 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedundancy in Deep Linear Neural Networks
Jun 09, 2022



Conventional wisdom states that deep linear neural networks benefit from expressiveness and optimization advantages over a single linear layer. This paper suggests that, in practice, the training process of deep linear fully-connected networks using conventional optimizers is convex in the same manner as a single linear fully-connected layer. This paper aims to explain this claim and demonstrate it. Even though convolutional networks are not aligned with this description, this work aims to attain a new conceptual understanding of fully-connected linear networks that might shed light on the possible constraints of convolutional settings and non-linear architectures.
Early Transferability of Adversarial Examples in Deep Neural Networks
Jun 09, 2022



This paper will describe and analyze a new phenomenon that was not known before, which we call "Early Transferability". Its essence is that the adversarial perturbations transfer among different networks even at extremely early stages in their training. In fact, one can initialize two networks with two different independent choices of random weights and measure the angle between their adversarial perturbations after each step of the training. What we discovered was that these two adversarial directions started to align with each other already after the first few training steps (which typically use only a small fraction of the available training data), even though the accuracy of the two networks hadn't started to improve from their initial bad values due to the early stage of the training. The purpose of this paper is to present this phenomenon experimentally and propose plausible explanations for some of its properties.
Meet You Halfway: Explaining Deep Learning Mysteries
Jun 09, 2022



Deep neural networks perform exceptionally well on various learning tasks with state-of-the-art results. While these models are highly expressive and achieve impressively accurate solutions with excellent generalization abilities, they are susceptible to minor perturbations. Samples that suffer such perturbations are known as "adversarial examples". Even though deep learning is an extensively researched field, many questions about the nature of deep learning models remain unanswered. In this paper, we introduce a new conceptual framework attached with a formal description that aims to shed light on the network's behavior and interpret the behind-the-scenes of the learning process. Our framework provides an explanation for inherent questions concerning deep learning. Particularly, we clarify: (1) Why do neural networks acquire generalization abilities? (2) Why do adversarial examples transfer between different models?. We provide a comprehensive set of experiments that support this new framework, as well as its underlying theory.
The Dimpled Manifold Model of Adversarial Examples in Machine Learning
Jun 18, 2021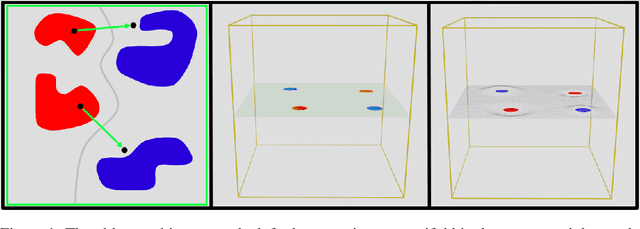

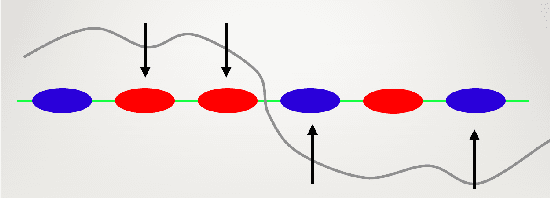
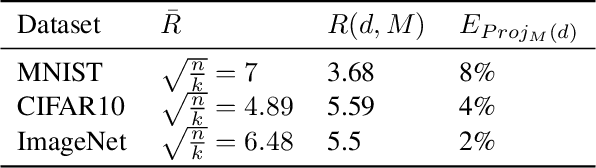
The extreme fragility of deep neural networks when presented with tiny perturbations in their inputs was independently discovered by several research groups in 2013, but in spite of enormous effort these adversarial examples remained a baffling phenomenon with no clear explanation. In this paper we introduce a new conceptual framework (which we call the Dimpled Manifold Model) which provides a simple explanation for why adversarial examples exist, why their perturbations have such tiny norms, why these perturbations look like random noise, and why a network which was adversarially trained with incorrectly labeled images can still correctly classify test images. In the last part of the paper we describe the results of numerous experiments which strongly support this new model, and in particular our assertion that adversarial perturbations are roughly perpendicular to the low dimensional manifold which contains all the training examples.