 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Dynamic Order Picking in Warehouse Operations
Aug 03, 2024



Order picking is a crucial operation in warehouses that significantly impacts overall efficiency and profitability. This study addresses the dynamic order picking problem, a significant concern in modern warehouse management where real-time adaptation to fluctuating order arrivals and efficient picker routing are crucial. Traditional methods, often assuming fixed order sets, fall short in this dynamic environment. We utilize Deep Reinforcement Learning (DRL) as a solution methodology to handle the inherent uncertainties in customer demands. We focus on a single-block warehouse with an autonomous picking device, eliminating human behavioral factors. Our DRL framework enables the dynamic optimization of picker routes, significantly reducing order throughput times, especially under high order arrival rates. Experiments demonstrate a substantial decrease in order throughput time and unfulfilled orders compared to benchmark algorithms. We further investigate integrating a hyperparameter in the reward function that allows for flexible balancing between distance traveled and order completion time. Finally, we demonstrate the robustness of our DRL model for out-of-sample test instances.
Deep Reinforcement Learning for Picker Routing Problem in Warehousing
Feb 05, 2024Order Picker Routing is a critical issue in Warehouse Operations Management. Due to the complexity of the problem and the need for quick solutions, suboptimal algorithms are frequently employed in practice. However, Reinforcement Learning offers an appealing alternative to traditional heuristics, potentially outperforming existing methods in terms of speed and accuracy. We introduce an attention based neural network for modeling picker tours, which is trained using Reinforcement Learning. Our method is evaluated against existing heuristics across a range of problem parameters to demonstrate its efficacy. A key advantage of our proposed method is its ability to offer an option to reduce the perceived complexity of routes.
SALSA: Sequential Approximate Leverage-Score Algorithm with Application in Analyzing Big Time Series Data
Dec 30, 2023We develop a new efficient sequential approximate leverage score algorithm, SALSA, using methods from randomized numerical linear algebra (RandNLA) for large matrices. We demonstrate that, with high probability, the accuracy of SALSA's approximations is within $(1 + O({\varepsilon}))$ of the true leverage scores. In addition, we show that the theoretical computational complexity and numerical accuracy of SALSA surpass existing approximations. These theoretical results are subsequently utilized to develop an efficient algorithm, named LSARMA, for fitting an appropriate ARMA model to large-scale time series data. Our proposed algorithm is, with high probability, guaranteed to find the maximum likelihood estimates of the parameters for the true underlying ARMA model. Furthermore, it has a worst-case running time that significantly improves those of the state-of-the-art alternatives in big data regimes. Empirical results on large-scale data strongly support these theoretical results and underscore the efficacy of our new approach.
A Hybrid Statistical-Machine Learning Approach for Analysing Online Customer Behavior: An Empirical Study
Dec 01, 2022
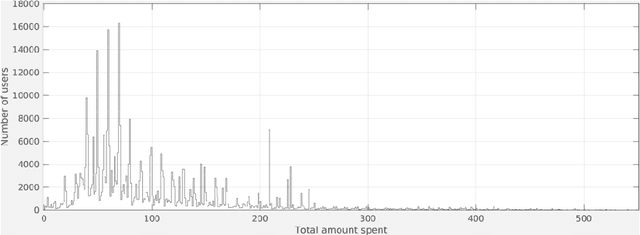


We apply classical statistical methods in conjunction with the state-of-the-art machine learning techniques to develop a hybrid interpretable model to analyse 454,897 online customers' behavior for a particular product category at the largest online retailer in China, that is JD. While most mere machine learning methods are plagued by the lack of interpretability in practice, our novel hybrid approach will address this practical issue by generating explainable output. This analysis involves identifying what features and characteristics have the most significant impact on customers' purchase behavior, thereby enabling us to predict future sales with a high level of accuracy, and identify the most impactful variables. Our results reveal that customers' product choice is insensitive to the promised delivery time, but this factor significantly impacts customers' order quantity. We also show that the effectiveness of various discounting methods depends on the specific product and the discount size. We identify product classes for which certain discounting approaches are more effective and provide recommendations on better use of different discounting tools. Customers' choice behavior across different product classes is mostly driven by price, and to a lesser extent, by customer demographics. The former finding asks for exercising care in deciding when and how much discount should be offered, whereas the latter identifies opportunities for personalized ads and targeted marketing. Further, to curb customers' batch ordering behavior and avoid the undesirable Bullwhip effect, JD should improve its logistics to ensure faster delivery of orders.
