 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Dynamic Order Picking in Warehouse Operations
Aug 03, 2024



Order picking is a crucial operation in warehouses that significantly impacts overall efficiency and profitability. This study addresses the dynamic order picking problem, a significant concern in modern warehouse management where real-time adaptation to fluctuating order arrivals and efficient picker routing are crucial. Traditional methods, often assuming fixed order sets, fall short in this dynamic environment. We utilize Deep Reinforcement Learning (DRL) as a solution methodology to handle the inherent uncertainties in customer demands. We focus on a single-block warehouse with an autonomous picking device, eliminating human behavioral factors. Our DRL framework enables the dynamic optimization of picker routes, significantly reducing order throughput times, especially under high order arrival rates. Experiments demonstrate a substantial decrease in order throughput time and unfulfilled orders compared to benchmark algorithms. We further investigate integrating a hyperparameter in the reward function that allows for flexible balancing between distance traveled and order completion time. Finally, we demonstrate the robustness of our DRL model for out-of-sample test instances.
Deep Reinforcement Learning for Picker Routing Problem in Warehousing
Feb 05, 2024Order Picker Routing is a critical issue in Warehouse Operations Management. Due to the complexity of the problem and the need for quick solutions, suboptimal algorithms are frequently employed in practice. However, Reinforcement Learning offers an appealing alternative to traditional heuristics, potentially outperforming existing methods in terms of speed and accuracy. We introduce an attention based neural network for modeling picker tours, which is trained using Reinforcement Learning. Our method is evaluated against existing heuristics across a range of problem parameters to demonstrate its efficacy. A key advantage of our proposed method is its ability to offer an option to reduce the perceived complexity of routes.
Average-reward model-free reinforcement learning: a systematic review and literature mapping
Oct 18, 2020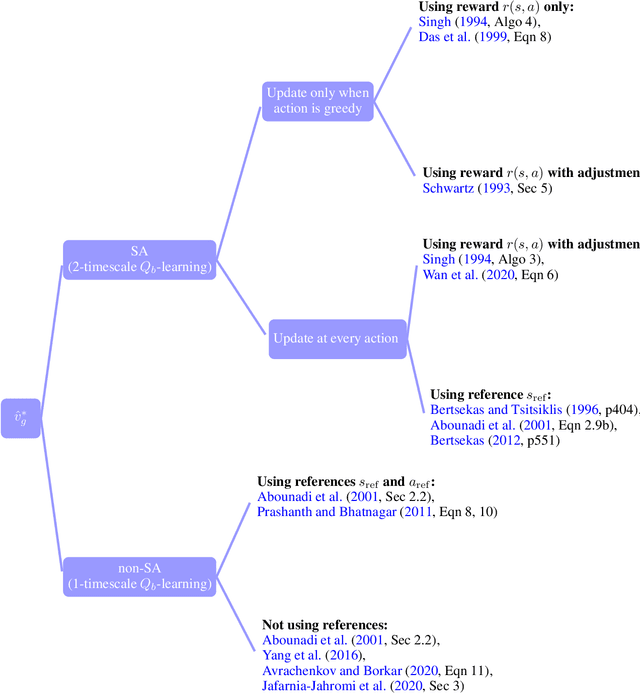

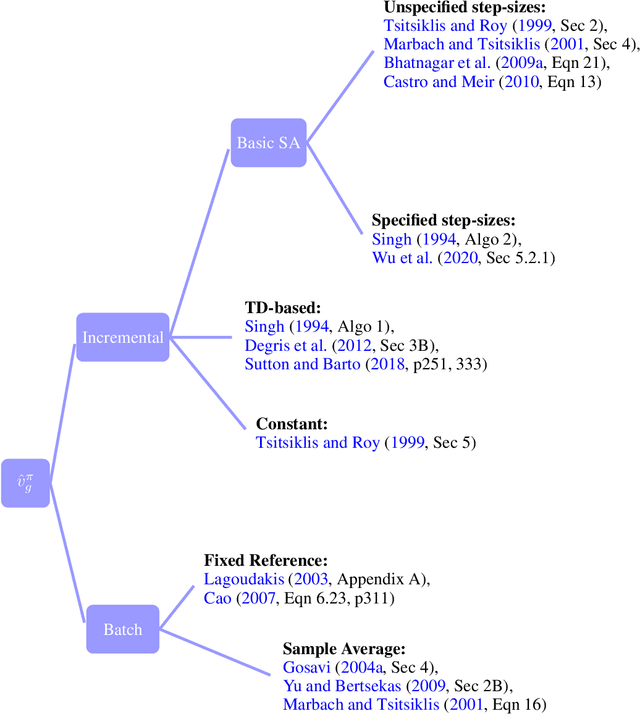
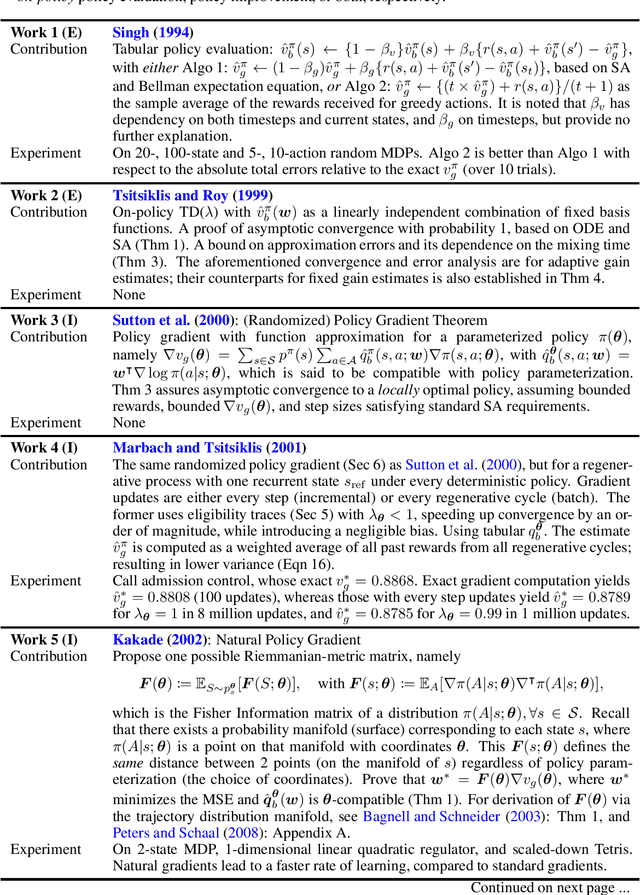
Model-free reinforcement learning (RL) has been an active area of research and provides a fundamental framework for agent-based learning and decision-making in artificial intelligence. In this paper, we review a specific subset of this literature, namely work that utilizes optimization criteria based on average rewards, in the infinite horizon setting. Average reward RL has the advantage of being the most selective criterion in recurrent (ergodic) Markov decision processes. In comparison to widely-used discounted reward criterion, it also requires no discount factor, which is a critical hyperparameter, and properly aligns the optimization and performance metrics. Motivated by the solo survey by Mahadevan (1996a), we provide an updated review of work in this area and extend it to cover policy-iteration and function approximation methods (in addition to the value-iteration and tabular counterparts). We also identify and discuss opportunities for future work.