 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAPT: Model-Predictive Out-of-Distribution Detection and Failure Diagnosis for Sim-to-Real Humanoid Robots
Feb 02, 2026Deploying learned control policies on humanoid robots is challenging: policies that appear robust in simulation can execute confidently in out-of-distribution (OOD) states after Sim-to-Real transfer, leading to silent failures that risk hardware damage. Although anomaly detection can mitigate these failures, prior methods are often incompatible with high-rate control, poorly calibrated at the extremely low false-positive rates required for practical deployment, or operate as black boxes that provide a binary stop signal without explaining why the robot drifted from nominal behavior. We present RAPT, a lightweight, self-supervised deployment-time monitor for 50Hz humanoid control. RAPT learns a probabilistic spatio-temporal manifold of nominal execution from simulation and evaluates execution-time predictive deviation as a calibrated, per-dimension signal. This yields (i) reliable online OOD detection under strict false-positive constraints and (ii) a continuous, interpretable measure of Sim-to-Real mismatch that can be tracked over time to quantify how far deployment has drifted from training. Beyond detection, we introduce an automated post-hoc root-cause analysis pipeline that combines gradient-based temporal saliency derived from RAPT's reconstruction objective with LLM-based reasoning conditioned on saliency and joint kinematics to produce semantic failure diagnoses in a zero-shot setting. We evaluate RAPT on a Unitree G1 humanoid across four complex tasks in simulation and on physical hardware. In large-scale simulation, RAPT improves True Positive Rate (TPR) by 37% over the strongest baseline at a fixed episode-level false positive rate of 0.5%. On real-world deployments, RAPT achieves a 12.5% TPR improvement and provides actionable interpretability, reaching 75% root-cause classification accuracy across 16 real-world failures using only proprioceptive data.
SimTO: A simulation-based topology optimization framework for bespoke soft robotic grippers
Jan 27, 2026Soft robotic grippers are essential for grasping delicate, geometrically complex objects in manufacturing, healthcare and agriculture. However, existing grippers struggle to grasp feature-rich objects with high topological variability, including gears with sharp tooth profiles on automotive assembly lines, corals with fragile protrusions, or vegetables with irregular branching structures like broccoli. Unlike simple geometric primitives such as cubes or spheres, feature-rich objects lack a clear "optimal" contact surface, making them both difficult to grasp and susceptible to damage when grasped by existing gripper designs. Safe handling of such objects therefore requires specialized soft grippers whose morphology is tailored to the object's features. Topology optimization offers a promising approach for producing specialized grippers, but its utility is limited by the requirement for pre-defined load cases. For soft grippers interacting with feature-rich objects, these loads arise from hundreds of unpredictable gripper-object contact forces during grasping and are unknown a priori. To address this problem, we introduce SimTO, a framework that enables high-resolution topology optimization by automatically extracting load cases from a contact-based physics simulator, eliminating the need for manual load specification. Given an arbitrary feature-rich object, SimTO produces highly customized soft grippers with fine-grained morphological features tailored to the object geometry. Numerical results show our designs are not only highly specialized to feature-rich objects, but also generalize to unseen objects.
Scalable Multi-Objective Robot Reinforcement Learning through Gradient Conflict Resolution
Sep 18, 2025Reinforcement Learning (RL) robot controllers usually aggregate many task objectives into one scalar reward. While large-scale proximal policy optimisation (PPO) has enabled impressive results such as robust robot locomotion in the real world, many tasks still require careful reward tuning and are brittle to local optima. Tuning cost and sub-optimality grow with the number of objectives, limiting scalability. Modelling reward vectors and their trade-offs can address these issues; however, multi-objective methods remain underused in RL for robotics because of computational cost and optimisation difficulty. In this work, we investigate the conflict between gradient contributions for each objective that emerge from scalarising the task objectives. In particular, we explicitly address the conflict between task-based rewards and terms that regularise the policy towards realistic behaviour. We propose GCR-PPO, a modification to actor-critic optimisation that decomposes the actor update into objective-wise gradients using a multi-headed critic and resolves conflicts based on the objective priority. Our methodology, GCR-PPO, is evaluated on the well-known IsaacLab manipulation and locomotion benchmarks and additional multi-objective modifications on two related tasks. We show superior scalability compared to parallel PPO (p = 0.04), without significant computational overhead. We also show higher performance with more conflicting tasks. GCR-PPO improves on large-scale PPO with an average improvement of 9.5%, with high-conflict tasks observing a greater improvement. The code is available at https://github.com/humphreymunn/GCR-PPO.
