 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate discounting-free policy evaluation from transient and recurrent states
Apr 08, 2022

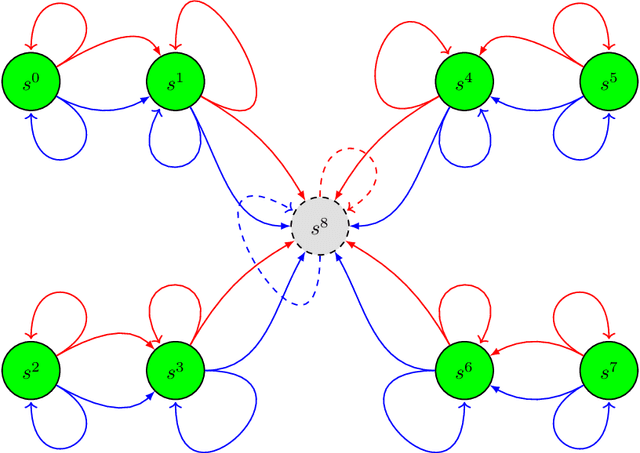

In order to distinguish policies that prescribe good from bad actions in transient states, we need to evaluate the so-called bias of a policy from transient states. However, we observe that most (if not all) works in approximate discounting-free policy evaluation thus far are developed for estimating the bias solely from recurrent states. We therefore propose a system of approximators for the bias (specifically, its relative value) from transient and recurrent states. Its key ingredient is a seminorm LSTD (least-squares temporal difference), for which we derive its minimizer expression that enables approximation by sampling required in model-free reinforcement learning. This seminorm LSTD also facilitates the formulation of a general unifying procedure for LSTD-based policy value approximators. Experimental results validate the effectiveness of our proposed method.
Examining average and discounted reward optimality criteria in reinforcement learning
Jul 03, 2021

In reinforcement learning (RL), the goal is to obtain an optimal policy, for which the optimality criterion is fundamentally important. Two major optimality criteria are average and discounted rewards, where the later is typically considered as an approximation to the former. While the discounted reward is more popular, it is problematic to apply in environments that have no natural notion of discounting. This motivates us to revisit a) the progression of optimality criteria in dynamic programming, b) justification for and complication of an artificial discount factor, and c) benefits of directly maximizing the average reward. Our contributions include a thorough examination of the relationship between average and discounted rewards, as well as a discussion of their pros and cons in RL. We emphasize that average-reward RL methods possess the ingredient and mechanism for developing the general discounting-free optimality criterion (Veinott, 1969) in RL.
A nearly Blackwell-optimal policy gradient method
Jun 04, 2021
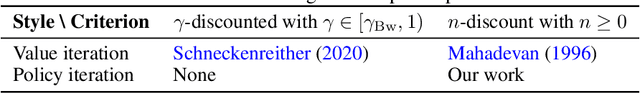

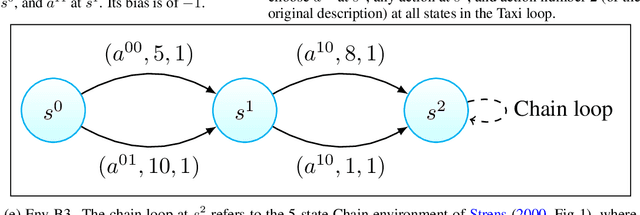
For continuing environments, reinforcement learning methods commonly maximize a discounted reward criterion with discount factor close to 1 in order to approximate the steady-state reward (the gain). However, such a criterion only considers the long-run performance, ignoring the transient behaviour. In this work, we develop a policy gradient method that optimizes the gain, then the bias (which indicates the transient performance and is important to capably select from policies with equal gain). We derive expressions that enable sampling for the gradient of the bias, and its preconditioning Fisher matrix. We further propose an algorithm that solves the corresponding bi-level optimization using a logarithmic barrier. Experimental results provide insights into the fundamental mechanisms of our proposal.
Average-reward model-free reinforcement learning: a systematic review and literature mapping
Oct 18, 2020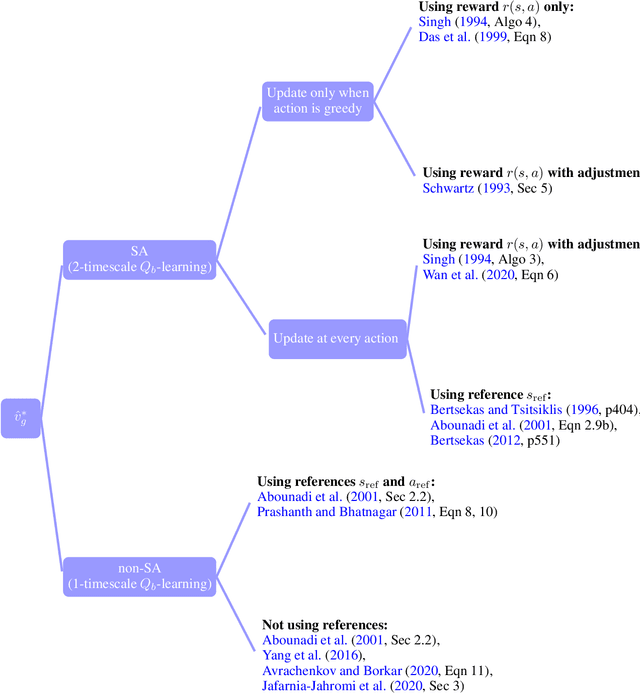