Toeplitz Least Squares Problems, Fast Algorithms and Big Data
Dec 24, 2021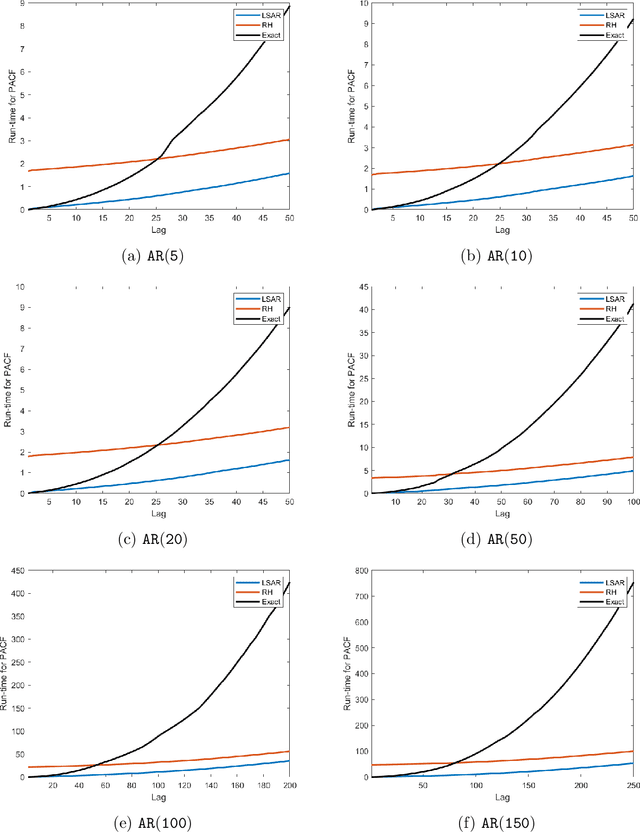
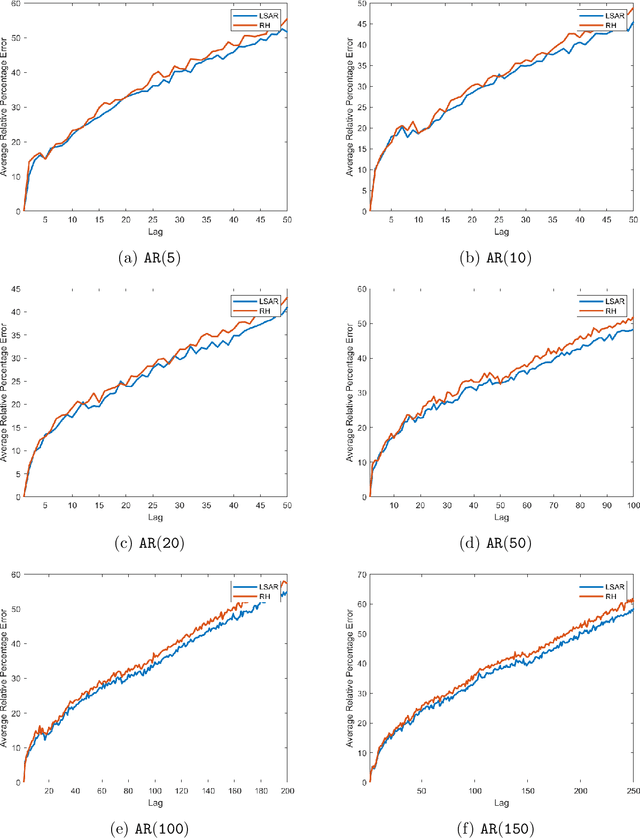
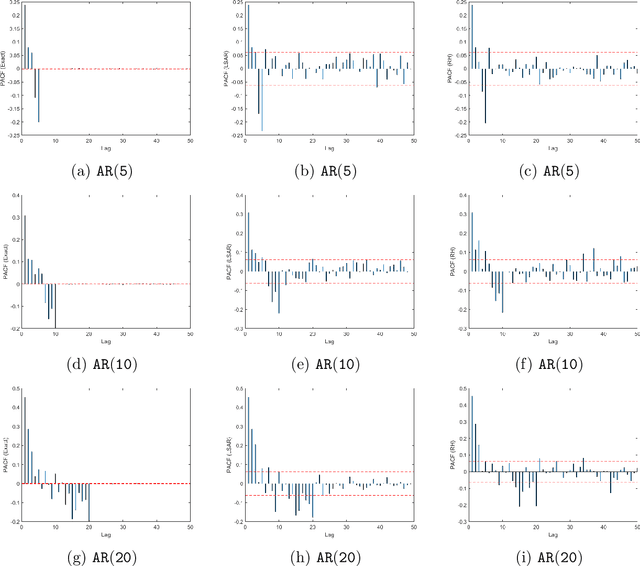
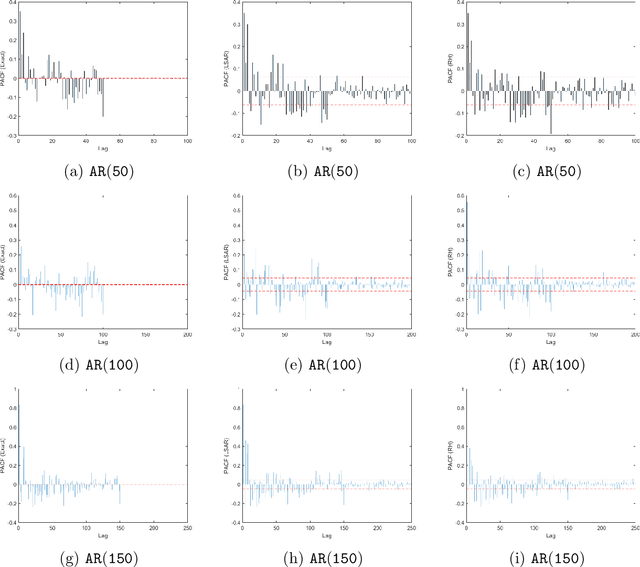
In time series analysis, when fitting an autoregressive model, one must solve a Toeplitz ordinary least squares problem numerous times to find an appropriate model, which can severely affect computational times with large data sets. Two recent algorithms (LSAR and Repeated Halving) have applied randomized numerical linear algebra (RandNLA) techniques to fitting an autoregressive model to big time-series data. We investigate and compare the quality of these two approximation algorithms on large-scale