A Standardized Benchmark Set of Clustering Problem Instances for Comparing Black-Box Optimizers
May 14, 2025
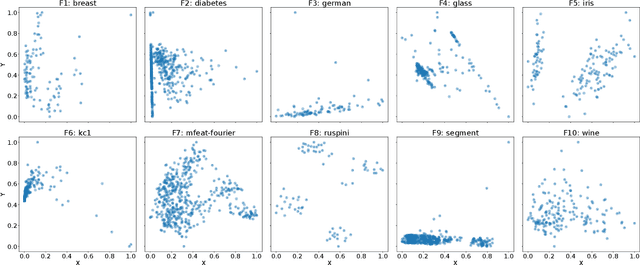

One key challenge in optimization is the selection of a suitable set of benchmark problems. A common goal is to find functions which are representative of a class of real-world optimization problems in order to ensure findings on the benchmarks will translate to relevant problem domains. While some problem characteristics are well-covered by popular benchmarking suites, others are often overlooked. One example of such a problem characteristic is permutation invariance, where the search space consists of a set of symmetrical search regions. This type of problem occurs e.g. when a set of solutions has to be found, but the ordering within this set does not matter. The data clustering problem, often seen in machine learning contexts, is a clear example of such an optimization landscape, and has thus been proposed as a base from which optimization benchmarks can be created. In addition to the symmetry aspect, these clustering problems also contain potential regions of neutrality, which can provide an additional challenge to optimization algorithms. In this paper, we present a standardized benchmark suite for the evaluation of continuous black-box optimization algorithms, based on data clustering problems. To gain insight into the diversity of the benchmark set, both internally and in comparison to existing suites, we perform a benchmarking study of a set of modular CMA-ES configurations, as well as an analysis using exploratory landscape analysis. Our benchmark set is open-source and integrated with the IOHprofiler benchmarking framework to encourage its use in future research.
Hyperparameter Optimisation with Practical Interpretability and Explanation Methods in Probabilistic Curriculum Learning
Apr 09, 2025Hyperparameter optimisation (HPO) is crucial for achieving strong performance in reinforcement learning (RL), as RL algorithms are inherently sensitive to hyperparameter settings. Probabilistic Curriculum Learning (PCL) is a curriculum learning strategy designed to improve RL performance by structuring the agent's learning process, yet effective hyperparameter tuning remains challenging and computationally demanding. In this paper, we provide an empirical analysis of hyperparameter interactions and their effects on the performance of a PCL algorithm within standard RL tasks, including point-maze navigation and DC motor control. Using the AlgOS framework integrated with Optuna's Tree-Structured Parzen Estimator (TPE), we present strategies to refine hyperparameter search spaces, enhancing optimisation efficiency. Additionally, we introduce a novel SHAP-based interpretability approach tailored specifically for analysing hyperparameter impacts, offering clear insights into how individual hyperparameters and their interactions influence RL performance. Our work contributes practical guidelines and interpretability tools that significantly improve the effectiveness and computational feasibility of hyperparameter optimisation in reinforcement learning.
