 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dimpled Manifold Model of Adversarial Examples in Machine Learning
Paper and Code
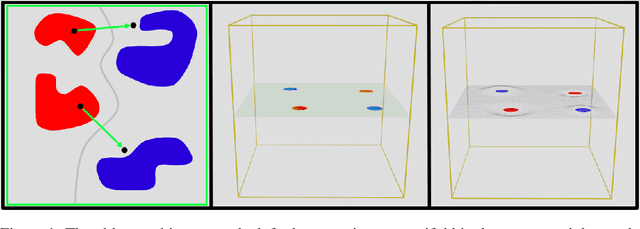

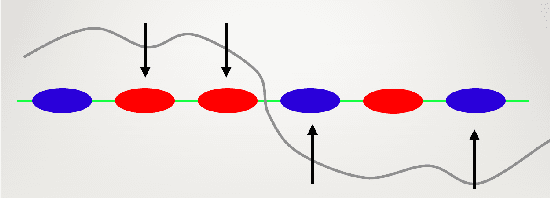
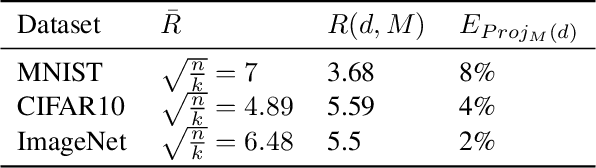
The extreme fragility of deep neural networks when presented with tiny perturbations in their inputs was independently discovered by several research groups in 2013, but in spite of enormous effort these adversarial examples remained a baffling phenomenon with no clear explanation. In this paper we introduce a new conceptual framework (which we call the Dimpled Manifold Model) which provides a simple explanation for why adversarial examples exist, why their perturbations have such tiny norms, why these perturbations look like random noise, and why a network which was adversarially trained with incorrectly labeled images can still correctly classify test images. In the last part of the paper we describe the results of numerous experiments which strongly support this new model, and in particular our assertion that adversarial perturbations are roughly perpendicular to the low dimensional manifold which contains all the training examples.