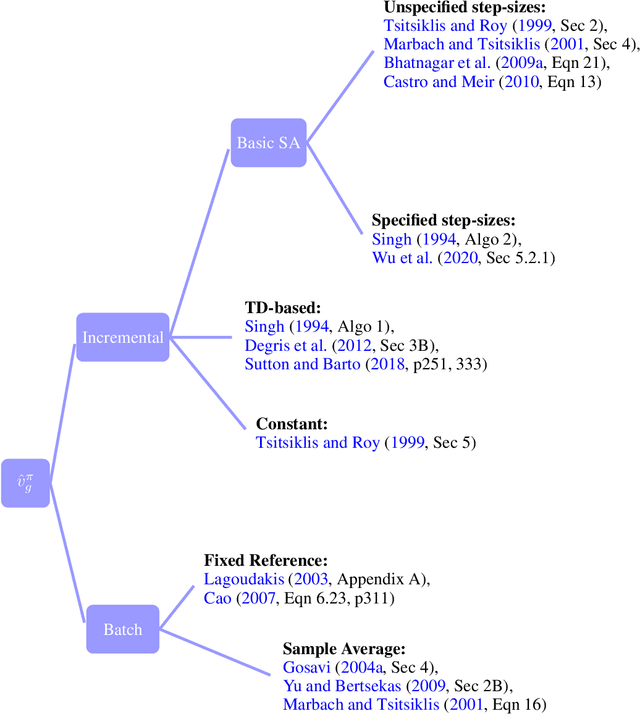
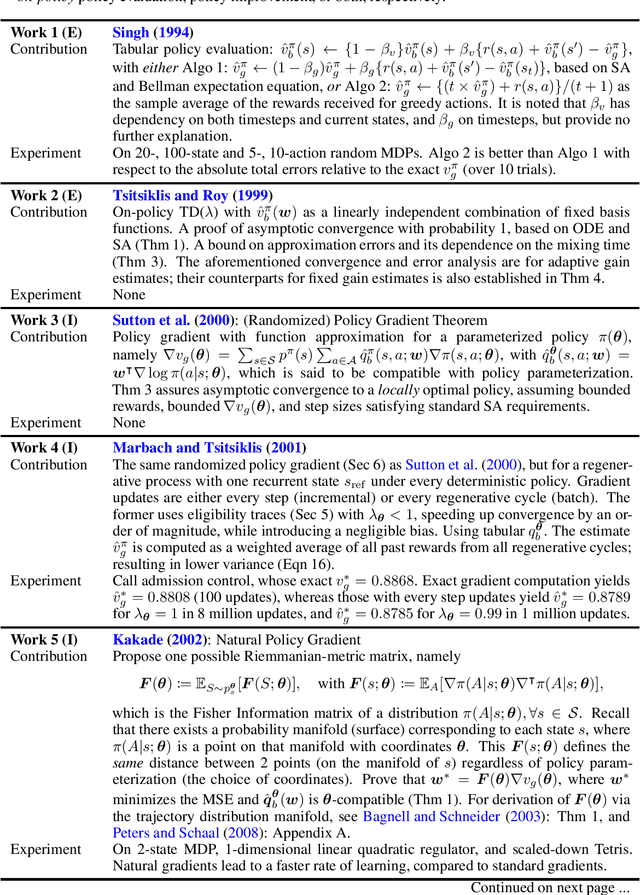
Model-free reinforcement learning (RL) has been an active area of research and provides a fundamental framework for agent-based learning and decision-making in artificial intelligence. In this paper, we review a specific subset of this literature, namely work that utilizes optimization criteria based on average rewards, in the infinite horizon setting. Average reward RL has the advantage of being the most selective criterion in recurrent (ergodic) Markov decision processes. In comparison to widely-used discounted reward criterion, it also requires no discount factor, which is a critical hyperparameter, and properly aligns the optimization and performance metrics. Motivated by the solo survey by Mahadevan (1996a), we provide an updated review of work in this area and extend it to cover policy-iteration and function approximation methods (in addition to the value-iteration and tabular counterparts). We also identify and discuss opportunities for future work.