AlgOS: Algorithm Operating System
Apr 07, 2025



Algorithm Operating System (AlgOS) is an unopinionated, extensible, modular framework for algorithmic implementations. AlgOS offers numerous features: integration with Optuna for automated hyperparameter tuning; automated argument parsing for generic command-line interfaces; automated registration of new classes; and a centralised database for logging experiments and studies. These features are designed to reduce the overhead of implementing new algorithms and to standardise the comparison of algorithms. The standardisation of algorithmic implementations is crucial for reproducibility and reliability in research. AlgOS combines Abstract Syntax Trees with a novel implementation of the Observer pattern to control the logical flow of algorithmic segments.
Probabilistic Curriculum Learning for Goal-Based Reinforcement Learning
Apr 02, 2025



Reinforcement learning (RL) -- algorithms that teach artificial agents to interact with environments by maximising reward signals -- has achieved significant success in recent years. These successes have been facilitated by advances in algorithms (e.g., deep Q-learning, deep deterministic policy gradients, proximal policy optimisation, trust region policy optimisation, and soft actor-critic) and specialised computational resources such as GPUs and TPUs. One promising research direction involves introducing goals to allow multimodal policies, commonly through hierarchical or curriculum reinforcement learning. These methods systematically decompose complex behaviours into simpler sub-tasks, analogous to how humans progressively learn skills (e.g. we learn to run before we walk, or we learn arithmetic before calculus). However, fully automating goal creation remains an open challenge. We present a novel probabilistic curriculum learning algorithm to suggest goals for reinforcement learning agents in continuous control and navigation tasks.
Whole-Body Dynamic Throwing with Legged Manipulators
Oct 08, 2024



Most robotic behaviours focus on either manipulation or locomotion, where tasks that require the integration of both, such as full-body throwing, remain under-explored. Throwing with a robot involves complex coordination between object manipulation and legged locomotion, which is crucial for advanced real-world interactions. This work investigates the challenge of full-body throwing in robotic systems and highlights the advantages of utilising the robot's entire body. We propose a deep reinforcement learning (RL) approach that leverages the robot's body to enhance throwing performance through a strategically designed curriculum to avoid local optima and sparse but informative reward functions to improve policy flexibility. The robot's body learns to generate additional momentum and fine-tune the projectile release velocity. Our full-body method achieves on average 47% greater throwing distance and 34% greater throwing accuracy than the arm alone, across two robot morphologies - an armed quadruped and a humanoid. We also extend our method to optimise robot stability during throws. The learned policy effectively generalises throwing to targets at any 3D point in space within a specified range, which has not previously been achieved and does so with human-level throwing accuracy. We successfully transferred this approach from simulation to a real robot using sim2real techniques, demonstrating its practical viability.
Analyzing the Runtime of the Gene-pool Optimal Mixing Evolutionary Algorithm (GOMEA) on the Concatenated Trap Function
Jul 11, 2024



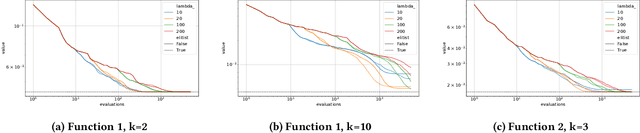
The Gene-pool Optimal Mixing Evolutionary Algorithm (GOMEA) is a state of the art evolutionary algorithm that leverages linkage learning to efficiently exploit problem structure. By identifying and preserving important building blocks during variation, GOMEA has shown promising performance on various optimization problems. In this paper, we provide the first runtime analysis of GOMEA on the concatenated trap function, a challenging benchmark problem that consists of multiple deceptive subfunctions. We derived an upper bound on the expected runtime of GOMEA with a truthful linkage model, showing that it can solve the problem in $O(m^{3}2^k)$ with high probability, where $m$ is the number of subfunctions and $k$ is the subfunction length. This is a significant speedup compared to the (1+1) EA, which requires $O(ln{(m)}(mk)^{k})$ expected evaluations.