synthetic and real-world data. While both algorithms display comparable results for synthetic datasets, the LSAR algorithm appears to be more robust when applied to real-world time series data. We conclude that RandNLA is effective in the context of big-data time series.
Average-reward model-free reinforcement learning: a systematic review and literature mapping
Oct 18, 2020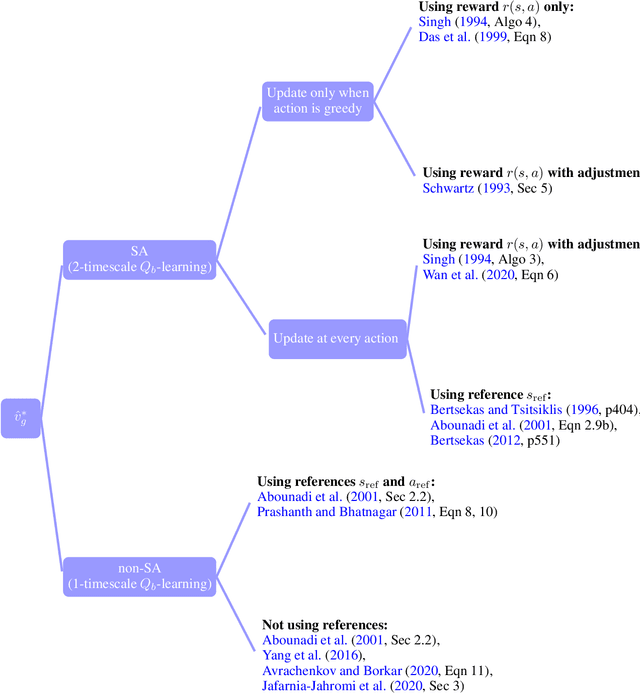

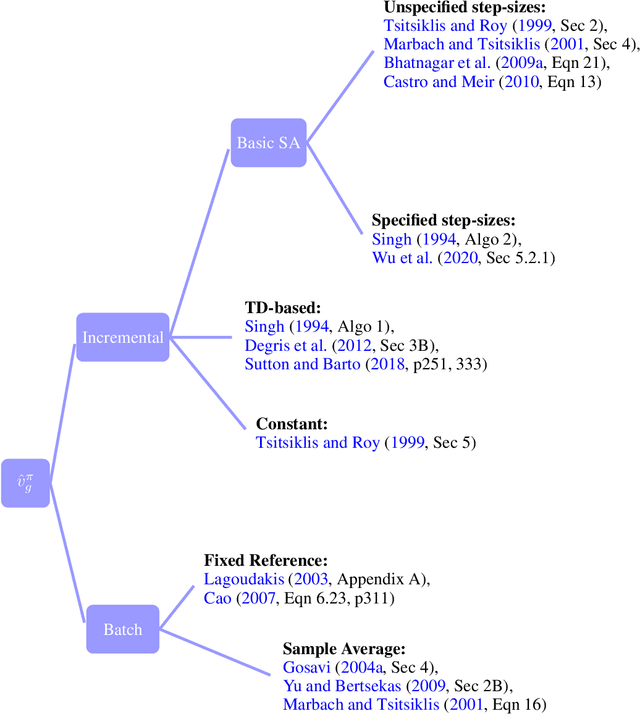
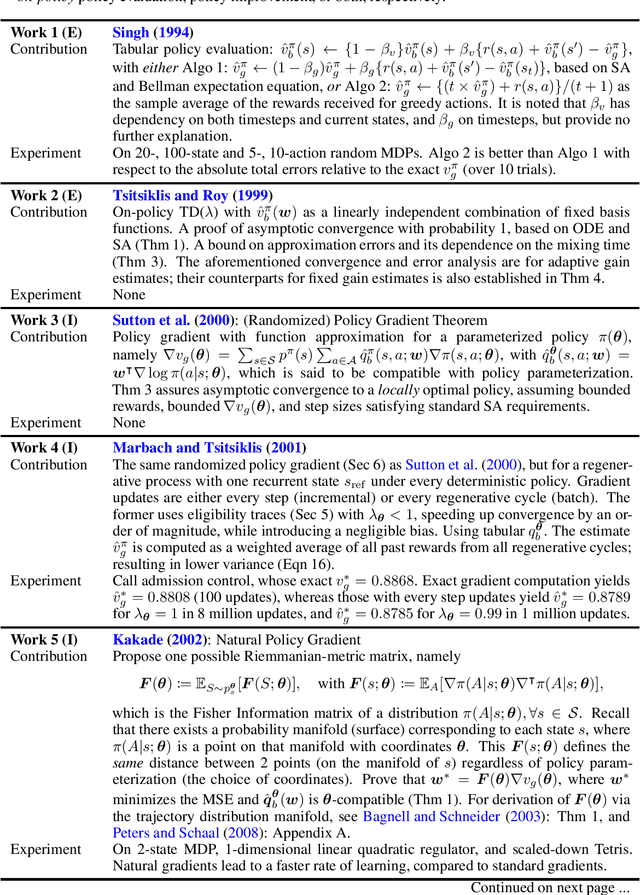
Model-free reinforcement learning (RL) has been an active area of research and provides a fundamental framework for agent-based learning and decision-making in artificial intelligence. In this paper, we review a specific subset of this literature, namely work that utilizes optimization criteria based on average rewards, in the infinite horizon setting. Average reward RL has the advantage of being the most selective criterion in recurrent (ergodic) Markov decision processes. In comparison to widely-used discounted reward criterion, it also requires no discount factor, which is a critical hyperparameter, and properly aligns the optimization and performance metrics. Motivated by the solo survey by Mahadevan (1996a), we provide an updated review of work in this area and extend it to cover policy-iteration and function approximation methods (in addition to the value-iteration and tabular counterparts). We also identify and discuss opportunities for future work.
