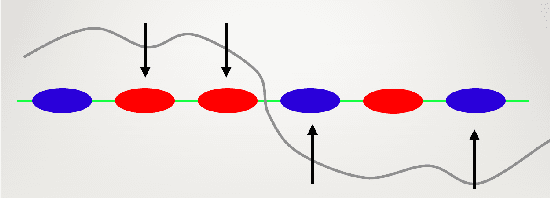
The extreme fragility of deep neural networks when presented with tiny perturbations in their inputs was independently discovered by several research groups in 2013, but in spite of enormous effort these adversarial examples remained a baffling phenomenon with no clear explanation. In this paper we introduce a new conceptual framework (which we call the Dimpled Manifold Model) which provides a simple explanation for why adversarial examples exist, why their perturbations have such tiny norms, why these perturbations look like random noise, and why a network which was adversarially trained with incorrectly labeled images can still correctly classify test images. In the last part of the paper we describe the results of numerous experiments which strongly support this new model, and in particular our assertion that adversarial perturbations are roughly perpendicular to the low dimensional manifold which contains all the training examples.