Modularity based linkage model for neuroevolution
Jun 02, 2023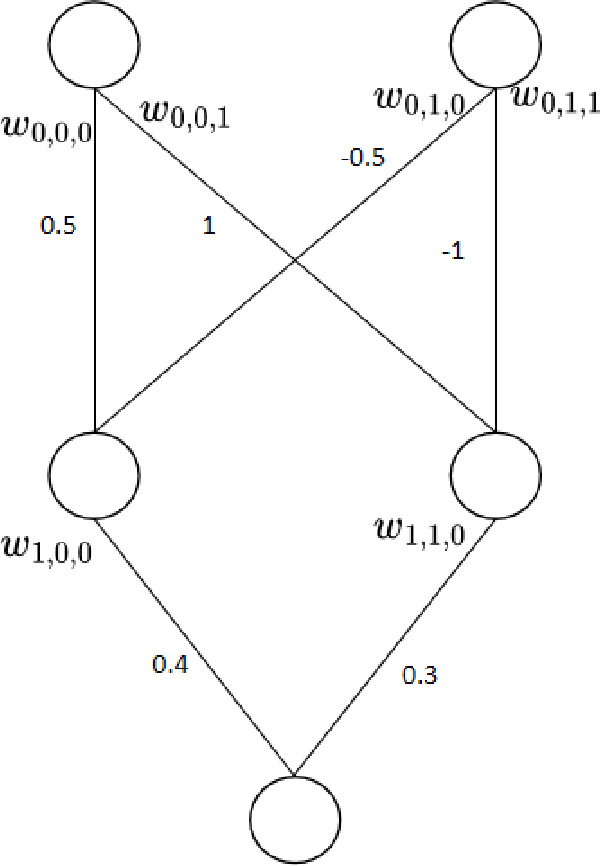
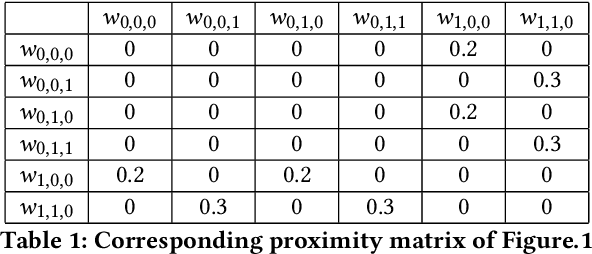
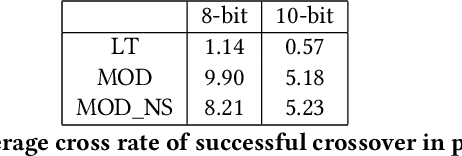
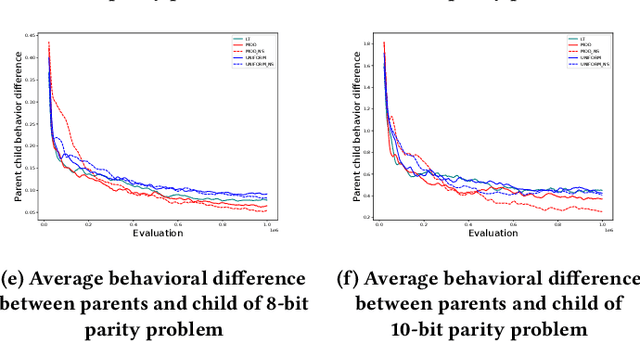
Crossover between neural networks is considered disruptive due to the strong functional dependency between connection weights. We propose a modularity-based linkage model at the weight level to preserve functionally dependent communities (building blocks) in neural networks during mixing. A proximity matrix is built by estimating the dependency between weights, then a community detection algorithm maximizing modularity is run on the graph described by such matrix. The resulting communities/groups of parameters are considered to be mutually independent and used as crossover masks in an optimal mixing EA. A variant is tested with an operator that neutralizes the permutation problem of neural networks to a degree. Experiments were performed on 8 and 10-bit parity problems as the intrinsic hierarchical nature of the dependencies in these problems are challenging to learn. The results show that our algorithm finds better, more functionally dependent linkage which leads to more successful crossover and better performance.