LSAR: Efficient Leverage Score Sampling Algorithm for the Analysis of Big Time Series Data
Dec 26, 2019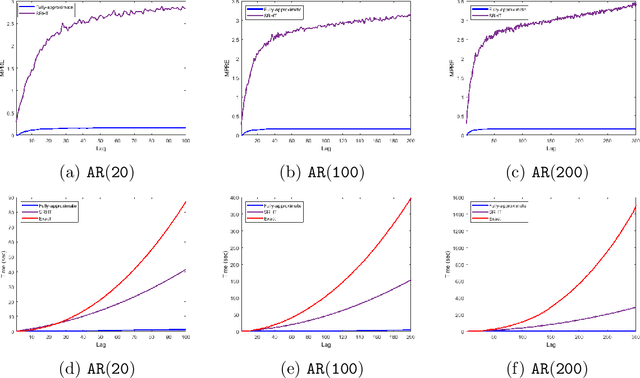
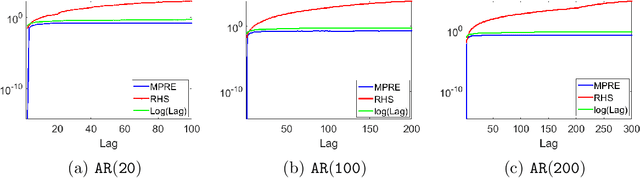
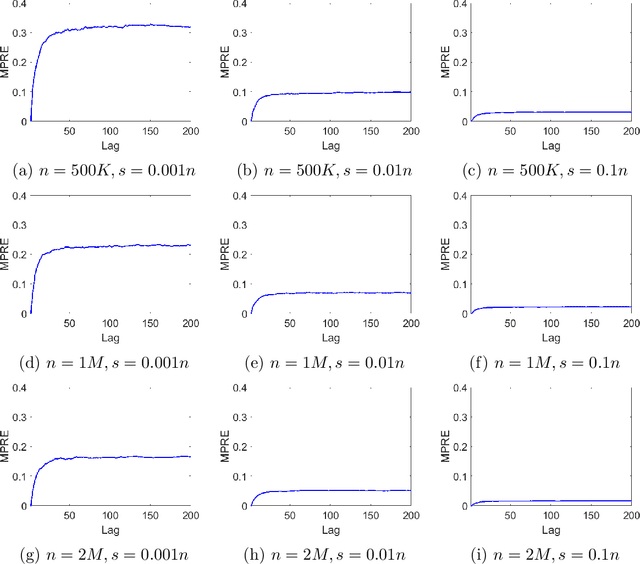
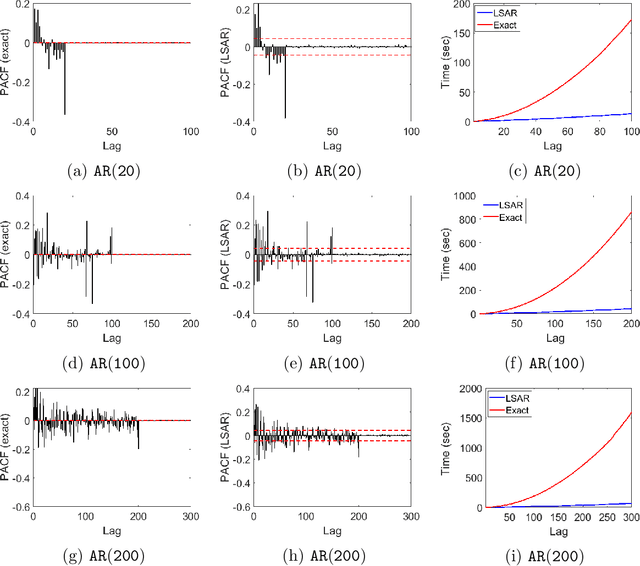
We apply methods from randomized numerical linear algebra (RandNLA) to develop improved algorithms for the analysis of large-scale time series data. We first develop a new fast algorithm to estimate the leverage scores of an autoregressive (AR) model in big data regimes. We show that the accuracy of approximations lies within $(1+\mathcal{O}(\varepsilon))$ of the true leverage scores with high probability. These theoretical results are subsequently exploited to develop an efficient algorithm, called LSAR, for fitting an appropriate AR model to big time series data. Our proposed algorithm is guaranteed, with high probability, to find the maximum likelihood estimates of the parameters of the underlying true AR model and has a worst case running time that significantly improves those of the state-of-the-art alternatives in big data regimes. Empirical results on large-scale synthetic as well as real data highly support the theoretical results and reveal the efficacy of this new approach.
Learning to Project in Multi-Objective Binary Linear Programming
Jan 30, 2019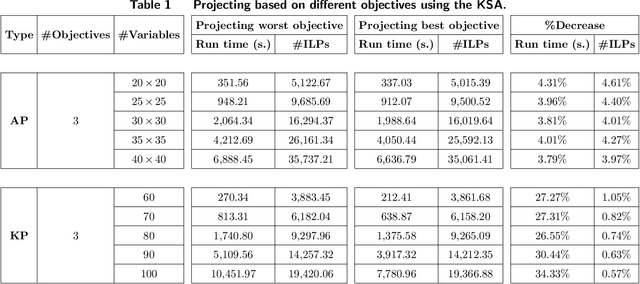
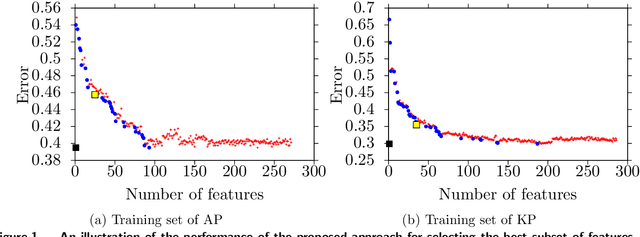
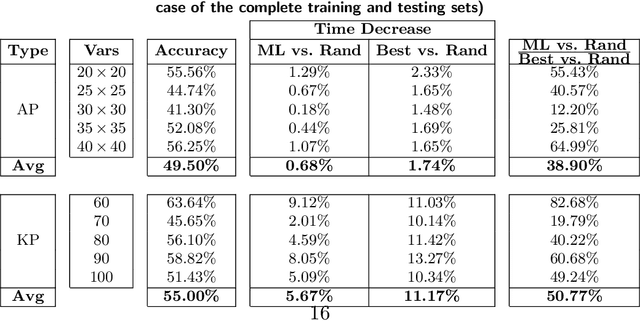
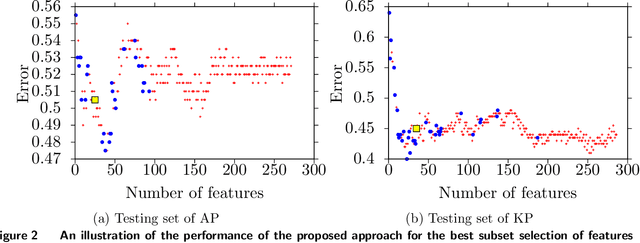
In this paper, we investigate the possibility of improving the performance of multi-objective optimization solution approaches using machine learning techniques. Specifically, we focus on multi-objective binary linear programs and employ one of the most effective and recently developed criterion space search algorithms, the so-called KSA, during our study. This algorithm computes all nondominated points of a problem with p objectives by searching on a projected criterion space, i.e., a (p-1)-dimensional criterion apace. We present an effective and fast learning approach to identify on which projected space the KSA should work. We also present several generic features/variables that can be used in machine learning techniques for identifying the best projected space. Finally, we present an effective bi-objective optimization based heuristic for selecting the best subset of the features to overcome the issue of overfitting in learning. Through an extensive computational study over 2000 instances of tri-objective Knapsack and Assignment problems, we demonstrate that an improvement of up to 12% in time can be achieved by the proposed learning method compared to a random selection of the projected space.